Gemini 3.0 Flash 不講理霸榜的真相
過去一年,大模型市場基本上就是三條產品線:
- Mini:快、便宜、能力一般,適用快速交互場景
- Normal:平衡型,適用一般場景
- Pro:最強、最貴,適用複雜推理
OpenAI、Google、Anthropic 三家都是類似的定位。
大家的討論也幾乎只有一個方向:Pro 怎麼更強、排行榜誰領先。
直到 2025/12/17 Google Gemini 3.0 Flash 剛出,一連串的評估霸榜,我們才驚覺 Google 似乎已經慢慢打破了這個範例
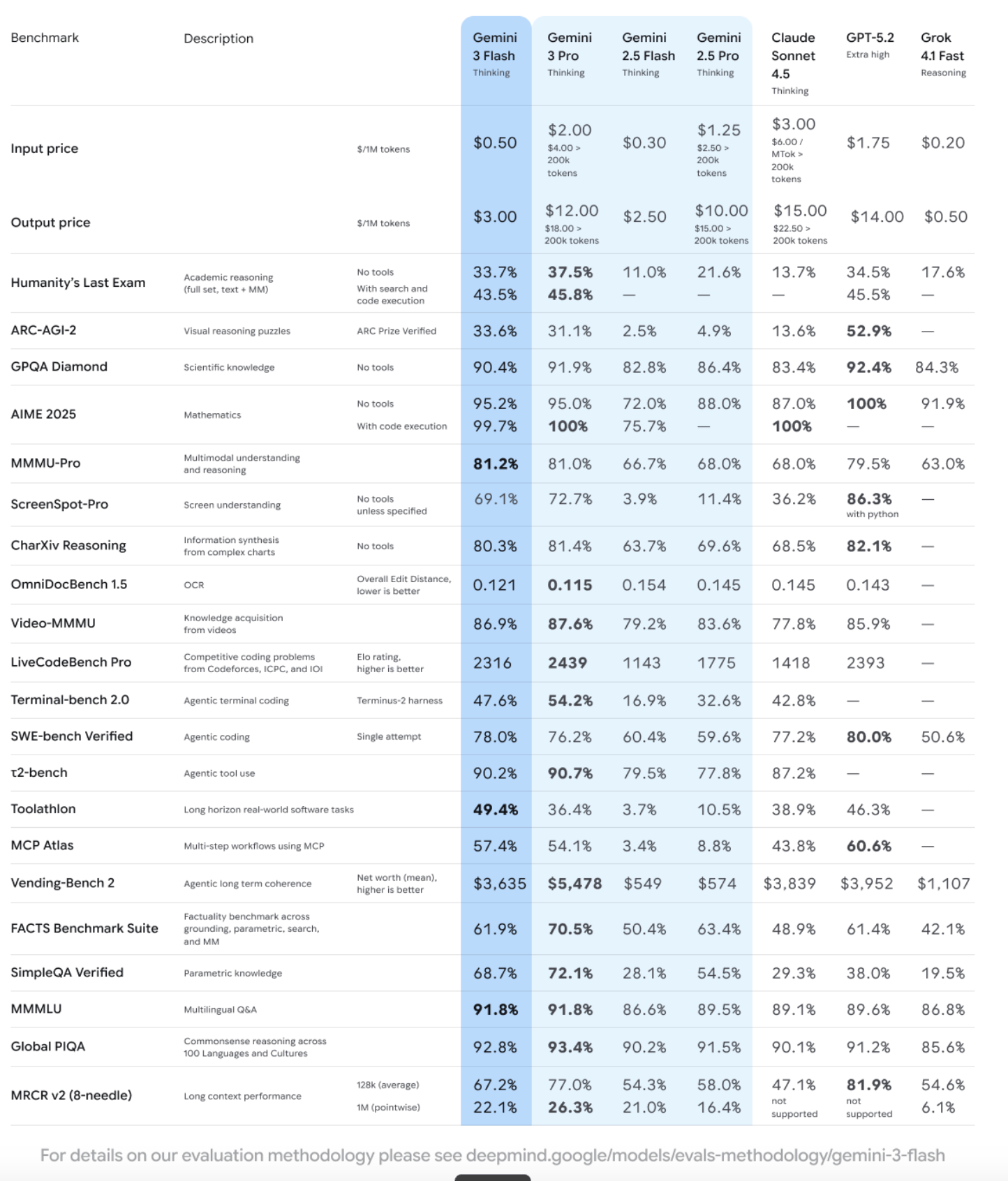
為何 Gemini 3.0 Flash 速度比較快、價錢比較低,居然很多測試贏過 Pro?Google 又再次掌握了什麼黑科技?
Gemini 3.0 Flash 的核心戰略意義
從 Gemini 1.5 Flash 開始,Flash 就被定位為「便宜版 Pro」——高吞吐、低延遲、處理簡單任務。傳統蒸餾理論告訴我們:學生模型只能逼近教師模型,永遠無法超越。
但 Gemini 3.0 Flash 打破了這個假設。
這種「輕量級反而更強」的現象,暗示了底層架構的根本性變化——不再單純依賴參數規模,而是依賴更高效的資訊路由與記憶機制。
Gemini 3.0 Flash 打破了 AI 線性增長法則。
當一個模型的推理成本低到可以忽略不計,且其長上下文召回能力達到完美(>99%)時,在 Pokémon 遊戲通關測試和 SWE-bench 代碼修復任務中,Flash 模型的表現之所以能超越 Pro 模型,正是因為其低延遲和低成本允許代理在單位時間內進行更多的「思考-行動-反思」循環。
在過去,要獲得 10% 的智能提升,通常需要 10 倍的算力投入。但 Gemini 3.0 Flash 以 $0.50/1M 輸入 token 的極低價格,提供了 GPQA Diamond 基準測試中 90.4% 的博士級推理能力。
知名 AI 研究員 @bycloudai 在深入評測後指出,Google 可能在模型架構研究上已處於「遙遙領先」的隱形地位。
這一表現打破了行業常規認知:它既沒有像標準注意力機制那樣產生高昂算力成本,也沒有像常見的線性注意力或 SSM 混合模型那樣導致知識推理能力下降。
Gemini 3.0 Flash 似乎掌握了某種未知的「高效注意力機制」,令外界對其背後的技術原理直呼「看不懂」但大受震撼。
Flash 真正的關鍵:推理時「會抓重點」
我們先理解一個事實
在大模型當中,大多數上下文,其實都是噪音。
Flash 類模型的強,在於它不試圖平等對待每一個 token。
傳統 Transformer 的邏輯是:
- 所有 token 都進 attention
- 所有歷史都靠 KV cache 留著
- 上下文越長,注意力越稀
結果就是:
- 找得到資料
- 但容易搞錯「你現在在講誰」
- 效率不佳
我們大部分的做法是,你丟給他一本三國演義,然後你的問題只問趙子龍七進七出砍了幾個曹軍,那 LLM 為何要看整篇的赤壁之戰呢?Flash 類模型在行為上很不一樣。它在推理時,會做類似這樣的事情:
- 哪些資訊被反覆提到 → 升級為關鍵
- 哪些資訊只出現一次 → 自然淡化
- 哪些細節後續還會被問到 → 持續影響推理
重點不是「記得全部」,而是記得對的東西。
這也是為什麼 Flash 在多輪指代、長對話下,反而比不少大模型穩。
新的注意測試方式
測試方式變了,才發現很多模型其實不行
以前我們常用大海撈針(NIAH) 測試:把一個關鍵資訊藏在長文裡,看模型能不能找出來,這只能證明「找得到」,不能證明「看得懂」。
真正企業在用 AI 時,要的是:
- 合約條款之間的關係
- 程式碼模組的相依性
- 多段資訊的前後推理
在這種 理解型測試(例如 MRCR 類) 下, Flash 的表現反而非常穩,甚至比不少「專業級」模型更可靠。
原因只有一個:它沒有試圖記住一切,而是記住「重要的東西」。
為什麼 Flash 看起來像「在邊用邊學」?
這裡很容易被誤會,我先講清楚:
- Flash 不是在推理時重新訓練模型
- 不是在線更新權重
它做的是更務實的一件事:
在推理過程中,動態調整「哪些資訊值得影響後續推理」。
你可以把它理解成:
- 模型權重是固定的
- 但「這場對話的重點筆記」是動態的
- 對話結束,這些筆記就丟掉
這也是為什麼 Flash 類模型:
- 不需要超大 KV cache
- 卻能撐住超長上下文
- 而且延遲與成本都壓得住
還記得我們週一講的 Google Nested Learning 嗎?我也的確懷疑 Google 把部分的深度記憶的概念做進去 Flash
這件事為什麼對 Agent 特別重要?
很多人忽略了一點:
Agent 的強,不在單次推理,而在「能跑幾輪」。
Flash 類模型的優勢剛好踩在這裡:
- 單次推理不一定最深
- 但夠快、夠便宜
- 可以在同樣時間內跑更多次「思考 → 行動 → 回饋」
在這種情況下:
- 低延遲 = 更多嘗試
- 低成本 = 更多修正
- 穩定記憶 = 不會每一輪都重來
這也是為什麼在實際任務中,Flash 常常能在 Agent、工具使用、程式碼修正這類場景追上甚至超過 Pro。
結論:演算法跟注意力工程的崛起
Gemini 3.0 Flash 的出現,似乎暗示了一件事:大模型的 Scaling Law 不一定那麼主導了。過去幾年,業界的共識是:模型越大、訓練資料越多、算力越猛,效果就越好。這條路線確實有效,但成本也越來越驚人。
Flash 證明了另一條路徑的可行性:
- 不靠堆參數
- 而是靠演算法優化
- 靠注意力機制的工程改進
- 靠更聰明的資訊路由與記憶管理
當這些「軟體層面」的優化開始發力,我們可能會看到更多像 Gemini 3.0 Flash 這樣的模型出現——又快、又便宜、效果又好。