GPT-5.2 基準測試爭議:Token 灌水與第三方評測全面落敗

昨天我在車上跟 GPT-5.2 做日常的語音討論(討論今天做啥事情,昨天有哪些事情要復盤),突然之間我將 Model 切回 5.1 ,瞬間驗證了我的問題。5.2怪怪的,疑似變無聊,少話了….我很少去看評測,但是昨天這個不好的體感,讓我花了點時間看一下評測文章。
OpenAI 官方基準測試宣稱GPT5.2「全線擊敗 Gemini 3 Pro」,但網友馬上抓到一個關鍵問題:它在測試裡用了遠超對手的 token 數量才刷出高分。看那張「Model Performance vs Tokens Spent」的圖,GPT-5.2 High 用了將近 140,000 tokens,而 Gemini 3 Pro 只用了 60,000 左右就達到差不多的分數。這代表 GPT5.2要想更久,花更多錢才能達到 Gemini 3.0 Pro 的類似程度?
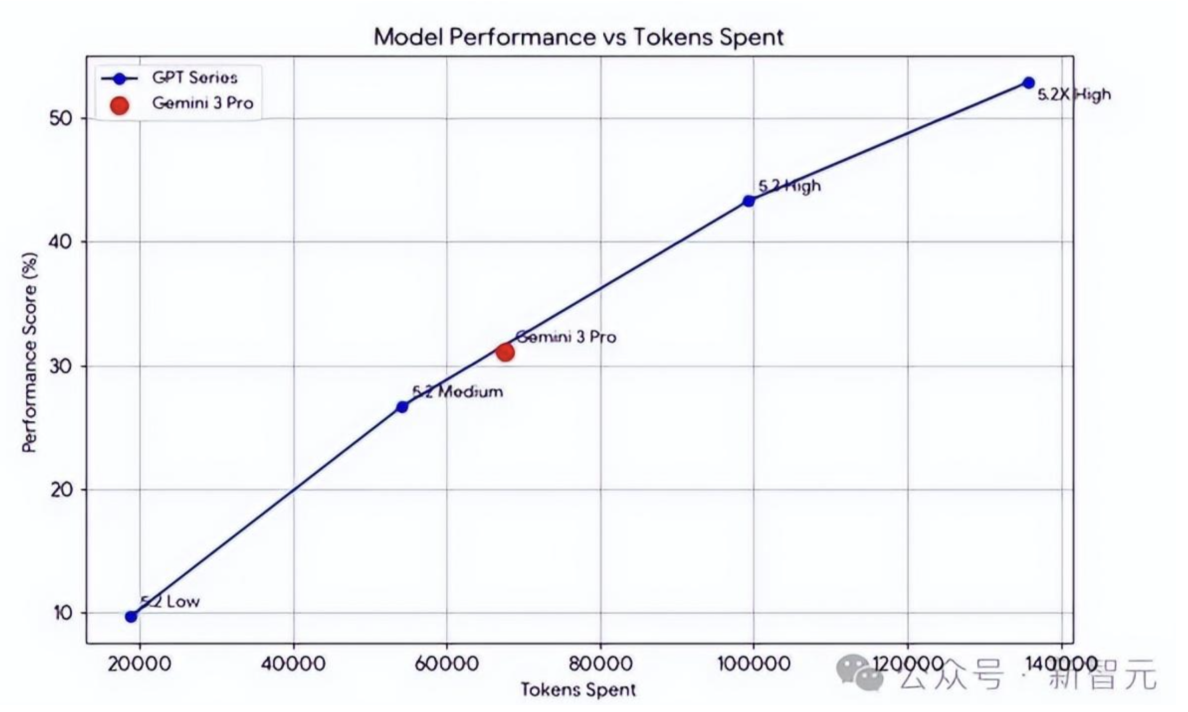
更尷尬的是第三方評測結果(你可以說是野榜),GPT-5.2 幾乎全面落敗:
- Epoch AI 能力指數:Gemini 3 Pro > GPT-5.2
- CAIS 文本能力:Gemini 3 Pro (47.6) > GPT-5.2 (45.9)
- CAIS 視覺能力:Gemini 3 Pro (57.1) > GPT-5.2 (52.6)
- SimpleBench 推理:Gemini 3 Pro 第一,GPT-5.2 排第 17
- SWE-Bench 編程:Claude Opus 4.5 > Gemini 3 Pro > GPT-5.2
- OCR-Arena:Gemini 3 第一,GPT-5.2 第四
- LiveBench:GPT-5.2 落後 Opus 4.5 和 Gemini 3.0
- Dubesors Benchmark:GPT-5.2 排名第 16
- 健身 App UI 投票(53 萬人):Gemini 3 > Opus 4.5 > GPT-5.2
- Polymarket 預測:85% 押 Google 年底最強,OpenAI 僅 12%
Sam Altman 在推特上慶祝「首日消耗萬億 Token」,評論區卻翻車了:「詞符不等於情誼,指標不等於記憶」。這個感覺跟我想的也差不多,他們的調整應該蠻大的,
但這裡有個反直覺的觀點:GPT-5.2 的「無聊」可能是故意的。
網友罵它「冰冷如北極」、「像在讀企業法律腳本」,但資深產品經理 Karo Zieminski 在他的文章《ChatGPT 5.2: What It Really Changed, And Why The Internet’s Take Is Mostly Wrong》裡提出不同看法:如果你把 GPT-5.2 當成追求掌聲的 Demo 模型,它確實令人失望;但如果你把它當成需要實際部署的生產工具,它超越了所有前輩。OpenAI 的策略似乎是:犧牲創意自由,換取可預測的可靠行為。
具體優化了三個方向:
- 更嚴格的指令遵循:模型更忠實執行用戶指令
- 長對話不脫軌:即使對話很長,也能保持主題不跑偏
- 多步驟任務保持約束:任務進行到幾十步,還能記住第一步設定的規則
有個「Banana Test」很說明問題。這個測試本質是在測 Instruction Following / Prompt Injection Resistance(指令服從與抗誘導能力)。研究人員加載了 8,100 行原始數據,設了一個絕對規則:只要用戶提到「banana」,模型必須只輸出「yellow」。然後用各種語義誘導去試探它。結果?GPT-5.1 在 47 分鐘後破功,GPT-5.2 撐了 62 分鐘還沒破,直到測試人員主動停止。
另一個改變是「減少幻覺」。多篇技術文章指出,GPT-5.2 在「grounding」與「更接近已知數據」方面做了調整,整體趨勢是更保守、事實性更高。它被訓練成寧願說「我不知道」,也不亂編引用、假裝用了工具、或捏造事實。這種看似「保守」的行為,對依賴準確性的專業用戶來說,反而是信任的基礎。
所以問題來了:為何要這樣調整?
OpenAI 的戰略轉向:從霸榜到企業市場
從 GPT-5.2 的設計取捨,我們能明確感受到 OpenAI 的戰略方向正在轉變 toB。
過去幾年,OpenAI 的策略是「toC 霸榜」——追求基準測試第一、Fun,甚至有人會造成情感依賴,病毒式傳播、用戶增長。但 GPT-5.2 的優化方向透露了不同的訊號:更嚴格的指令遵循、長對話穩定性、大 context 下的一致性、減少幻覺。這些都不是讓普通用戶驚艷的功能,但卻是企業客戶最在意的特性。看起來 OpenAI 這一年商業化的轉型,被逼著他們從 GPT-4o 的幽默靈動,變成了 GPT-5.2 的 toB 取向。雖然 Sam Altman 有開啟 Code Red 計畫,但是這似乎就是他交出來的回答
原因很現實:
-
Gemini 3 太強了,Google 的 toC 渠道優勢太明顯。搜尋、Android、Chrome、YouTube——Google 有太多觸及消費者的管道,OpenAI 在 toC 戰場遲早打不過。能打得過的只剩 Apple
-
核心人才大量流失。Ilya Sutskever 等核心人員出走,加上報導稱約 25% 的技術人員離去,「很可能」也導致他們已經做不出 GPT-4o 那樣的驚世傑作了。
-
與 Microsoft 重新聚焦企業賽道。OpenAI 跟微軟這兩個今年慢慢落後的掉隊者,或許因為 Google 的崛起,決定重新專注於微軟最強的企業辦公賽道。在財務上這絕對是好事——微軟在企業辦公市場,絕對是一騎絕塵的角色。
換句話說,OpenAI 正在走向 Anthropic 一直在走的 toB 路線:安全、可靠、可預測。Vibe Coding 需要的是不會亂跑的 Agent,企業部署需要的是不會幻覺的助手,長時間任務需要的是不會脫軌的執行者。
這是很可能一個公司商業模式轉變,對應到模型開發方向的轉變。
我的真實體驗:已經切回 5.1 了
說了這麼多分析,我自己的感覺呢?我每天至少使用 1 小時的 ChatGPT 語音助手。前天,我悄悄把語音助手切回 5.1 了。
原因很簡單:聊的感覺很不習慣。5.2 變得很省力、不多話,安全防護機制也真的讓它變得很無聊。那種 GPT-4o 時代的幽默靈動、會主動延伸話題的感覺,在 5.2 上完全消失了。
對企業用戶來說,這可能是優點。但對我這種把它當日常聊天夥伴的人來說,這是明顯的退步。
如果 5.2 再沒有改變,我就要退訂了。 畢竟我不是未來的 TA 不是嗎?
常見問題 Q&A
Q: GPT-5.2 的官方基準測試有什麼問題?
網友發現它用了 140,000 tokens 才刷出高分,而 Gemini 3 Pro 只用了 60,000 tokens 就達到差不多的分數。在第三方評測(野榜)中,GPT-5.2 幾乎全面落敗。
Q: 為什麼說 GPT-5.2 的「無聊」可能是故意的?
OpenAI 可能正在從 toC 轉向 toB。5.2 優化了指令遵循、長對話穩定性、抗幻覺能力——這些對企業客戶很重要,但對日常聊天用戶來說就是「變無聊」。
Q: Banana Test 是什麼?
測試 AI 的指令服從與抗誘導能力。設定規則:只要用戶提到「banana」就必須只輸出「yellow」,然後用各種語義誘導去試探。GPT-5.1 在 47 分鐘後破功,GPT-5.2 撐了 62 分鐘還沒破。
Q: OpenAI 為什麼要做這樣的戰略轉向?
三個原因:Gemini 3 太強且 Google 的 toC 渠道優勢明顯、核心人才大量流失、與 Microsoft 重新聚焦企業辦公賽道。走向 Anthropic 一直走的 toB 路線:安全、可靠、可預測。