[Agent part 3] Interleaved Thinking 呈現的穩定性是現在Agent落地的重要關鍵
![[Agent part 3] Interleaved Thinking 呈現的穩定性是現在Agent落地的重要關鍵](/assets/images/interleaved-thinking-cover.png "[Agent part 3] Interleaved Thinking 呈現的穩定性是現在Agent落地的重要關鍵")
大家都知道我用 AI 來 enable 很多intern 來當作很多正職的事情,當然他們雖然都很年輕跟熱情,但是我管理團隊時發現一個規律:
有 Sr 的經驗,跟有 Jr 熱情的 Data&AI; Team
當我派給幾個 Senior 的同事 ,我通常只需要 weekly 跟他開會,給他幾個任務,一週後檢查一次就好。他可以獨立工作,中間遇到問題會自己判斷、調整,如果有大問題他們會舉手跟我講,不容易走偏。
當我要安排工作給我的 intern ,跟 Senior 最大的不同就是, Junior 我通常會每半天或是每過一天就會跟他聊一下提醒一下可能要注意什么事情。因為他很容易遇到了某些複雜任務時,他就可能在某一步卡住,又沒有舉手,基於錯誤理解繼續做下去,最後整個方向偏了,也浪費了他整天的時間。
這是Sr 跟 Jr 經驗的差別,獨立作戰的能力
AI Agent 也是如此
現在考驗 AI Agent 最大的地方,不是他的智商,主要著重點是它的連續工作穩定性。如果人類需要介入的越少,就代表它可以自主完成工作,不需要人打擾,生產力就會釋放出來。
在 Agent 界有一個很重要的考核指標叫做 METR。Claude 3.7 Sonnet 2025 初METR 可以獨立工作約 1小時,之後就需要人類確認方向。2025 年五月 Opus 已經可以到 7小時,到了 2025 年 9 月,Claude Sonnet 4.5 已經可以持續專注工作超過 30 小時,無需人工干預自主構建完整的聊天應用,生成 11,000 行代碼。
為什麼進步這麼快?關鍵就是 Claude 4.5 加入了 interleaved thinking(交錯思考)這樣的機制——讓 Agent 像 Senior PM一樣,每一步都自我驗證、發現問題立即調整、遇到大問題主動舉手。當這種 Agent 獨立作業的能力到臨界值,Agent 就可以像 Sr PM 一樣,在半夜或是不需要介入的情況下,直接做事,等早上人類起床驗收。
Interleaved Thinking
傳統的 Agent 架構(如 ReAct 和 Plan & Execute)有個共同做法:思考和執行是分離的,Interleaved Thinking 不一樣, 它讓「思考」貫穿整個執行過程——不只是在工具調用之間思考,而是在每個行動的前、中、後都持續思考。規劃與行動交錯進行
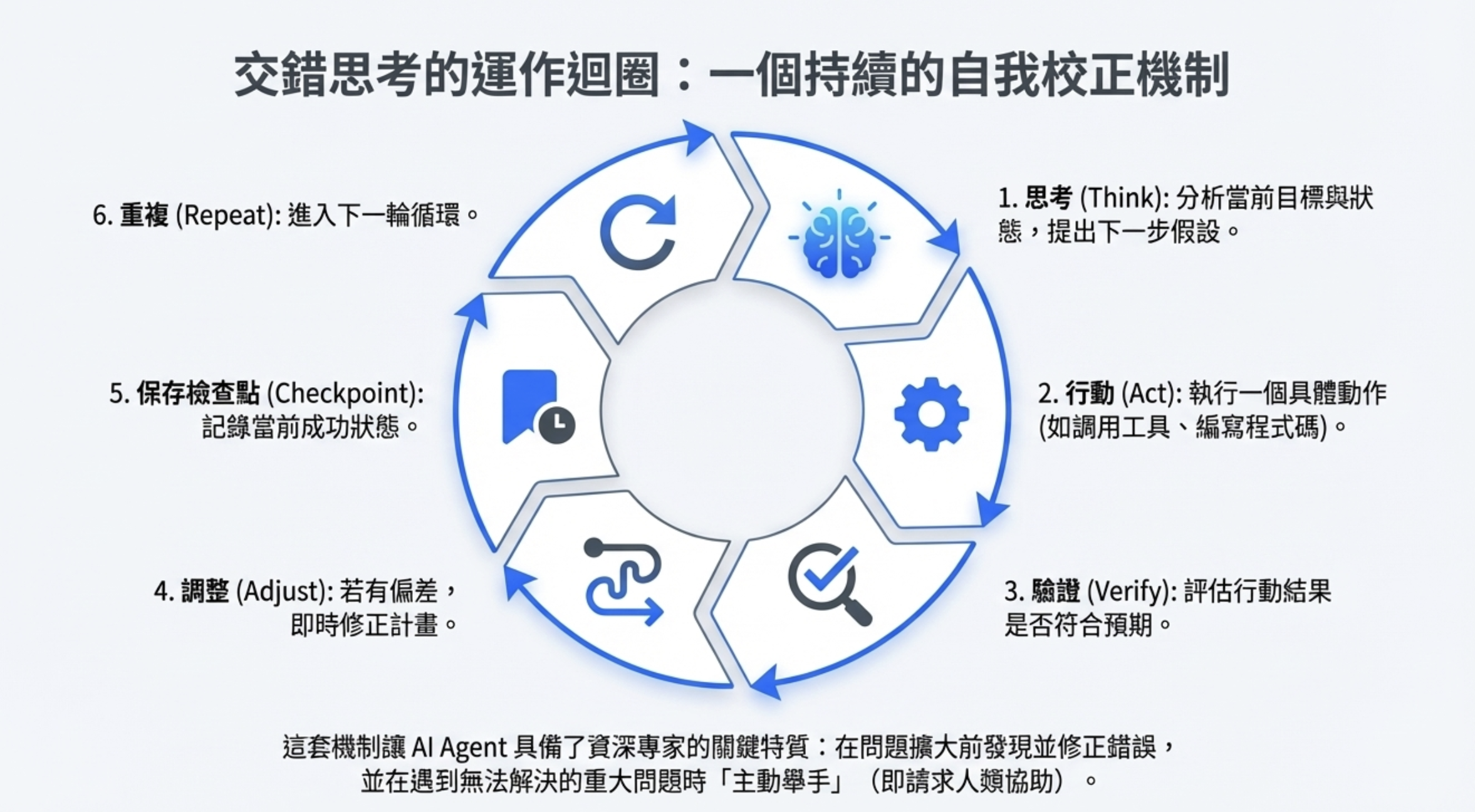
具體來說: 思考 → 行動 → 驗證 → 調整 → 保存檢查點 → 重複
這就像不是「做完再想」,而是「邊做邊想邊驗證」。實作來說
Plan & Exec 只要支援一次呼叫(像
run_agent()),
Interleaved Thinking 需要支援「連續多次 API 呼叫 + 狀態回饋」
從實作上,Interleaved Thinking 通常需要一個 中控 loop 來管理「思考 ↔ 行動 ↔ 反思」的循環:
所以系統要能:
- 暫存中間狀態(memory / context buffer)
- 動態更新 prompt(inject observation)
- 控制 reasoning token 數量(防止爆 token)
從實作來說,API 也需要實作以下的相關功能
| 類別 | 說明 | 範例 |
|---|---|---|
| Streaming 回饋 | 模型思考時能即時輸出 reasoning 片段 | response_format: reasoning 或 logprobs |
| 函式調用回饋 (function / tool calls) | 每步能呼叫外部工具並根據回傳再思考下一步 | tool_calls in OpenAI API, functions in Anthropic |
| 狀態持續化 (state persistence) | 每輪能記住目前任務進度 | e.g. Session-based API (session_id) |
| 思考可見化 (visible reasoning) | 可開啟「思考區塊」,幫助debug | e.g. o1-preview 模式輸出有 “reasoning trace” |
有支援的 Model
- Claude 4 系列開始支援「interleaved thinking」
- OpenAI Responses API : GPT-4.1 , o3, o4 , O1, 若系統希望達成真正「邊思邊做」(即 interleaved thinking:思考 → 工具/行動 → 再思考 → 下一步)流程,除了模型/API 支援之外,還需要在系統端設計一個 迴圈 (loop) :監控工具調用結果、更新上下文、觸發下一輪思考。
- Gemini : 2.5 支援「thinking 模式」,但 是否真正支援完整的「interleaved thinking」(邊做邊思考/思考 ↔ 行動 交錯) 尚未完全被官方標示。
Interleaved thinking 好處
- 穩定度提升 :由於在每個步驟之間都有反饋與再思考機制,模型能即時修正推理軌跡,顯著降低多步錯誤累積。
- 推理深度增加 :模型學會「先驗假設—驗證—修正」循環,而非線性生成;使在數學、邏輯、編程等任務中更接近人類思考。
- 速度與效率並進 :Interleaved Thinking 透過部分並行思考與中途決策更新,使平均回覆時間更短、token 消耗更少。
基本上讓模型在多步推理任務中更穩、更快、更準,提升幅度平均約 20–30 %,錯誤率下降 35 %以上,已成為下一代 Reasoning Model 的核心趨勢
Interleaved Thinking 缺點
- 成本與效率 : Token 消耗增加 15-30%: 每一步都要思考、验证、调整, 執行時間變長: 需要 5-10 次 API 調用,而非一次性完成
- 技術實作複雜度高: 需要設計中控 loop 管理狀態, 需要暫存中間狀態: memory / context buffer 管理困難, 錯誤處理複雜: 需要處理迴圈中每一步的失敗情況
- 無法控制行為問題:容易陷入過度思考迴圈: 反覆驗證同一結果,無限循環, 另外需要設定終止條件: 最大迭代次數、收斂條件等
- 模型要求要求高: 需要準確判斷、找備選方案、知道何時求助。如果硬要用舊模型表現差,反而降低成功率
- 適用性限制: 簡單任務不划算, 不適合即時應用: 聊天機器人、客服系統等需要快速回應的場景,也不適合高度可控場景: 金融交易、醫療決策等需要明確可預測的流程
總結
Interleaved Thinking 讓 AI Agent 的連續穩定工作時間大增,這是 AI Agent 整合進去企業端的關鍵指標。但代價是 token 消耗增加 15-30%、執行時間變長、對模型要求複雜度高,適合複雜多步驟任務,但對簡單任務或即時應用來說不划算。
一句話:選對場景,才能發揮最大價值。