AI Agent 可解釋性:從資安合規到營運信任的關鍵工程設計

試想一下你的工作現場:
如果有一位同事,做決策從不說明、執行過程完全不透明,當你問他「為什麼這樣做」,卻得不到任何解釋——你還會願意把關鍵任務交給他嗎?
多半不會。
但弔詭的是,我們卻願意把同樣等級的決策權,交給一個無法解釋自身行為的 AI Agent。
可解釋性的誤區
我們一直被要求「可解釋性」是因為資安、GDPR、或是 AI 法規。
但其實在維運層面,我們更需要 Agent 可解釋性。
AI Agent 的本質不是靜態模型,而是一個會持續查資料、呼叫工具、改變行為、影響業務結果的系統。當系統開始介入營運流程,你關心的就不再只是「準確率」,而是:
- 為什麼它這樣判斷?
- 為什麼不用指定的資料來源?
- 為什麼跳過某一個步驟?
如果這些問題無法被回答,就不會有信任,更不可能放權。
這也是為什麼我一直強調:
可解釋性不只是資安 Model Safety,而是營運信任。
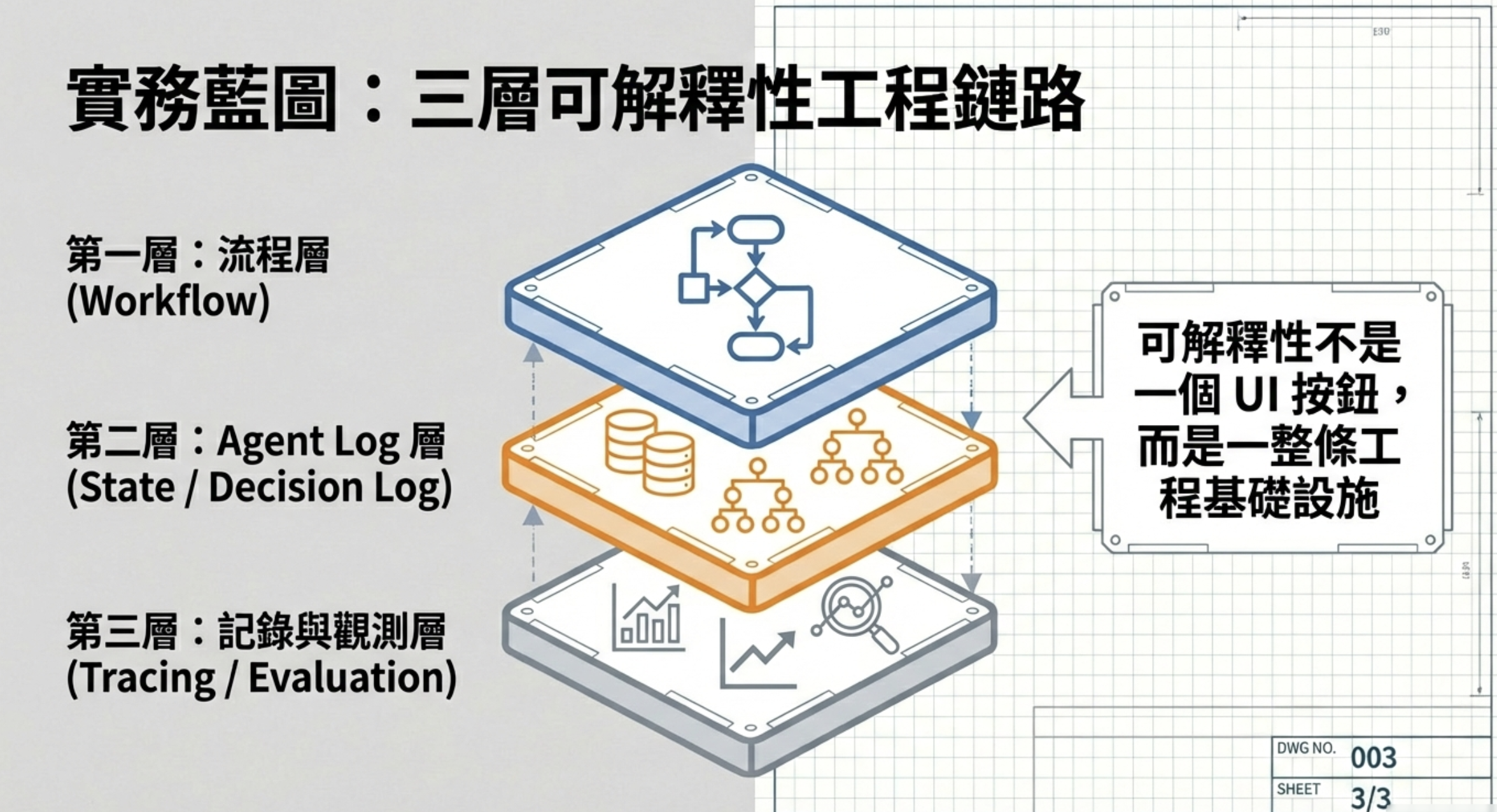
可解釋性必須是工程鏈路
這件事,不是一個 UI 可以解決的。
在實務上,可解釋性必須是一整條工程鏈路,至少包含三個責任邊界清楚的層次。
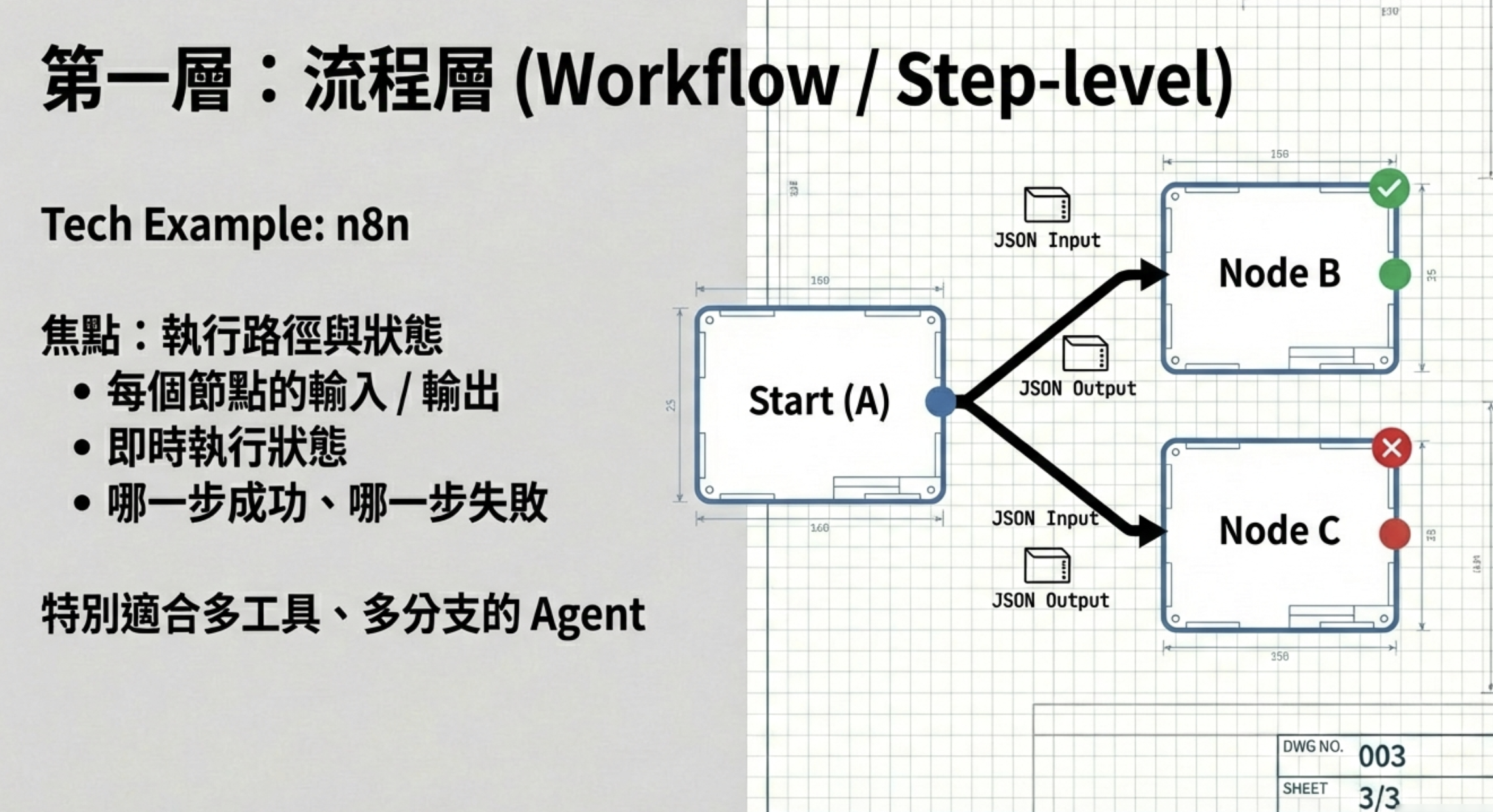
第一層:流程可解釋性
你需要能看清楚「事情是怎麼被執行的」:每一步的輸入與輸出、即時狀態、成功與失敗的分支路徑。
這一層解決的是:Agent 做了什麼。
具體來說,你要能回答這些問題:這個任務總共跑了幾個步驟?每一步呼叫了哪個工具?輸入是什麼、輸出是什麼?哪一步失敗了、失敗的原因是什麼?這些資訊必須是即時可查的,而不是事後去翻 log 才能拼湊出來。
工具面上,可以用 Agent Framework 來記錄(例如 N8N 的 execution log)。這類工具的好處是,流程本身就是視覺化的 DAG,每個節點的執行狀態、耗時、錯誤訊息都一目瞭然。對於營運團隊來說,這是最直覺的「發生了什麼事」的答案。
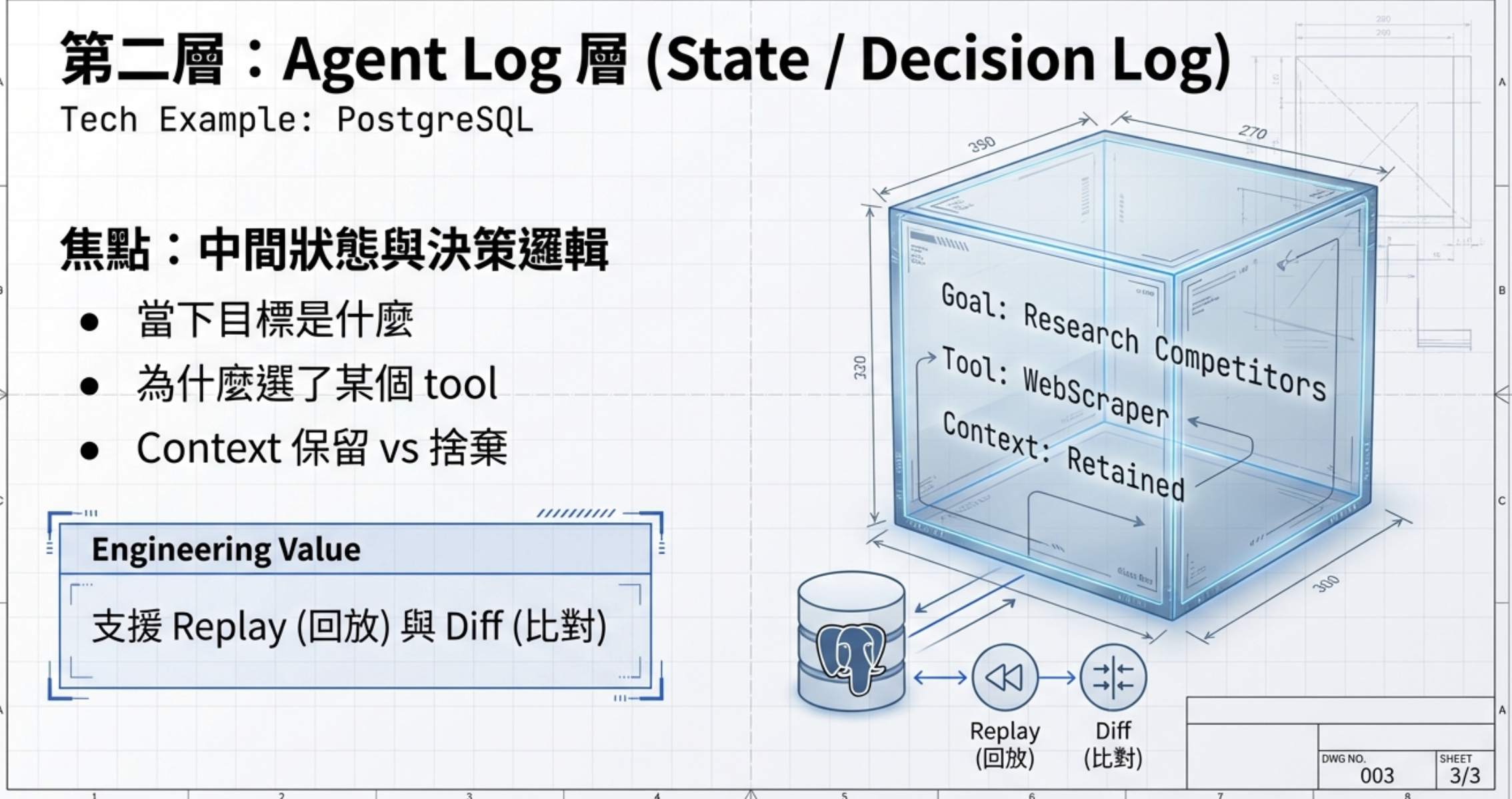
第二層:決策可解釋性
真正困難的不是流程,而是 Agent 為什麼這樣想。
你必須把中間狀態寫成結構化紀錄:當下目標、選擇工具的理由、哪些 RAG context 被採用或捨棄。
這不是 debug log,而是可回放、可比對、可治理的決策歷史。
這一層解決的是:Agent 為什麼這樣做。
舉個例子:Agent 收到一個客戶查詢,它決定先查 CRM 再查知識庫,最後生成回覆。第一層只會告訴你「查了 CRM、查了知識庫」,但第二層要回答的是:為什麼先查 CRM?為什麼知識庫回傳了 5 筆資料,Agent 只採用了 2 筆?被捨棄的 3 筆是什麼理由?這些決策邏輯如果沒有被記錄下來,當結果出錯時,你根本無從追溯問題出在哪裡。
工具面上,這是 Langfuse 的範疇。它可以記錄每一次 LLM 呼叫的 prompt、completion、token 用量,更重要的是可以把多次呼叫串成一條完整的 trace,讓你看到 Agent 的思考脈絡。
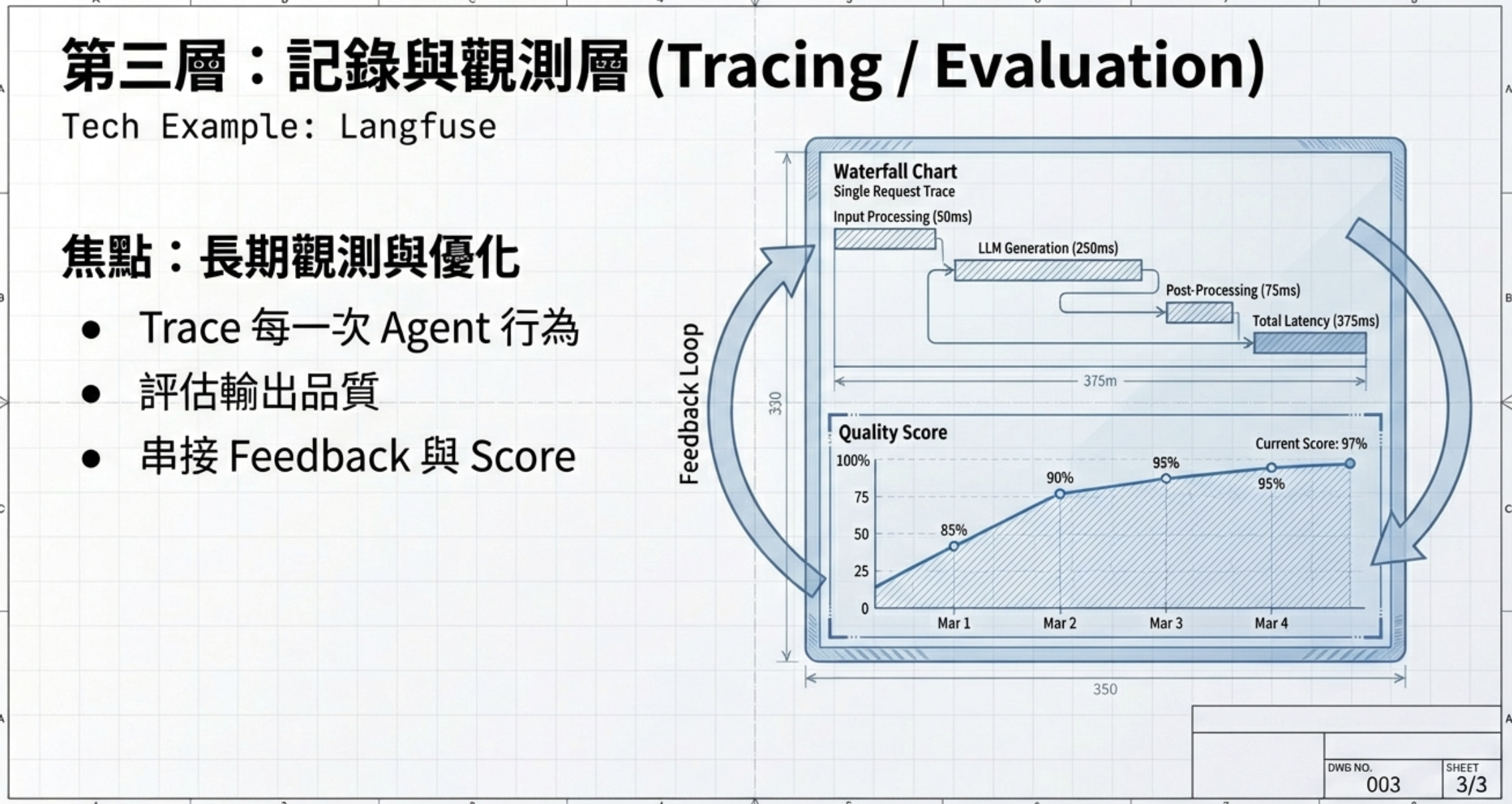
第三層:長期記錄與觀測
這一層的目的,不是理解一次決策,而是長期回答:
- 這個 Agent 是否穩定?
- 是否持續變好?
- 值不值得被信任?
透過 trace、品質評分與回饋迴圈,把可解釋性升級為持續優化與治理能力。
這一層要回答的問題是時間軸上的:過去一個月,這個 Agent 的成功率是上升還是下降?哪些類型的任務失敗率特別高?使用者的滿意度有沒有提升?成本是否在可控範圍內?這些問題需要把前兩層的資料彙整起來,做長期趨勢分析。沒有這一層,你就無法判斷一個 Agent 是「剛好這次成功」還是「持續可靠」。
工具面上,是傳統 BI 範疇。你可以把 Langfuse 的資料匯出到 Data Warehouse,用 Metabase 或 Looker 做 dashboard,追蹤 KPI 如成功率、平均回應時間、token 成本、使用者回饋分數等。這些指標才是營運團隊決定「要不要繼續用這個 Agent」的依據。
結論
最後我想留一句工程師才會在意的結論:
可解釋性不只是為了資安,而是 AI 獲得營運團隊的信任門票。
而人的信任,這是 Agent 落地的關鍵。