都要 2026 年了,企業 AI Excel 還是這麼難搞

前言:企業 Excel 場景,AI 還是很難用
昨天跟一個朋友聊 , 他跟我說「AI時代其實對我沒有任何的幫助,因為網路上都是一堆AI寫 email ,文生圖,文生影片的,但是我需要的 AI 做 Excel 分析,我所有同事都需要這個,但問題是:企業不允許上傳有內部資料的 Excel 檔案到 ChatGPT 或 Gemini。」
這一卡,很多 ChatGPT、Gemini 做得很好的 Excel 功能就全廢了—我們都知道ChatGPT 可以講一句話就幫你做分析、輸入、計算出樞紐。
那怎麼辦?我去年教 FDE 團隊工讀生的做法是:把 Excel 內容用截圖的方式貼上去。而且要記得把表頭、欄位名稱(A 到 Z)都截進去。這樣 AI 就能幫你寫公式,然後你再把公式貼回 Excel 執行。但這個做法有個根本問題:很慢,而且人要不斷剪下貼上。
最後出來的結果,你還是得自己用 Google 表格或 Excel 的 UI 做輸入,基本上公式撰寫能用,但是一些比較複雜的 Excel 操作像是樞紐,要做跨表 join,用這招根本做不到。
我就問他:「你們應該有一些 on-premise 的方案吧?地端部署大語言模型,資料不用上雲,但還是能做 Excel 操作。」
他默默回我:「我們是中小企業,這種東西沒有專人能搞。而且我聽其他公司的做法,地端模型基本上就是一個很陽春的 chatbot 視窗,上傳檔案、截圖都不能做。」
我腦中閃過一個想法:用 n8n 串一個流程,Python 把 Excel 轉成 CSV,丟給語言模型分析,再輸出成 Excel……但想想,光是語言模型的選型,要用 7B、17B、32B 還是 100B 就會搞死 IT 的,更別說後面要買的老黃顯卡。而且當你買好 server 機架之後,說不定還要改電源,然後就開始跟台電討論用電大戶的事情了。
這對中小企業來說真的太複雜了…
我又問他:「那選擇 Microsoft 365 Copilot 或 Google Workspace Gemini 呢?它們的付費版都有保證不會拿你的資料去訓練大模型,這樣資安問題應該可以解決吧?」他笑笑說:「那誰來跟 IT 討論呢?誰來跟資安單位討論呢?這個討論完,半年就過去了。」
好吧,那就是這樣了。2025 年底了,企業效率優化的聖杯「AI Excel」的環境還是這麼辛苦。
所以我就在想:有沒有一種方式,能夠用到雲端 ChatGPT 或 Gemini 那種非常方便的模式,又能保證資訊安全?
想著想著就想到——那我們從資料下手吧。
我寫了一個小程式,邏輯很簡單:既然企業資料不能上傳,那如果我們把資料混淆到連它媽(非髒話 XD,指製表人)都認不出來,那是不是就可以傳上去了?
核心概念:混淆文字,保留數字
這個做法的核心概念很簡單:把文字混淆掉,但保留數字和日期。
為什麼?因為你要做的是「分析」,分析需要的是數字的加總、比較、趨勢。至於「業務一部」還是「冬龍荷春」,對 AI 來說都一樣——它只需要知道這是一個類別,可以拿來分組就好。
混淆的邏輯
| 資料類型 | 處理方式 | 原因 |
|---|---|---|
| 數字 | 不混淆 | 要做計算、比較、趨勢分析 |
| 日期 | 不混淆 | 要做時間序列分析 |
| 中英文 | 混淆 | 這才是敏感資訊(人名、部門、客戶名) |
| 混淆,但保留 @ 和 .com | AI 才認得這是 email 格式 | |
| 電話 | 混淆數字,保留格式符號 | AI 才認得這是電話格式 |
關鍵設計:一致性映射
這裡有一個很重要的細節:同一個字永遠會映射到同一個字。
比如說:
- 「業務一部」→「冬龍荷春」
- 「業務二部」→「冬龍江春」
你會發現「業務」兩個字在兩筆資料都變成「冬龍」。這樣 AI 在分析的時候,還是能看出這兩個部門有關聯,可以做分組、比較。
如果每次都隨機亂換,「業務一部」可能變成「天地人和」,下一筆又變成「春夏秋冬」,那 AI 就完全看不出這是同一個部門了。
實際效果
混淆前:
混淆後:
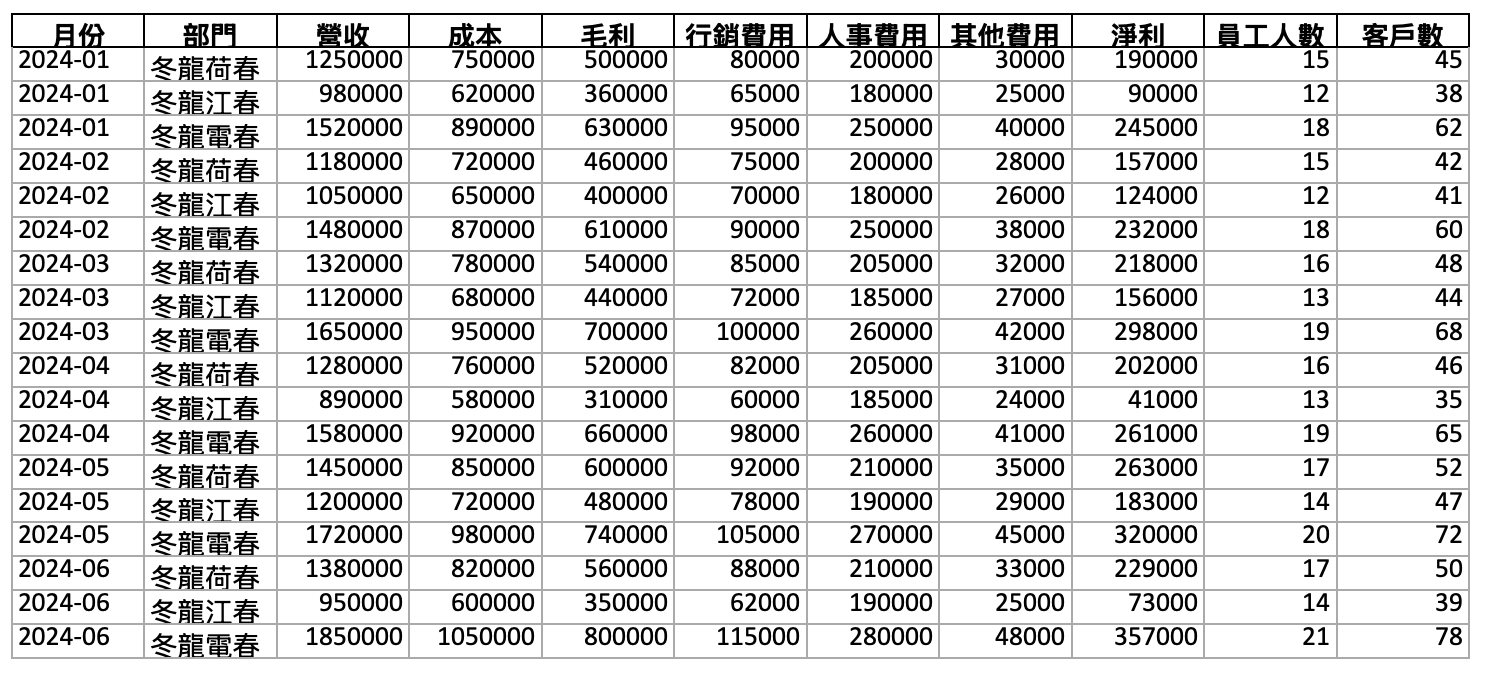
你看,日期和營收數字完全沒動,但部門名稱都變成認不出來的亂碼中文了。
這樣的資料丟給 ChatGPT,它還是可以幫你:
- 「哪個部門營收最高?」→ 「冬龍荷春」(你自己知道是業務一部)
- 「月營收趨勢?」→ 正常計算,數字沒變
- 「寫一個 SUMIF 公式」→ 正常生成
還原機制
混淆的時候會產生一個映射表(JSON 檔案),記錄每個字的對應關係。分析完之後,如果需要還原,跑一次還原程式就好。
程式本身
程式非常簡單,是用 Python 寫的。當然也可以隨著不同情況改成 PowerShell 或其他語言,不過 Python 已經可以同時跑在 Windows 和 Mac 上了。
GitHub: https://github.com/thegiive/excel-obfuscator
這個方法的限制
坦白說,這個方法有幾個限制:
- 要跑程式:不是每個人都會跑 Python
- 多一道工序:混淆 → 上傳分析 → 還原,流程變長
- 語意分析做不到:如果你要問「業務部的人都在做什麼」,AI 看到「冬龍」也不知道那是業務部
但對於「我只是要做數字分析,但資料不能外洩」的場景,這是目前我找到最務實的解法。
關鍵洞察
資安問題的解法不一定是「不上傳」,也可以是「上傳但認不出來」。
很多企業卡在「不能用雲端 AI」這個限制,其實換個角度想:如果資料已經混淆到連製表人都認不出來,那它還算是「企業機密」嗎?
這就像你把一份財報的公司名稱、部門名稱全部換成亂碼,數字保留。這份資料丟出去,別人根本不知道這是哪家公司的——但你自己拿著映射表,隨時可以還原。
工具是死的,思路是活的。