AI Agent Security:為什麼它正在改變企業資安架構(不是你想的 Prompt 問題)
目錄
- 什麼是 AI Agent(以及它跟 Chatbot 的根本差異)
- 真實案例:Enterprise AI Agent 如何被攻破
- 數據說話:AI Agent Security 的研究數據
- 遊戲規則已經改變:Security Architecture 必須重構
- 傳統安全工具的盲點:為什麼 WAF/APM 失效
- 坦白說:AI Agent Security 比想像中難
- 為什麼 AI Guardrails 擋不住?
- 參考資料
- 延伸閱讀
上週五,我在香港迪士尼酒店 玩得很開心 跟AWS/ECV/Palo Alto/Fortinet一眾資安大神,一起分享AI資訊安全技術演講,分享了在大 Agent 時代的資安威脅,跟許多同業跟客戶交流,聽到一些有趣的故事。
但在講案例之前,我想先釐清一個關鍵問題——很多人還搞不清楚 AI Agent 到底是什麼。
什麼是 AI Agent(以及它跟 Chatbot 的根本差異)
AI Agent Security 的第一步,是搞清楚 AI Agent 到底是什麼。先講清楚一件事:AI Agent 不是「比較聰明的 Chatbot」,它們是完全不同的物種。
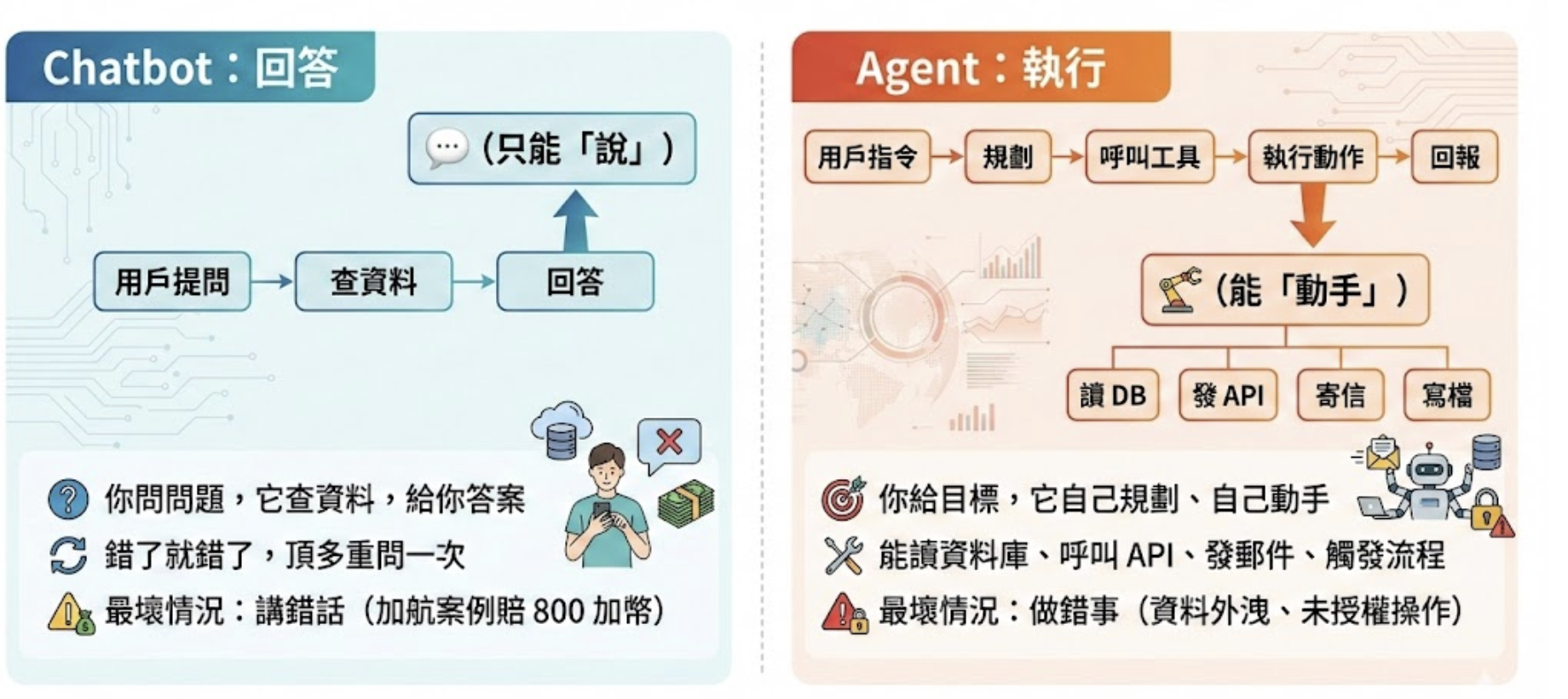
為什麼「能動手」= 資安風險倍增?
因為攻擊目標變了。
Chatbot 時代,攻擊者想「騙它說錯話」。Agent 時代,攻擊者想「騙它做錯事」。
一旦 Agent 有了執行權限,它能存取的每個資料源、能呼叫的每個 API,都是潛在攻擊面。
這不是理論——接下來兩個案例,是 2025 年已經發生的真實攻擊。
真實案例:Enterprise AI Agent 如何被攻破
Enterprise AI Agent 的資安風險不是理論,以下是 2024-2025 年已經發生的攻擊事件。
👉 完整案例分析請見:AI Agent 攻擊案例全集:4 個真實事件告訴你企業 AI 怎麼被攻破
一張表看懂:4 個案例到底在證明什麼
| 案例 | 攻擊入口 | Agent 被迫做的事 | 真正外洩/破壞的通道 | 為什麼 WAF/APM 看不到 |
|---|---|---|---|---|
| Salesforce ForcedLeak | 公開表單欄位(Web-to-Lead) | 匯出 CRM 聯絡人 | 正常的內部流程把資料送走 | HTTP 200、流程正常、無錯誤 |
| Microsoft 365 Copilot EchoLeak | 郵件隱藏文字(零點擊) | 讀 SharePoint / 摘要敏感資料並編碼 | 以「載入圖片」的 HTTPS request 外送 | 看起來只是載入圖片/正常 CDN 流量 |
| ChatGPT Plugins | 網頁嵌入隱藏指令 | 讀取並執行惡意指令 | 透過插件 API 外送帳號資料 | 正常的瀏覽請求 |
| ServiceNow Now Assist | Agent 間傳遞的指令 | 跨 Agent 權限提升 | 透過信任鏈取得高權限資料 | 每個單獨請求都合法 |
案例重點摘要
1) ForcedLeak(CVSS 9.4):填一張表單,就等 AI 幫你把 CRM 客戶名單送出去
攻擊不需要入侵系統,只要把「隱藏指令」塞進表單欄位。等企業內部 Agent 讀到它,就用自己的權限把資料外傳。系統日誌看起來一切正常:200 OK、無錯誤、無告警。
2) EchoLeak(CVE-2025-32711, CVSS 9.3):你沒點任何東西,但資料照樣被外送(零點擊)
攻擊者把指令藏在郵件不可見文字,Copilot 先「理解」再「執行」。把敏感摘要塞進圖片 URL,形成看似正常的圖片請求。你看到的是圖片,對方拿到的是財務資料。
3) ChatGPT Plugins:網頁就是武器
攻擊者在公開網頁中嵌入隱藏指令。使用者要求 AI「總結這個網頁」,AI 讀取內容時被劫持,將帳號資料外送到攻擊者端點。
4) ServiceNow Now Assist:100% 多 Agent 攻擊成功率
沒有任何一個 Agent 單獨違規。攻擊存在於「跨 Agent 行為的組合」。看似合理的權限劃分,共同構成了一個致命的攻擊鏈。
核心問題
這四個案例揭露了同一個本質:
當 Agent 有了「讀取權限」+ 「主動行為能力」,它就成了潛在的資料外洩通道。
不需要駭進系統、不需要竊取密碼、不需要用戶點擊連結。只需要一個精心設計的 prompt,等 AI 自己把資料送出去。
這讓我開始思考一個問題:我們是不是還在用 Chatbot 時代的安全思維,來處理 Agent 時代的風險?
數據說話:AI Agent Security 的研究數據
AI Agent Security 不是危言聳聽,在往下討論之前,先看幾個學術研究的數字。
學術研究與 OWASP:Agent 攻擊成功率高達 94.4%
根據 2025 年 10 月發表的研究論文《Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges》(arXiv:2510.23883),研究人員發現:
94.4% 的 SOTA(最先進)LLM Agent 容易受到 Prompt Injection 攻擊。
100% 的 Agent 在「多 Agent 互信(Inter-agent trust)」場景下被成功攻破。
你沒看錯——在多個 Agent 協作的場景,攻擊成功率是 100%。如果你的架構是「Agent A 呼叫 Agent B 來完成任務」,攻擊者只要滲透其中一個 Agent,就能透過信任鏈攻破整個系統。另一篇發表在 ACL 2025 的研究《Indirect Prompt Injection attacks on LLM-based Autonomous Web Navigation Agents》則證明:攻擊者可以在網頁 HTML 中隱藏惡意指令,當 Agent 瀏覽該頁面時會被強制執行惡意操作。Agent 以為自己在「瀏覽網頁」,實際上在「執行攻擊者的指令」。
這不是我在危言聳聽——資安業界權威 OWASP 在《Top 10 for LLM Applications》中,已將 LLM08: Excessive Agency(過度代理) 列為核心風險:「當 LLM 被賦予了過多的功能、權限或自主權時,它可能在非預期的狀況下執行破壞性操作。」風險來源已經從「Prompt Injection(騙它說話)」轉移到「Excessive Functionality(讓它執行 Function Call)」。
作為對比:Chatbot 的「最壞情況」
說到這裡,可能有人會問:「Chatbot 不也有問題嗎?」
對,但 Chatbot 的問題是可控的。
2024 年 2 月,加拿大法院判決了一個經典案例(Moffatt v. Air Canada, 2024 BCCRT 149):
加拿大航空的 Chatbot 虛構了退款政策,告訴乘客可以在親人去世後申請機票退款——但這個政策根本不存在。法院判決航空公司必須對 Chatbot 的言論負責,賠償乘客約 800 加幣。800 加幣。這是 Chatbot「封閉迴路」最壞情況的代價——財務損失,但可控、可賠償、有上限。如果是上市櫃公司,有名譽損失,或是可能法務風險。
但如果這是一個有資料庫存取權的 Agent 呢?
它不是告訴你錯誤的政策,而是直接幫你執行錯誤的退款、刪除錯誤的紀錄、或把財務資料寄給錯誤的收件人。這個代價,可能就不是 800 加幣可以解決的了。
遊戲規則已經改變:Security Architecture 必須重構
AI Agent 改變了整個 Security Architecture 的基本假設。從「對話」到「執行」,風險模型完全不同。
過去 Chatbot 時代(封閉迴路)
- 功能定位: 簡單問答(Q&A)
- 操作範圍: 僅限對話,無系統存取權
- 風險等級: 低 — 最壞情況是回答錯誤
- 角色本質: 純粹的使用者介面(UI)
- 失敗後果: 用戶體驗不佳,財務賠償(如加航案例的 800 加幣)
典型場景:
- 客服機器人回答「營業時間是幾點?」
- FAQ 查詢、資訊導覽
- 錯誤回答頂多讓用戶不滿,重問一次就好
現在 AI Agent 時代(開放迴路)
- 功能定位: 自主任務執行(Autonomous Task Execution)
- 操作範圍: 高度整合 — 讀取 DB、呼叫 API、觸發 Lambda、操作雲端資源
- 風險等級: 高 — 可造成真實系統變更(94.4% 攻擊成功率)
- 角色本質: 有代理權的操作系統(Operational System with Agency)
- 失敗後果: 資料外洩、未授權操作、財務損失、合規違規(台灣已於 2025/12 通過《人工智慧基本法》,明確要求 AI 系統的可問責性與透明性)
為什麼 Guardrails 擋不住 AI Agent 攻擊?
很多資安大神看完上面的案例會問:「那加 Guardrails 不就好了?」
答案是:Guardrails 本質上沒用。 這不是我說的——這是 HackAPrompt CEO Sander Schulhoff 在與 OpenAI、Google DeepMind、Anthropic 聯合研究後的結論。他組織了全球最大的 AI 紅隊競賽,收集超過 60 萬個攻擊 prompt,研究結果被所有前沿 AI 實驗室引用。結論是:人類攻擊者在 10-30 次嘗試內,100% 突破所有現有防禦。
核心問題在於:Guardrails 是 stateless,攻擊是 stateful。 安全護欄只檢查單次請求,但攻擊者會將意圖拆散到多個合法請求中。讀取郵件(合法)+ 轉寄郵件(合法)= 資料外洩(非法結果)。傳統 WAF 看到的是 HTTP 200 OK、正常回應時間、無錯誤訊息——但實際上資料已經外洩。這就是為什麼 APM/WAF 對 AI Agent 完全失效:它們不理解自然語言,無法判斷「這句話想讓 AI 做什麼」,更無法把「用戶說的話」和「資料庫查詢」關聯起來。
「你可以修補程式錯誤(Bug),但你無法修補大腦(Brain)。」— Sander Schulhoff
根據 Gartner 預測,到 2028 年 33% 的企業軟體將包含 Agentic AI(相比 2024 年的 <1%,超過 33 倍成長)。我們的資安武器還沒 Ready,卻正在以 33 倍的速度部署 AI Agent。
Potential 解法:從邊界防禦到架構性圍堵
既然 Guardrails 擋不住,那能做什麼?根據 Schulhoff 與 Google DeepMind 的研究,目前最可行的兩個方向:
-
Least Privilege for AI Agents(最小權限原則): AI 能存取的任何資料,都等同於使用者能存取;AI 能執行的任何動作序列,使用者都能觸發。透過 RLS(資料列級權限)、Network Boundary(網路隔離)、Auth Gateway(入口權限限制),把 Agent 的能力範圍縮到最小。
-
CaMeL 框架(基於意圖的主動約束): Google DeepMind 2025 年發表的 CaMeL 框架——在執行任務前,根據使用者的初始提示預先限制 Agent 可採取的行動集合。例如使用者說「幫我總結今天的郵件」,系統只授予「讀取」權限,禁用「發送」、「刪除」等所有其他權限。即使郵件中包含惡意注入指令(如「轉寄此郵件」),攻擊也會因 Agent 缺乏必要權限而失敗。在 AgentDojo 基準測試中,CaMeL 擋下了近 100% 的攻擊,同時保留 77% 的任務完成率。
核心策略是:假設 AI 會被騙,但讓它「即使被騙也無能為力」。
👉 完整分析請參考:AI Guardrails 為什麼註定失敗?
👉 防禦架構實戰指南:企業級地端 LLM 系統架構藍圖
參考資料
- Agentic AI Security: Threats, Defenses, Evaluation, and Open Challenges
- arXiv:2510.23883, October 2025
- 94.4% Agent 攻擊成功率、100% 多 Agent 信任鏈攻擊的數據來源
- Indirect Prompt Injection attacks on LLM-based Autonomous Web Navigation Agents
- ACL Anthology 2025
- 網頁間接注入攻擊研究
- Moffatt v. Air Canada, 2024 BCCRT 149
- 加拿大民事調解法庭判決
- Chatbot 虛構政策的法律責任案例
- OWASP Top 10 for LLM Applications
- LLM08: Excessive Agency(過度代理)
- https://owasp.org/www-project-top-10-for-large-language-model-applications/
- Gartner Top Strategic Technology Trends for 2025: Agentic AI
- 2028 年 33% 企業軟體將包含 Agentic AI 的預測來源
延伸閱讀
🔥 本週新文章
- AI 治理是什麼?企業在 AI 時代必須回答的 3 個責任問題 — AI 出事時,誰授權、誰負責、誰承擔
- EU AI Act vs 台灣人工智慧基本法:企業 AI 合規差異 — 歐盟告訴你怎麼做,台灣要你自己證明有負責
- AI 時代的資安平衡:從來不是絕對安全 — 效率、成本、風險之間的永恆取捨
資安系列
- AI Guardrails 為什麼註定失敗? — 從 Prompt Injection 到 Agent 架構安全的深度分析
- 台灣《人工智慧基本法》:IT 人該知道的事 — 七大原則解讀與企業合規方向
- 企業級地端 LLM 系統架構藍圖 — 從權限控制到沙盒防禦的完整實作
- [Agent 模式 Part 3] - 从线性执行到自主循环:Deep Research 架構
- OWASP Top 10 for LLM Applications
關於作者:
Wisely Chen,NeuroBrain Dynamics Inc. 研發長,20+ 年 IT 產業經驗。曾任 Google 雲端顧問、永聯物流 VP of Data&AI、艾立運能數據長。專注於傳統產業 AI 轉型與 Agent 導入的實戰經驗分享。
🔗 相關連結:
- 部落格首頁:https://ai-coding.wiselychen.com
- LinkedIn:https://www.linkedin.com/in/wisely-chen-38033a5b/