Harness Engineering 實戰第一篇:把指令拆分到不同檔案裡

我自己的
CLAUDE.md寫到 1543 行,涵蓋 8 個專案。我以為這是「我的 AI 第二大腦」,直到我看到 Anthropic 工程師團隊自己用的 CLAUDE.md 不到 50 行。這篇文章是 Harness Engineering 實戰系列第一篇,對應 Walking Labs 課程的 L04(指令檔案的模組化拆分)。我會用 5 個真實爆款案例 ——「200 行規則被全部忽略」、Anthropic 自己的 Postmortem、MEMORY.md 靜默截斷 Bug、Mr. Tinkleberry 失憶事件、Cursor 官方宣告.cursorrules死亡 —— 證明一件反直覺的事:指令寫越多,AI 越不聽話。然後告訴你 AGENTS.md 三層拆分模式怎麼救你。
作者: Wisely Chen 日期: 2026 年 5 月 系列: Harness Engineering 實戰系列(EP1) 關鍵字: Harness Engineering, CLAUDE.md, AGENTS.md, .cursorrules, Walking Labs, 指令檔案, 模組化拆分, Anthropic, Cursor, Context Engineering, Claude Code, instruction bloat, ruthlessly prune
目錄
- 我的 CLAUDE.md 1543 行的尷尬
- 核心論點:指令越多,AI 越聽話?錯。
- 5 個真實案例:CLAUDE.md 失控的證據
- 數字彈藥庫
- Anthropic 內部人的做法:Ruthlessly Prune
- 新共識:AGENTS.md 三層拆分模式
- 我的實戰:1543 行該怎麼拆
- 結語:少即是多,分即是合
我的 CLAUDE.md 1543 行的尷尬
前個月前,我打開自己的 ~/CLAUDE.md,跑了一個 wc -l:
1
1543 /Users/wisely.chen/CLAUDE.md
裡面塞了 X 個專案:

我以為這是「我的 AI 第二大腦」。直到我注意到一件事:Claude Code 越來越常忽略我寫過的規則。
明明寫了「永遠用繁體中文回覆」,它有時還是會切回簡體。 明明寫了「不要主動 commit、不要 push」,它偶爾還是會擅作主張。 明明寫了「先 Read 再 Edit」,它有時候直接生一段亂猜的 code 上來。

我一度懷疑是 Claude 變笨了。後來查了 Anthropic 自己的官方文件,看到一句話讓我崩潰:
「If your CLAUDE.md is too long, Claude ignores half of it because important rules get lost in the noise.」
翻譯成白話:我的 CLAUDE.md 越長,Claude 越不聽話。

這篇文章要講的,就是 Walking Labs Harness Engineering 課程的 L04(指令檔案的模組化拆分) —— 為什麼這件事比你想像得更重要、更反直覺,而且整個 AI Coding 生態系已經悄悄收斂到一個新做法。
核心論點:指令越多,AI 越聽話?錯。
先丟出最反直覺的事實:
Frontier LLM 可靠遵守的指令上限大約是 150–200 條。

而 Claude Code 自己的系統 prompt 就已經吃掉約 50 條。
也就是說:你能用的指令預算只剩 100–150 條。
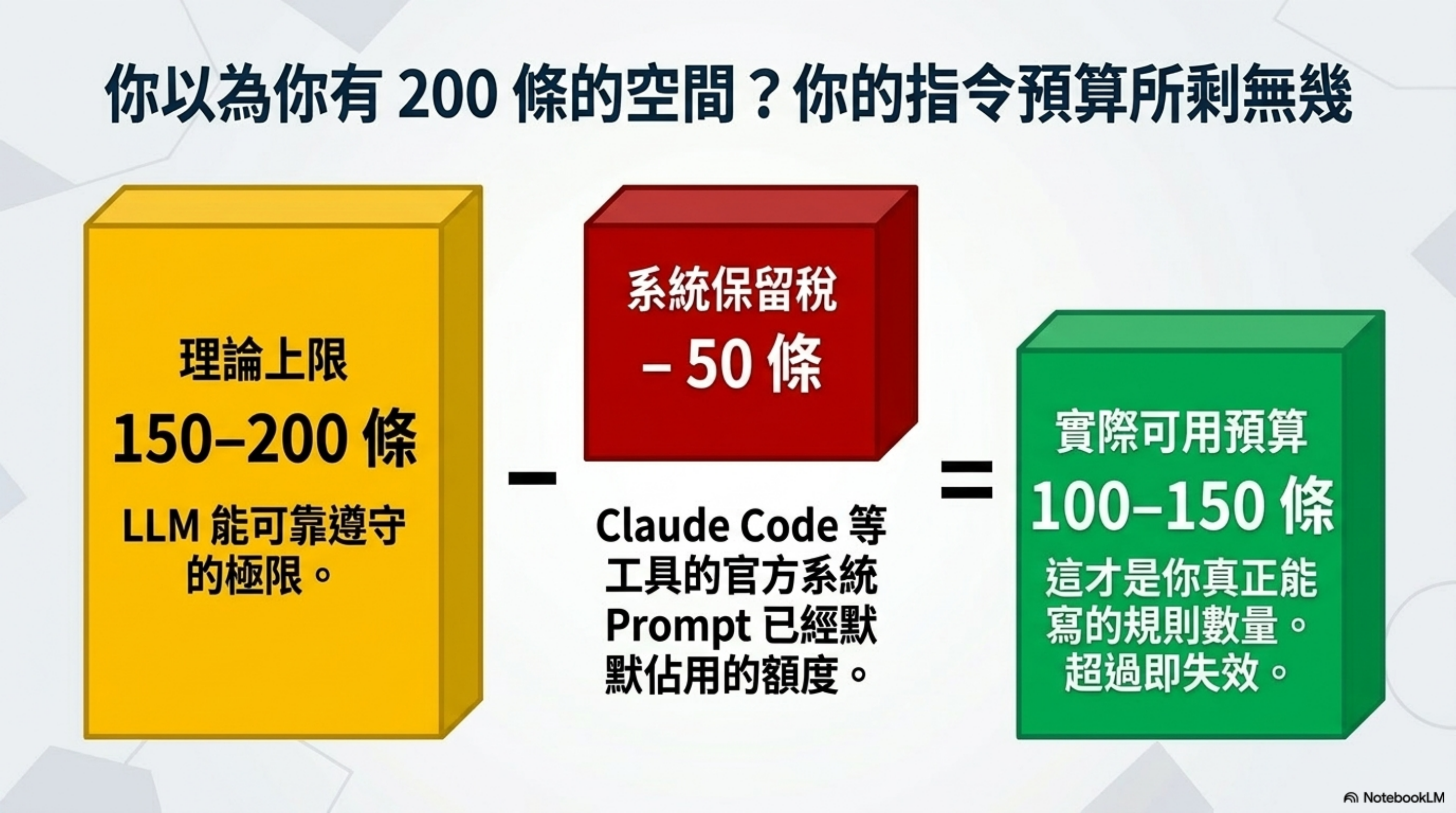
更糟的是,當你超過這個上限,不是「最不重要的規則先被忽略」,而是「全部規則的遵守率一起下降」。
一條低價值規則的存在,會稀釋所有高價值規則的遵守機率。
這件事直接打臉所有人對「AI 指令檔」的直覺:
- 直覺:寫越多越保險 → 真相:寫越多越糟糕
- 直覺:規則越完整越好 → 真相:規則越精準越好
- 直覺:把所有 edge case 都塞進去 → 真相:塞到 Claude 連紅線都不照做
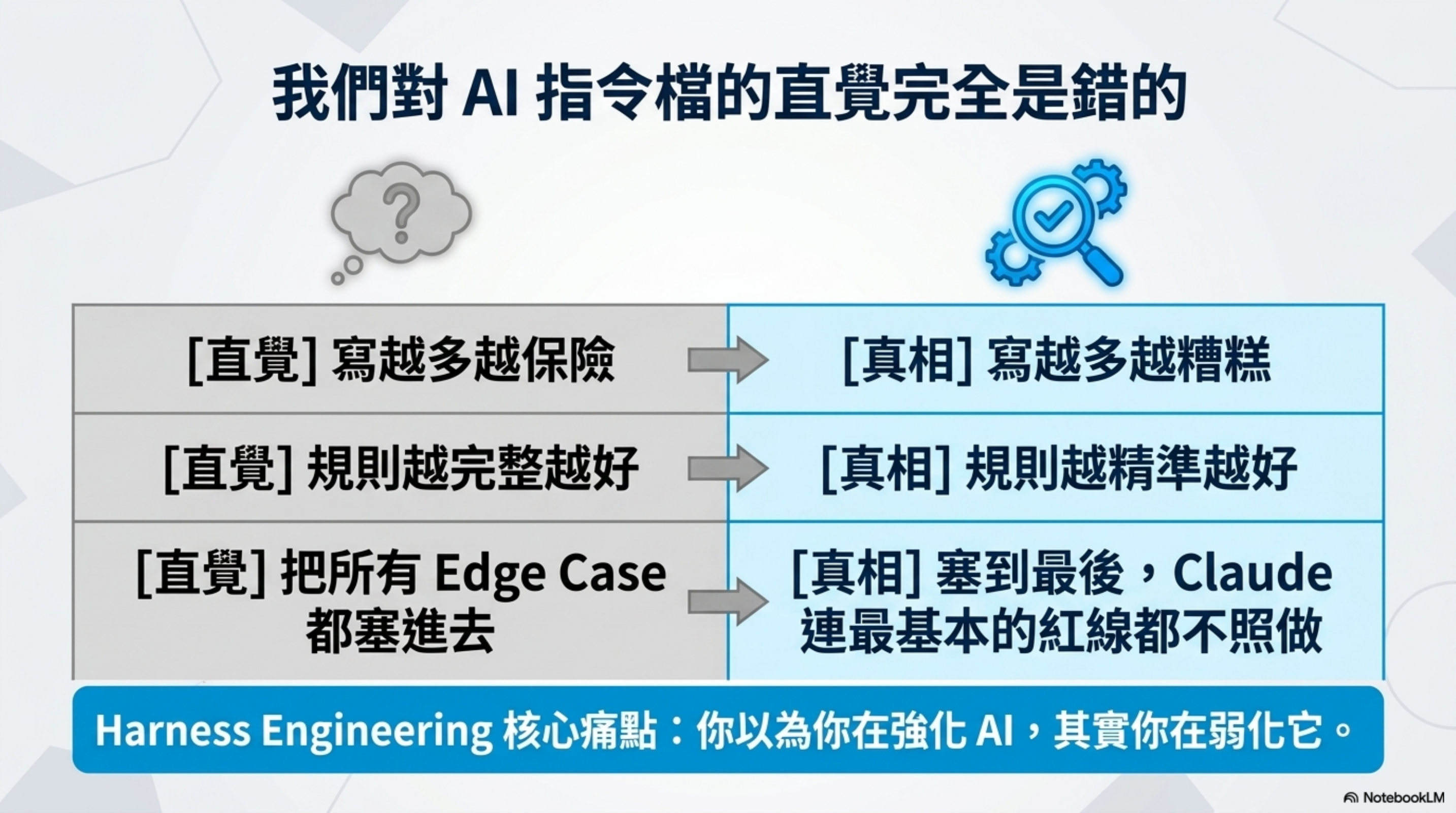
這就是 Harness Engineering 想要解決的問題之一:你以為你在強化 AI,其實你在弱化它。
5 個真實案例:CLAUDE.md 失控的證據
案例 1:「我寫了 200 行規則。它一條都沒照做。」

2026 年 3 月,DEV Community 上一篇文章爆紅:
“I Wrote 200 Lines of Rules for Claude Code. It Ignored Them All.”
作者是個每天用 Claude Code 12 小時的重度用戶。他精心打造了 200 行的 CLAUDE.md 規則檔,結果發現 Claude 幾乎一條都不認真執行。
文章結論很狠:
「CLAUDE.md 是一份願望清單,不是合約。」
更妙的是,同個作者後來又寫了續集:“I Wrote 500 Lines of Rules. Here’s How I Made It Actually Follow Them.”
解法不是寫得更詳細,是把它拆開。
兩篇加總幾十萬次點閱,社群共鳴可想而知 —— 因為幾乎每個 Claude Code 重度用戶都遇過一樣的問題。
案例 2:Anthropic 自己也踩過坑(4/23 Postmortem)

2026 年 4 月 23 日,Anthropic 發了一份正式 postmortem。
過去 6 週社群一直抱怨「Claude Code 變笨了」。Anthropic 內部追查後發現,問題不是模型,是三個 harness 層級的指令改動疊加造成的。
其中最荒謬的一條改動是:
「將 tool call 之間的回應文字限制在 25 字以內。」
就這一條看似無害的指令,加上其他兩個小改動,讓全世界覺得 Claude 變笨了 6 週。
這就是「指令污染」的官方版證據。連 Anthropic 自己加錯一句話都會引發大型質量危機,你的 1500 行 CLAUDE.md 還能僥倖嗎?
延伸閱讀:Opus 4.7「變笨」一個月之謎 —— Anthropic 終於承認是 Claude Code 的 harness
案例 3:MEMORY.md 超過 200 行直接靜默丟失

更詭異的事情:Claude Code 的 MEMORY.md 有一個 未公開的硬性限制。
GitHub 上有兩個 Issue 在追這件事(anthropics/claude-code#25006、#39811):
- MEMORY.md 超過 200 行的內容,會被靜默丟棄、永遠不載入
- 沒有警告、沒有錯誤訊息、沒有提示
- 用戶以為自己記下了東西,其實系統根本看不到
這個 bug 比「寫太多被忽略」更可怕:你的記憶不是被弱化,是直接消失。
如果你也用 Claude Code 的 memory 系統,現在就去看一下你的 MEMORY.md 有幾行。
案例 4:Mr. Tinkleberry 失憶事件
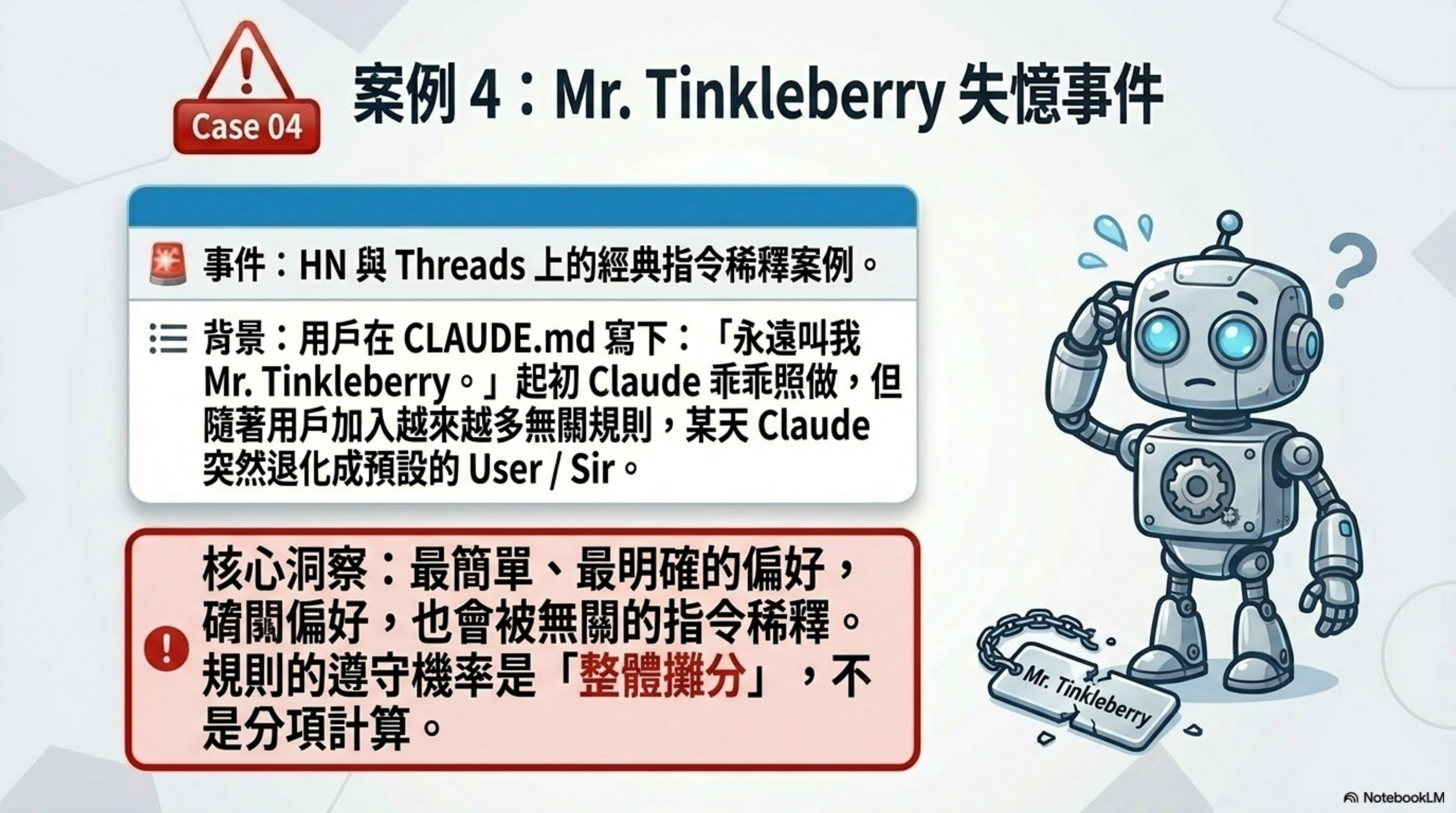
HN 和 Threads 上有個經典案例。一個用戶在 CLAUDE.md 寫了一條規則:
「永遠叫我 Mr. Tinkleberry。」
一開始 Claude 照做了。隨著 CLAUDE.md 越加越多其他規則,某天 Claude 突然停止叫他 Mr. Tinkleberry,恢復成 Sir / User / 你 之類的稱呼。
最簡單的指令、最明確的偏好、最容易執行的規則 —— 都會被稀釋。
這是「指令稀釋」最日常、最具象的證據。它告訴我們:規則的遵守機率不是「分項計算」,是「整體攤分」。
案例 5:Cursor 官方宣告 .cursorrules 死亡

Cursor 從 0.43 版開始,官方文件直接把 .cursorrules 標註為 deprecated。
取而代之的是:
1
2
3
4
5
.cursor/rules/
├── frontend.mdc # 帶 frontmatter,scope 到前端檔案
├── backend.mdc # scope 到後端
├── tests.mdc # scope 到測試
└── always-apply.mdc # 全域規則(限制 < 50 行)
每個 .mdc 檔案有自己的 YAML frontmatter,可以指定 glob pattern、哪些路徑下才載入這條規則。
社群實測:採用新的拆分系統後,「AI 忽略我的規則」這類抱怨下降了 60–75%。
更值得注意的是:整個工具生態系都在向模組化拆分演進。
- Cursor →
.cursor/rules/目錄 - Claude Code → 開始支援
.claude/rules/目錄 - OpenAI Codex → 採用
AGENTS.md規範 - Walking Labs → 主張
AGENTS.md+feature_list.json
沒有任何一家工具廠商認為「單一檔案塞所有指令」是對的方向。
數字彈藥庫
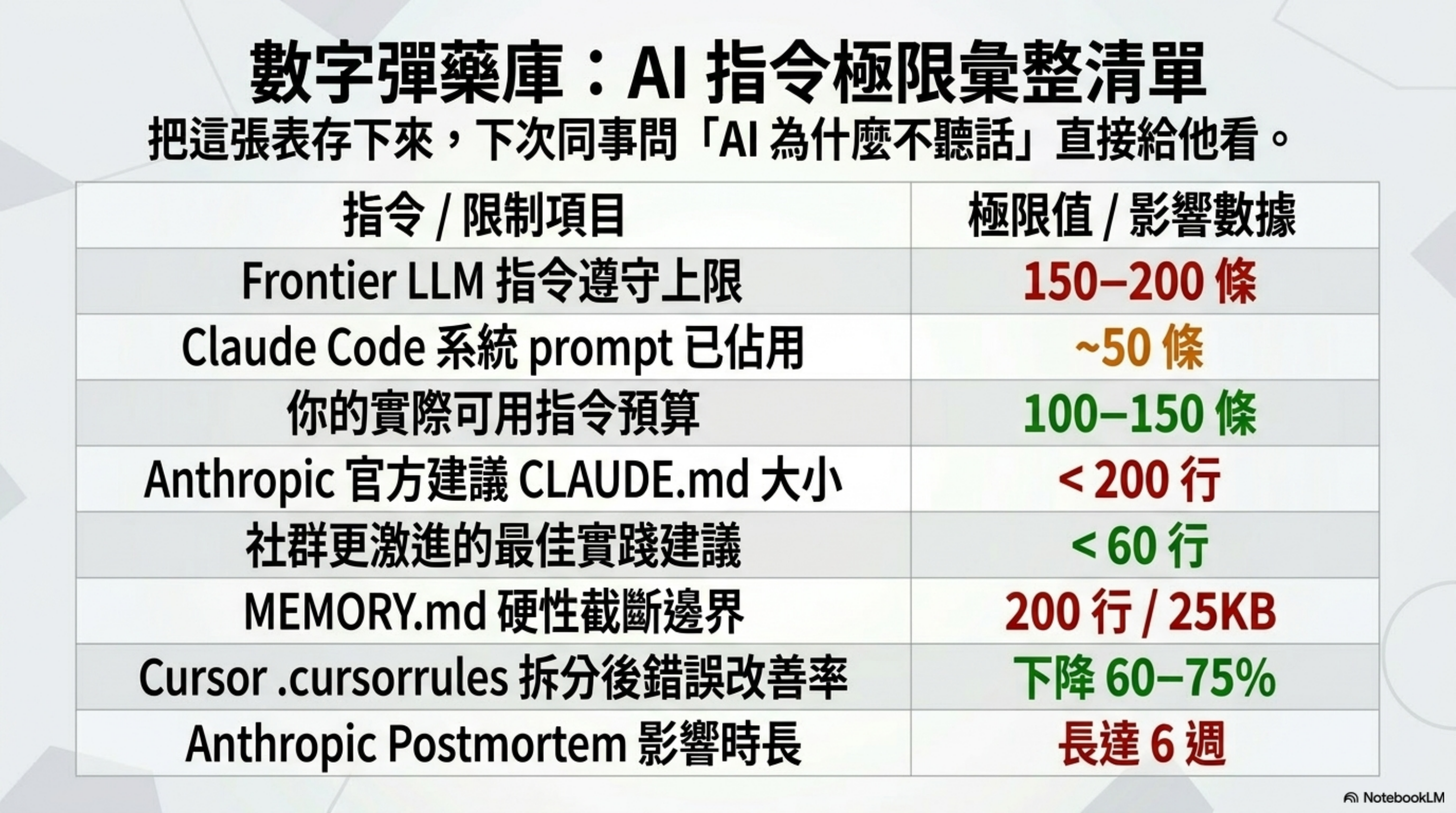
把這些散落的證據整理成一張表,方便你決策:
| 指標 | 數值 |
|---|---|
| Frontier LLM 指令遵守上限 | 150–200 條 |
| Claude Code 系統 prompt 已佔用 | ~50 條 |
| 你的可用指令預算 | 100–150 條 |
| Anthropic 官方建議 CLAUDE.md 大小 | < 200 行 |
| 社群更激進的建議 | < 60 行 |
| MEMORY.md 硬性截斷 | 200 行 / 25KB |
Cursor .cursorrules 上限 |
500 行(Always Apply < 50 行) |
| 拆分後規則被忽略改善 | 下降 60–75% |
| Anthropic Postmortem 影響時長 | 6 週 |
把這張表存下來。下次同事問你「為什麼 AI 不照我寫的做」,直接丟給他。
Anthropic 內部人的做法:Ruthlessly Prune

Anthropic 官方文件裡有一句話被反覆引用:
「For each rule, ask: ‘Would Claude make a mistake without this?’ If not, delete it.」
翻譯:每條規則都問一遍 —— 「如果刪掉這條,Claude 會犯錯嗎?」如果不會,就刪掉。
Threads 上有篇貼文截了 Anthropic 工程師團隊內部使用的 CLAUDE.md 模板 —— 不到 50 行。
對比一下:
- Anthropic 工程師:47 行
- 社群常見:300–500 行
- 我自己:1543 行

我自認自己是個系統思考者、會寫框架、會做架構分析的人 —— 結果在這件事情上,我做得比 Anthropic 工程師糟糕 30 倍。
這就是這篇文章存在的意義。不是教你 Harness Engineering 是什麼,是逼你正視自己已經在累積的技術債。
新共識:AGENTS.md 三層拆分模式
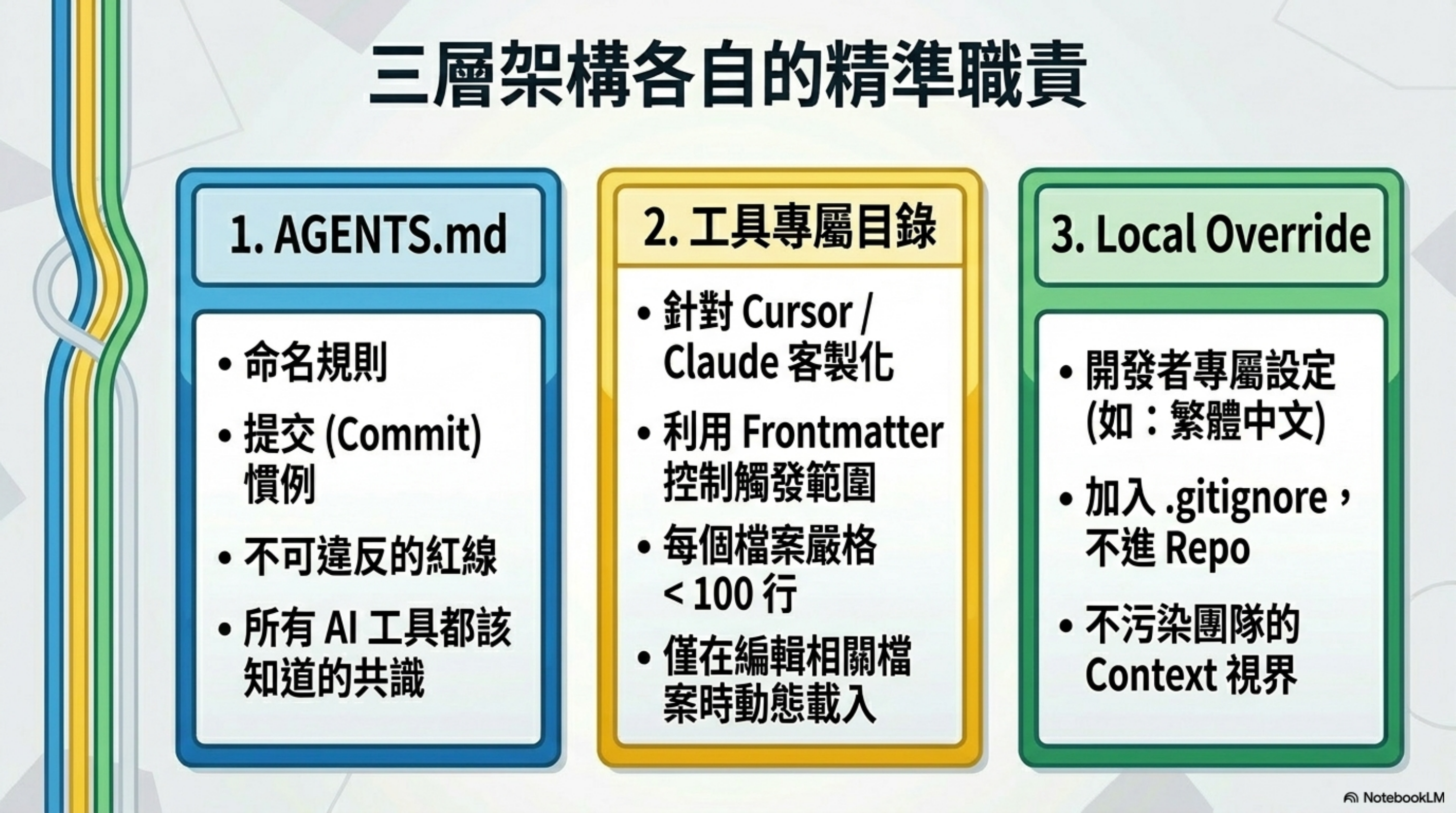
社群正在收斂到一個新的標準,跟 Walking Labs Harness Engineering 課程的 L04 主張幾乎完全一致:
1
2
3
4
5
6
7
8
9
專案根目錄/
├── AGENTS.md # 通用指令(所有 AI 工具都讀)
├── AGENTS.override.md # 本地覆寫(gitignored,不進 repo)
├── CLAUDE.md # symlink → AGENTS.md(保持同步)
├── .cursor/rules/ # Cursor 專用 .mdc 檔案
│ ├── frontend.mdc # 含 glob scope
│ ├── backend.mdc
│ └── tests.mdc
└── .claude/rules/ # Claude Code 專用(按 path scope)
三層結構解決三件事:
第一層(AGENTS.md):寫專案 high-level 約定
- 命名規則
- 提交慣例
- 不可違反的紅線
- 任何工具都該知道的事
第二層(工具專屬目錄):寫工具細節 + 檔案 scope
- 哪些檔案套用哪些規則
- 用 frontmatter 控制 scope
- 每個檔案不超過 100 行
- 只在相關的時候才載入
第三層(local override):寫個人偏好
- 不進 repo
- gitignored
- 給單一開發者使用
- 不污染團隊 context
關鍵在於:每一層都有明確的 scope,AI 只在相關的時候才讀。
這就是 Walking Labs 的精髓 —— 不是「寫得越完整越好」,是「在對的時候、給對的 AI、看對的規則」。
很多人會問:「那為什麼不全部寫進 AGENTS.md 就好?」
答案就是這整篇文章在講的事情:因為你寫越多,AI 越不照做。 你需要的不是「更大的指令檔」,是「更聰明的指令分配」。
我的實戰:1543 行該怎麼拆
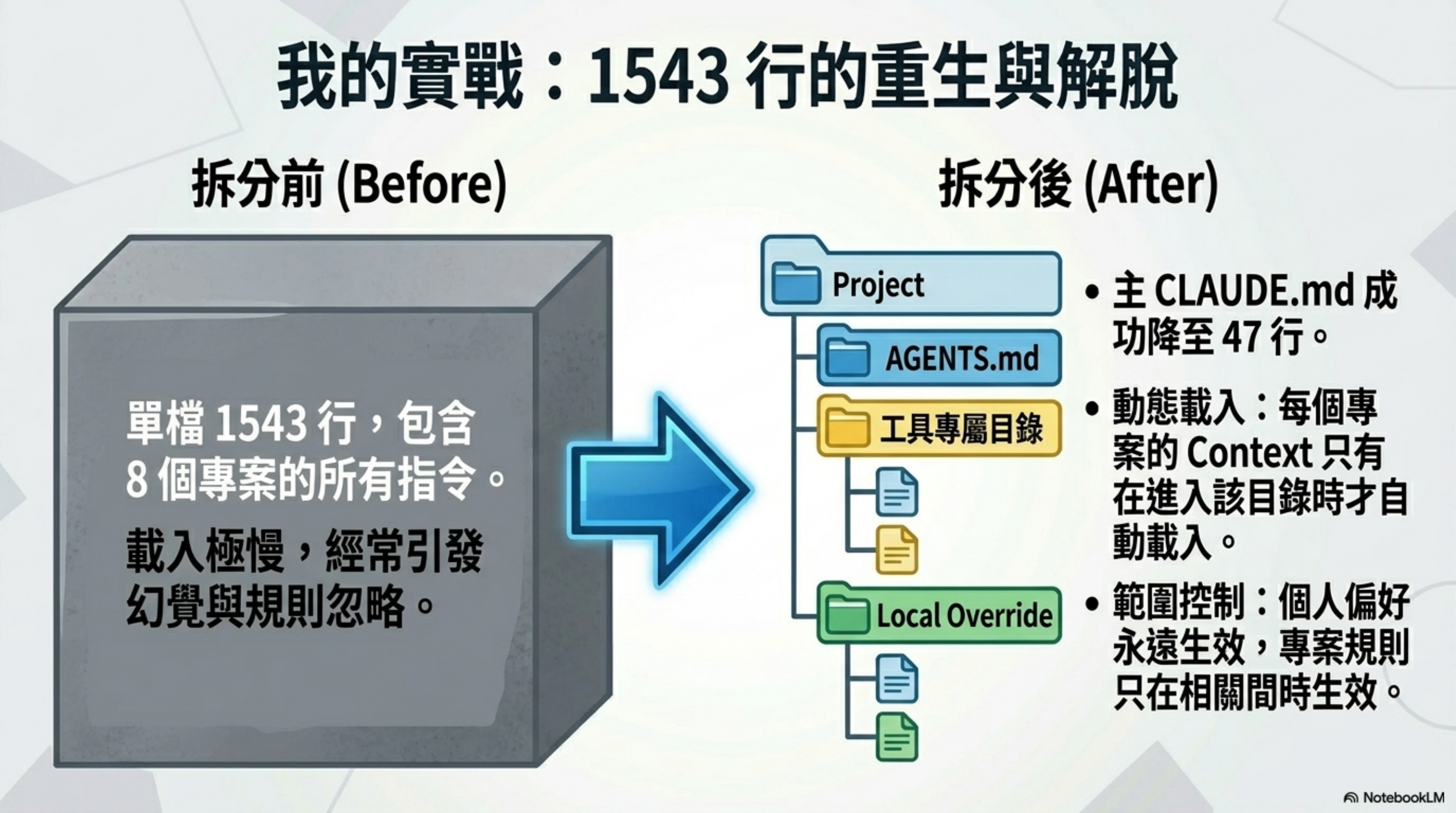
回到我自己的 CLAUDE.md。我做了一次徹底的拆分。
拆前(1543 行單檔):
1
~/CLAUDE.md # 全部塞一起,跨 8 個專案
拆後:
1
2
3
4
5
6
7
8
9
10
11
12
~/CLAUDE.md # 只保留個人偏好 + 跨專案紅線(~50 行)
├── 永遠用繁體中文
├── 不要主動 commit / push
├── 用 Read 再 Edit
└── 工程術語用英文
各專案/CLAUDE.md # 專案專屬規則(< 200 行)
├── /Desktop/cc/blog-content/CLAUDE.md # Jekyll 部署流程
├── /Desktop/cc/SEO/CLAUDE.md # BigQuery + GA4 設定
├── /Desktop/cc/XXX/CLAUDE.md # XXX 系統
├── /Desktop/cc/XXX/CLAUDE.md # XXX 專案
└── /Downloads/XXX/CLAUDE.md # XXX
主 CLAUDE.md:從 1543 行 → 47 行。 每個專案的 context 在我進入該目錄時自動載入。 個人偏好永遠生效、專案規則只在相關時生效。
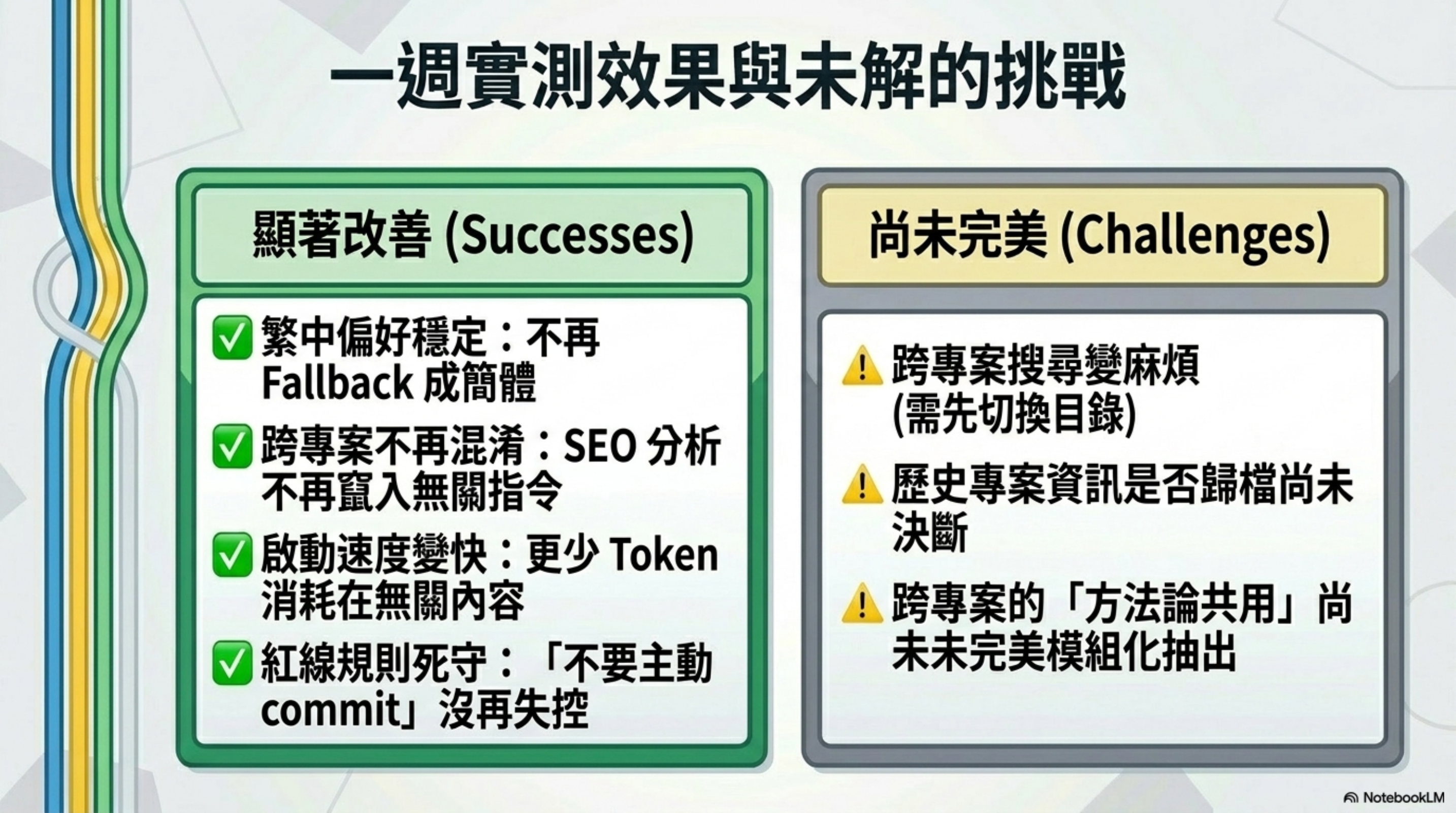
初步效果(一週實測):
- Claude 開始正確記得我的繁中偏好(過去常常 fallback 成簡體)
- 跨專案不再混淆(過去寫 SEO 分析時偶爾出現 Jingteng 的指令)
- Session 啟動速度可感地變快(更少 token 在載入無關內容)
- 紅線規則的遵守率明顯提升(「不要主動 commit」過去偶爾失守,現在沒再發生)
不是完美。但明顯比 1543 行的時代好太多。
坦白說沒解決的問題:
- 跨專案搜尋變麻煩(過去 Ctrl+F 一次找到所有專案資訊,現在要先進目錄)
- 部分歷史資訊(已完成的專案紀錄)我還沒決定要不要進 archive
- 不同專案之間的「方法論共用」(例如 ATPM 框架)還沒抽出來
這是一個進行中的工程,不是一個完成的答案。但方向是對的,這點我很確定。
結語:少即是多,分即是合

Harness Engineering 不是要你「寫更多規則」。是要你用對的結構安排規則。
洞察很簡單:
「指令的價值不在於『寫了什麼』,而在於『AI 真的能讀到、能執行的那部分』。」
回頭看 5 個真實案例:
- 200 行被全部忽略
- Anthropic 自己加錯一句話炸鍋 6 週
- MEMORY.md 超過 200 行直接消失
- Mr. Tinkleberry 被遺忘
- Cursor 官方宣告
.cursorrules死亡
這些都不是孤立事件。它們指向同一個結構性問題:單檔指令系統不夠用了。
如果你也有一個越寫越長的 CLAUDE.md,今天就跑一次 wc -l。
如果超過 200 行 —— 你不是在打造記憶系統,你是在打造一個被忽略的願望清單。
而願望,從來不會自己實現。
下一篇預告
Harness Engineering 實戰第二篇: L03 — 為什麼 Repo 才是 AI 的單一事實來源(Replit AI 把生產資料庫刪光的那一晚發生了什麼)
延伸閱讀
- Harness Engineering 架構全景:AI 可以寫 Code,但不能自己上 Production
- Harness Engineering 完整拆解:當 AI Agent 寫完 Code,你的 Repo 準備好自動接住了嗎?
- Opus 4.7「變笨」一個月之謎 —— Anthropic 終於承認是 Claude Code 的 harness
- 當 AI 把資料庫刪光:兩個真實案例與 Harness Engineering 的反擊
- Walking Labs - Learn Harness Engineering 課程
參考資料
- Anthropic Engineering, April 23 Postmortem: https://www.anthropic.com/engineering/april-23-postmortem
- Anthropic, Best Practices for Claude Code: https://code.claude.com/docs/en/best-practices
- DEV Community, I Wrote 200 Lines of Rules for Claude Code. It Ignored Them All.: https://dev.to/minatoplanb/i-wrote-200-lines-of-rules-for-claude-code-it-ignored-them-all-4639
- DEV Community, I Wrote 500 Lines of Rules. Here’s How I Made It Actually Follow Them.: https://dev.to/mikeadolan/i-wrote-500-lines-of-rules-for-claude-code-heres-how-i-made-it-actually-follow-them-3c8
- GitHub Issue, MEMORY.md silently drops entries past 200-line limit: https://github.com/anthropics/claude-code/issues/39811
- GitHub Issue, MEMORY.md has undocumented 200-line hard limit: https://github.com/anthropics/claude-code/issues/25006
- Cursor Docs, Rules: https://docs.cursor.com/context/rules
- Augment Code, How to Build Your AGENTS.md (2026): https://www.augmentcode.com/guides/how-to-build-agents-md
- alexop.dev, Stop Bloating Your CLAUDE.md: https://alexop.dev/posts/stop-bloating-your-claude-md-progressive-disclosure-ai-coding-tools/
- Walking Labs, Learn Harness Engineering 課程: https://walkinglabs.github.io/learn-harness-engineering/zh-TW/