重複 Prompt 就能提升 LLM 準確率?Google 最新研究揭示低成本優化技巧

目錄
一個看起來很蠢的方法,卻異常有效
很多人以為,要把大模型(LLM)用好,一定得靠兩件事之一:
- 複雜的 Chain-of-Thought(CoT)提示詞 — 讓模型「一步一步思考」
- 昂貴又麻煩的模型微調(Fine-tuning) — 用自己的資料重新訓練
但 Google Research 2025 年 12 月 最近的一篇論文,給了一個非常反直覺、卻異常有效的答案:
什麼都不用做,只要把「查詢(Query)」重複一遍。
論文的做法是:把 <QUERY> 變成 <QUERY><QUERY>,讓模型讀兩次。
實驗結論很簡單:
- 在不開啟推理模式(non-reasoning)
- 不使用 CoT
- 不改模型、不調參數
- 只要把整個查詢重複一次
Gemini、GPT、Claude、DeepSeek 等主流模型的準確率,全面上升。
而且:
- 幾乎不增加生成長度
- 幾乎不增加延遲
這在 LLM 世界裡,基本等於「白撿性能」——一個簡單的 Prompt 重複技巧,就能讓 Gemini、GPT、Claude 等模型的準確率顯著提升。
實驗結果有多誇張?
研究團隊在 7 個主流模型 × 7 個標準測試集 上測試。
測試模型包括:
- Gemini 2.0 Flash / Flash-Lite
- GPT-4o / GPT-4o-mini
- Claude 3 Haiku / Claude 3.5 Sonnet
- DeepSeek V3
測試集包括:ARC (Challenge)、OpenBookQA、GSM8K、MMLU-Pro、MATH,以及兩個自訂任務 NameIndex 和 MiddleMatch。
結果是:
- 勝場數:47
- 敗場數:0
- 平手:23
47 勝 0 負。 沒有任何一個場景變差。
其中最離譜的案例:
在 NameIndex 任務中,Gemini 2.0 Flash-Lite 準確率從 21.33% → 97.33%
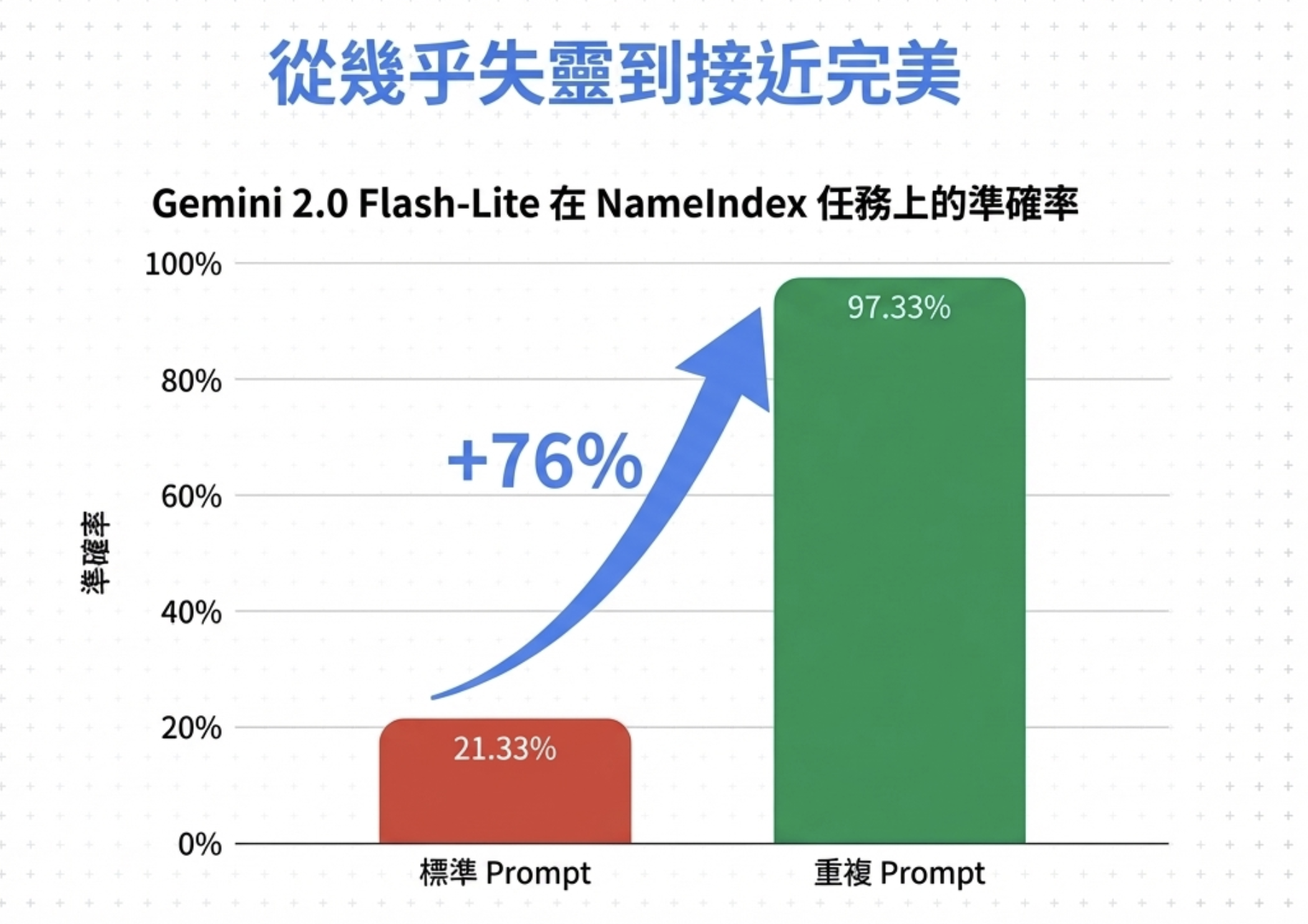
這不是小幅提升,是直接起飛。76 個百分點的差距。
為什麼「讀兩遍」會有用?
關鍵原因在於:絕大多數 LLM 都是因果語言模型(Causal Language Model)。
這代表一件事:
模型在生成時,只能「向後看」,看不到未來。
這就像小學中文閱讀測驗。
我在幫小孩複習功課時,常常看到一個很真實的場景:題目背景又臭又長,半頁考卷都在鋪陳情境,小孩一路讀下來,根本不知道重點在哪裡。直到看到最後一行題目,才突然發現:「喔,原來是在問這個。」

接下來怎麼辦?只能回頭,從那一大段背景裡重新找線索、圈重點、再讀一次。
很多時候不是小孩不會,而是第一次讀的時候,根本不知道要抓什麼重點。
大模型遇到的是一模一樣的問題。當我們把一大段背景資料先丟給 LLM,最後才問問題時,模型在第一次「閱讀」時並不知道哪些資訊才是關鍵,注意力自然被平均分散,甚至浪費在不重要的細節上。這就是 LLM 長文本語意理解 的結構性挑戰。
Prompt Repetition 做的事情,本質上就是讓模型像學生一樣,把考卷再讀一次——而且這一次,它已經知道題目在問什麼了。
Prompt Repetition 本質上在做什麼?
當你把 Prompt 重複一遍時:
- 第一遍: 模型「盲讀」全文
- 第二遍: 模型已經知道問題是什麼
於是第二次讀取時:
- 注意力分布更集中
- Token 與 Token 之間的關聯更準確
論文裡直接形容:
這等同於人為幫模型補了一次全局注意力。
效果就像讓因果模型「偷看」到後面的內容。
哪些場景提升最大?
論文發現效果最好的是「Options-First」場景——選項在前、問題在後。
為什麼?因為模型第一次讀選項時,根本不知道問題是什麼,注意力被浪費了。重複一次後,第二次讀選項時,模型已經知道要找什麼答案。
具體範例
假設你要讓 LLM 從選項中選出正確答案:
原始 Query(Options-First 格式):
1
2
3
4
5
6
A. 張三
B. 李四
C. 王五
D. 趙六
員工名單中,第 3 個人的名字是?
套用 Prompt Repetition(重複整個 Query):
1
2
3
4
5
6
7
8
9
10
11
query = """
A. 張三
B. 李四
C. 王五
D. 趙六
員工名單中,第 3 個人的名字是?
"""
# 論文做法:整個 Query 重複
prompt = query + "\n\n" + query
效果:
- 第一次讀:模型看到 A/B/C/D 選項時,不知道問題是什麼,注意力分散
- 第二次讀:模型已經知道「要找第 3 個人」,注意力集中在正確選項
其他適用場景:
- 長背景資料 + 短問題
- 需要從大量文本中找特定資訊
- 問題在前、選項在後(Question-First)也有效,但提升幅度較小
為什麼這是工程師最愛的技巧?
因為它幾乎沒有成本。
和 CoT、Agent、RAG 比起來:
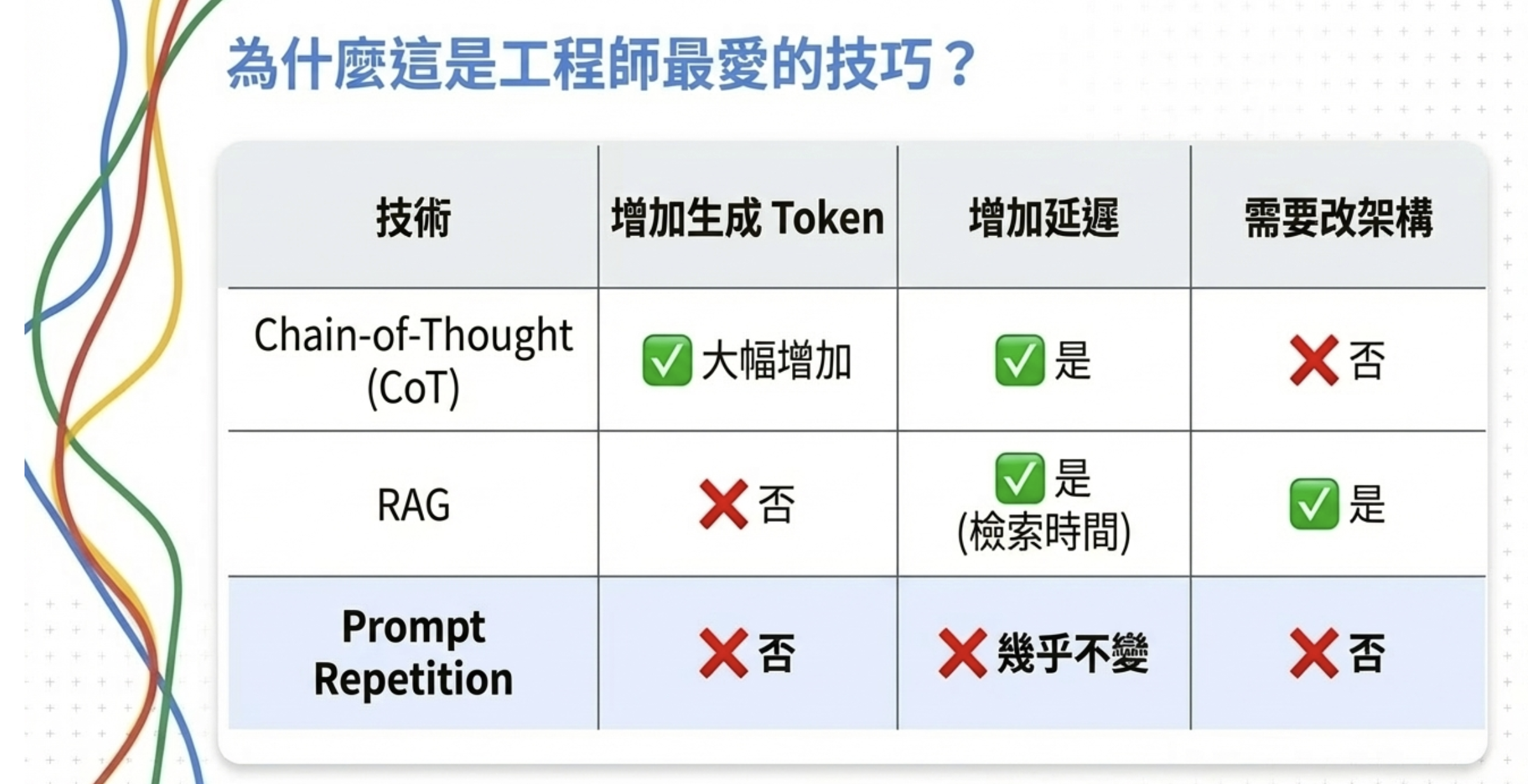
重複的部分發生在 prefill 階段(模型讀取輸入),這是可以並行化的。生成階段完全不受影響。
你甚至只要在 API 調用前,多加一行代碼:
1
prompt = query + "\n\n" + query
就結束了
坦白說:這個技巧的限制
我必須誠實講幾個問題:
1. 對推理模型效果有限。
論文測試了開啟「step-by-step」推理模式的情況,結果是:5 勝、1 負、22 平。比起 non-reasoning 的 47 勝 0 負,效果明顯打折。
推測原因:推理模型本來就會在生成過程中「回顧」輸入,Prompt Repetition 的好處被抵消了。
2. 輸入 Token 數會翻倍。
這是最大的成本。Query 重複一次,輸入 Token 就變成兩倍。如果你的 Query 本來就很長(比如 10K tokens),重複之後就是 20K。這會影響 API 成本,也可能碰到 context window 上限。
不過論文指出:重複發生在 prefill 階段(可並行化),生成階段不受影響,所以延遲增加很少。
3. 純生成任務效果不明。
論文主要測試的是選擇題和資訊檢索任務。純生成任務(比如寫文章、翻譯)的效果還不清楚。
一個更有意思的觀察
論文裡還有一個耐人尋味的發現:
經過強化學習訓練的 Reasoning Models,往往會「自動學會」重複用戶指令。
這代表什麼?
Prompt Repetition 本身,可能就是一種原生的推理增強機制。
換句話說:你不是在作弊,而是在手動觸發模型本來就該做的事。
實戰建議
適用場景:
- ✅ 長上下文 + 短問題
- ✅ 多選題 / 比較題
- ✅ 不想開推理模式,又想更準
- ✅ 成本敏感,不想用 CoT 增加 output tokens
具體做法:
1
2
3
4
5
# 最簡單的實作
def repeat_query(query):
return query + "\n\n" + query
response = llm.generate(repeat_query(your_query))
論文還提供了一個「Verbose」版本:
1
2
3
# 加入過渡語句
def repeat_query_verbose(query):
return f"{query}\n\nLet me repeat that:\n\n{query}"
關鍵洞察
「因果注意力」是 LLM 的結構性限制。 這不是 bug,是設計。但這個設計讓模型在讀前面內容時,無法知道後面要問什麼。Prompt Repetition 是一個 hack,用重複來繞過這個限制。
免費的性能提升很稀有。 在 AI 領域,通常更好的性能意味著更多計算、更多資料、更多工程。Prompt Repetition 是少數「白撿」的優化——不增加生成成本,不改架構,效果卻很明顯。
最反直覺的方法,有時最有效。 如果有人一年前告訴我「把 Prompt 複製貼上就能提升準確率」,我會覺得他在開玩笑。但 Google Research 的實驗結果擺在這裡:47 勝 0 負。這個 Gemini GPT Claude 提升準確率 的方法,已經被嚴謹驗證過了。
結語
下次你覺得模型「變笨了」,在懷疑模型之前,先試試一件事:
把你的問題,再說一遍。
也許它只是需要「多讀一次」。
延伸閱讀
- 原始論文: Prompt Repetition Improves Non-Reasoning LLMs
- arXiv HTML 版: Full Paper
相關連結:
- 部落格首頁:https://ai-coding.wiselychen.com
- LinkedIn:https://www.linkedin.com/in/wisely-chen-38033a5b/