Kalman Filter × Transformer:當「物理直覺」遇上「深度學習」

Kalman Filter × Transformer:當「物理直覺」遇上「深度學習」
這篇文章在講什麼
最近在追學術論文時,發現一個有趣的現象:Kalman Filter + Transformer 這個組合,突然變成熱門賽道。
不是那種「把兩個東西接起來」的 naive 做法,而是有一批嚴謹的研究,正在重新定義「狀態估計」這個老問題。
更有趣的是:這條線的邏輯,其實跟我們在做 AI Agent 時遇到的問題很像——
AI 很聰明,但有時候會「幻覺」。怎麼讓它既聰明又不亂來?
這篇文章會用工程師能懂的方式,拆解這個研究方向的核心邏輯。
先講結論:這不是 AI 突破,是 AI 被收編
一句話總結這波研究的定位:
Transformer + Kalman 不是 AI 技術突破,而是「深度學習被收編進工程理性」的過程。
或者更直白地說:
- Transformer:負責「看懂世界」
- Kalman:負責「對世界負責」
這不是誰取代誰,而是一個負責看趨勢,一個負責確保物理上合理。
Kalman Filter 是什麼?用 30 秒講完
如果你完全不知道 Kalman Filter,這裡快速補課。
一句話版本:
在「有雜訊、不確定」的情況下,持續估計系統真實狀態的最佳方法。
它回答的問題是:
我現在量到的數據不準,那「真實狀態」最可能是什麼?
Kalman Filter 每次做兩件事
1. 預測(Predict)
根據「上一刻的狀態 + 系統模型」,先猜現在會變成什麼樣。
例如:昨天在這裡、速度是 10 m/s → 今天大概在那裡
2. 校正(Update)
用「實際量測」來修正剛剛的猜測。
例如:GPS 說你在 A,但 GPS 很吵 → 不全信,只修一點
關鍵不是信誰,而是「根據不確定性加權」。
為什麼它厲害?
因為它同時考慮三件事:
- 系統模型(我知道物理怎麼走)
- 量測雜訊(感測器有多爛)
- 不確定性傳遞(誤差會累積)
在「線性 + 高斯雜訊」假設下,數學上是最優解。
那 Transformer 的問題是什麼?
這就要講到這波研究的核心洞察。
Feature ≠ Latent State
這是這批論文反覆強調的一件事:
| 概念 | Transformer 學的 | Kalman 在做的 |
|---|---|---|
| 本質 | Feature correlations | 物理狀態估計 |
| 輸出 | 預測值 | 狀態 + 不確定性 |
| 假設 | 資料驅動 | 物理模型驅動 |
| 限制 | 可能 hallucinate | 假設太強、彈性不足 |
白話翻譯:
- Transformer 很會看「資料長怎樣」
- 但它不知道「現實世界不能亂來」
例如:
- 車速突然跳 100 km/h?
- Transformer:可能喔
- Kalman:不可能,修掉
用生活例子講清楚
你現在在做一件事:用手機導航開車
你其實同時在用兩種能力:
1. 直覺派(Transformer)
- 看地圖
- 記得剛剛怎麼走
- 推測接下來會不會塞車
很聰明,但有時會腦補過頭
2. 理性派(Kalman)
- 車不可能瞬間移動
- 速度變化有極限
- GPS 會飄,要修正
很保守,但很可靠
現在學界做的事,就是把這兩個人放在同一台車上。
那 Transformer 到底負責什麼?
從最近的論文來看,Transformer 在這個組合裡有三種角色:
路線 A:學 Kalman Gain(最主流)
代表作:KalmanFormer(2024, Frontiers in Neurorobotics)
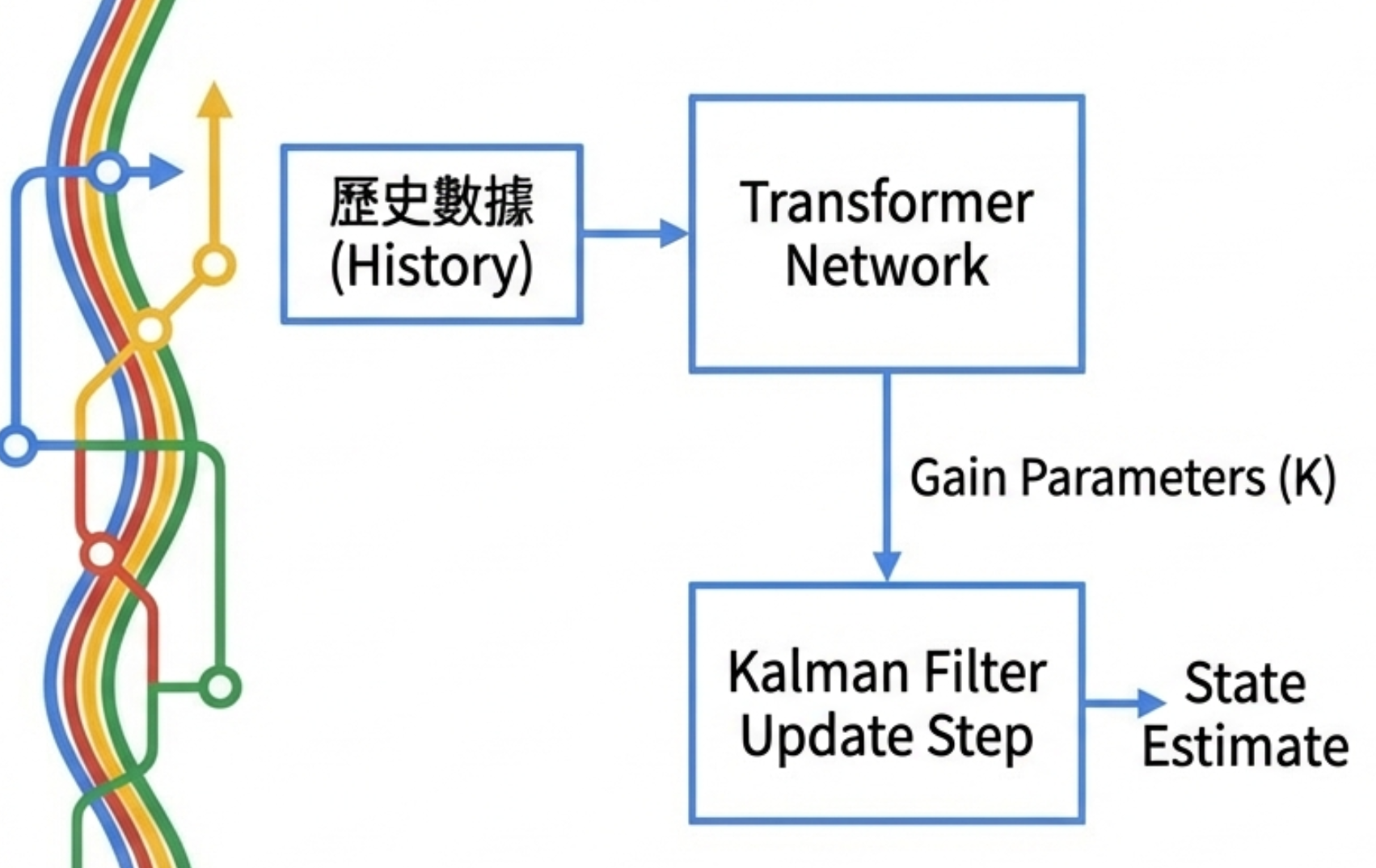
做法:
- Kalman Filter 的結構不動
- 不再假設已知 Q / R / 噪聲分佈
- 讓 Transformer 從歷史誤差與觀測中,直接學 Kalman Gain
Kalman Gain 是什麼?就是「要信資料多少」的比例。
這個比例本來超難調,現在交給 Transformer 從歷史經驗學。
為什麼這個做法紅?
因為它保留了狀態空間的可解釋性,但把「最難調、最不穩的那一塊」交給資料學。
在模型不匹配、非線性、多感測器的場景,它明顯贏 EKF / UKF。
路線 B:學 Dynamics / Noise(A-KIT)
代表作:A-KIT: Adaptive Kalman-Informed Transformer(2024, arXiv)
這類做法是:
- Transformer 參與狀態轉移 / 觀測映射
- 但更新仍然走 Kalman-style Bayesian update
關鍵不是 performance,而是:
讓深度模型「被迫服從狀態空間假設」
這一派很重視:stability、long-horizon error 不爆炸、推論時可控。
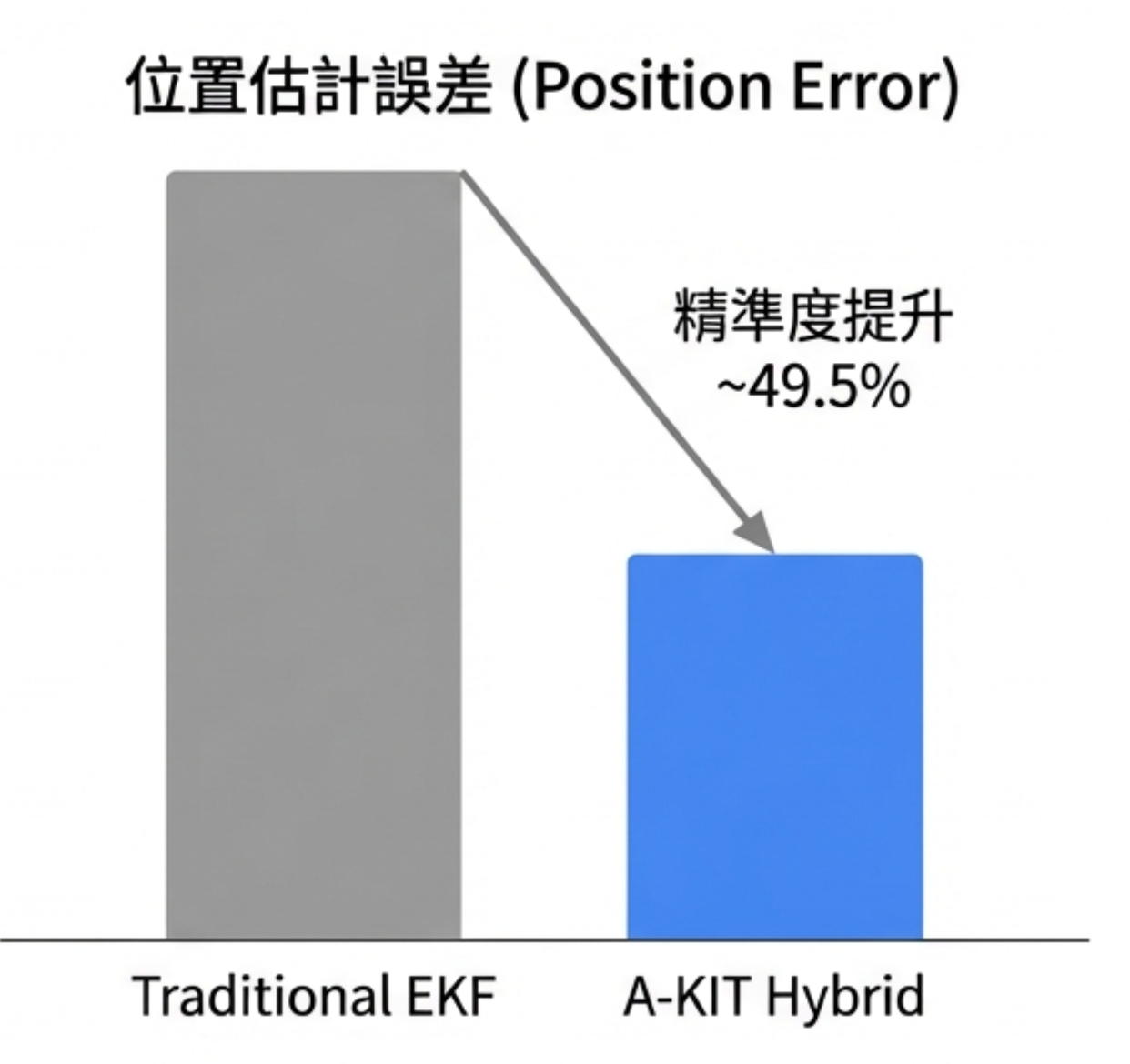
實驗上,在自主水下載具導航的真實資料上,比傳統 EKF 提升了約 49.5% 的位置精度。
路線 C:工程應用派
應用場景包括:
- MOT tracking(多目標追蹤)
- Inertial navigation(慣性導航)
- Orbit determination(軌道預測)
- Battery SOH(電池健康狀態預測)
共通點是:
- 真實世界噪聲極爛
- 不能純 end-to-end
- 工程上一定要「狀態可審計」
這些論文幾乎都遵守一個隱性規則:
Transformer 負責「看懂世界」,Kalman 負責「對世界負責」
產業例子:智慧物流 ETA 預測
讓我用一個更接地氣的例子來說明。
一家物流公司想做兩件事:
- 預測每台車的 ETA(到達時間)
- 即時調度(改路線、插單)
資料來源很亂:GPS(會飄)、車速感測器(會壞)、路況 API(延遲)、人為操作(司機亂停)
只用 Transformer(很多公司真的這樣做)
把歷史 GPS、速度、時間、路況全丟進 Transformer,直接 end-to-end 預測 ETA。
一開始看起來很棒:
- 離線驗證準
- Demo 很漂亮
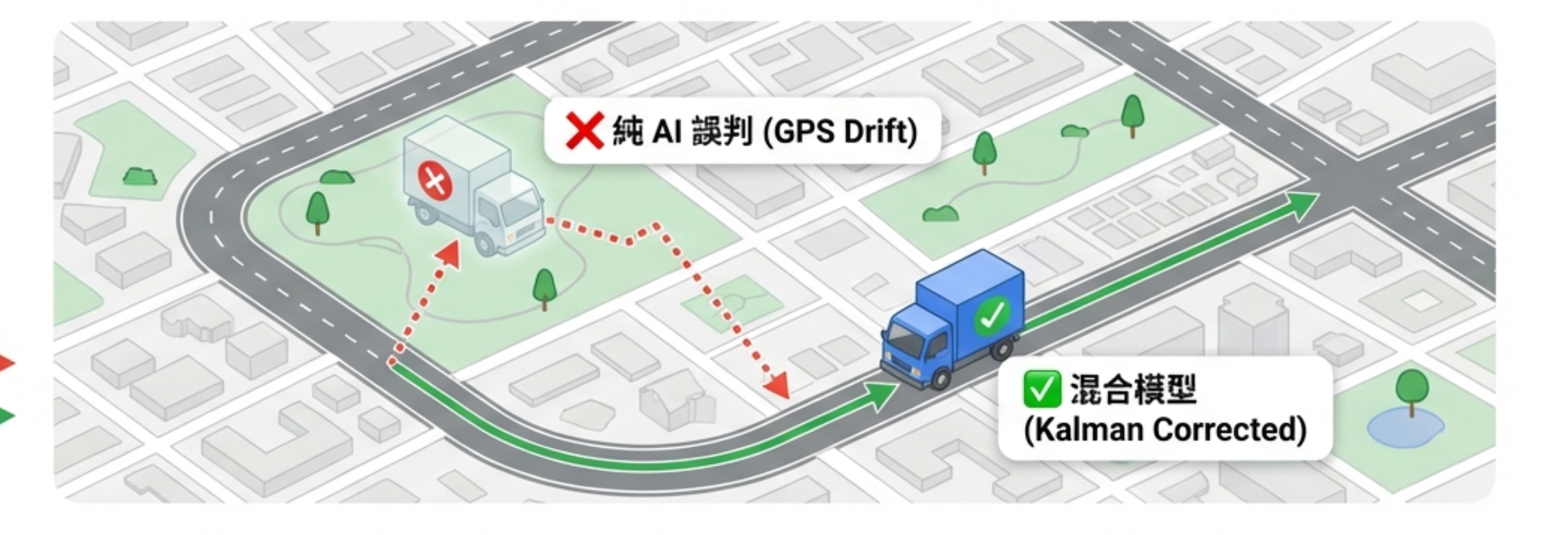
但上線後會出事:
- GPS 飄一下 → ETA 瞬間跳 30 分鐘
- 車實際停著 → 模型還以為在移動
- 系統信模型 → 調度亂插單
只用 Kalman(傳統派)
用 Kalman Filter,假設固定速度模型 + 噪聲。
優點: 穩、不會亂跳、解釋得出來 缺點: 遇到塞車、事故、非典型路段 → 反應慢、太保守
Transformer + Kalman(推薦做法)
分工非常清楚:
| 角色 | 負責 | 輸出 |
|---|---|---|
| Transformer | 看懂趨勢 | 這筆資料可信嗎?變化可能多大? |
| Kalman | 狀態估計 | 車的真實位置與速度 |
Transformer 學的是:
- 這條路段什麼時間常塞
- 這個司機的行為模式
- GPS 在這區域通常多爛
輸出不是 ETA,而是:「這筆資料可信嗎?接下來變化可能多大?」
Kalman 永遠堅守幾件事:
- 車不可能瞬移
- 速度變化有物理上限
- 不確定性要被記錄
最後 ETA 由 Kalman 算,Transformer 只影響「要信資料多少」
為什麼這波研究「好發」?
很現實的原因:
| 條件 | 說明 |
|---|---|
| 問題老 | 狀態估計、Tracking、Filtering,審稿人完全懂 |
| 方法新 | Transformer ≠ 當 predictor,而是嵌進 Bayesian estimator |
| 基線清楚 | KF / EKF / UKF 全部是硬基線,不像純 DL 容易被質疑「調參調贏」 |
| 審稿友善 | 有物理意義、有不確定性、有解釋性 |
這就是為什麼這條線比很多 end-to-end DL 還好發。
工程觀點:為什麼這是「安全」的技術投資?
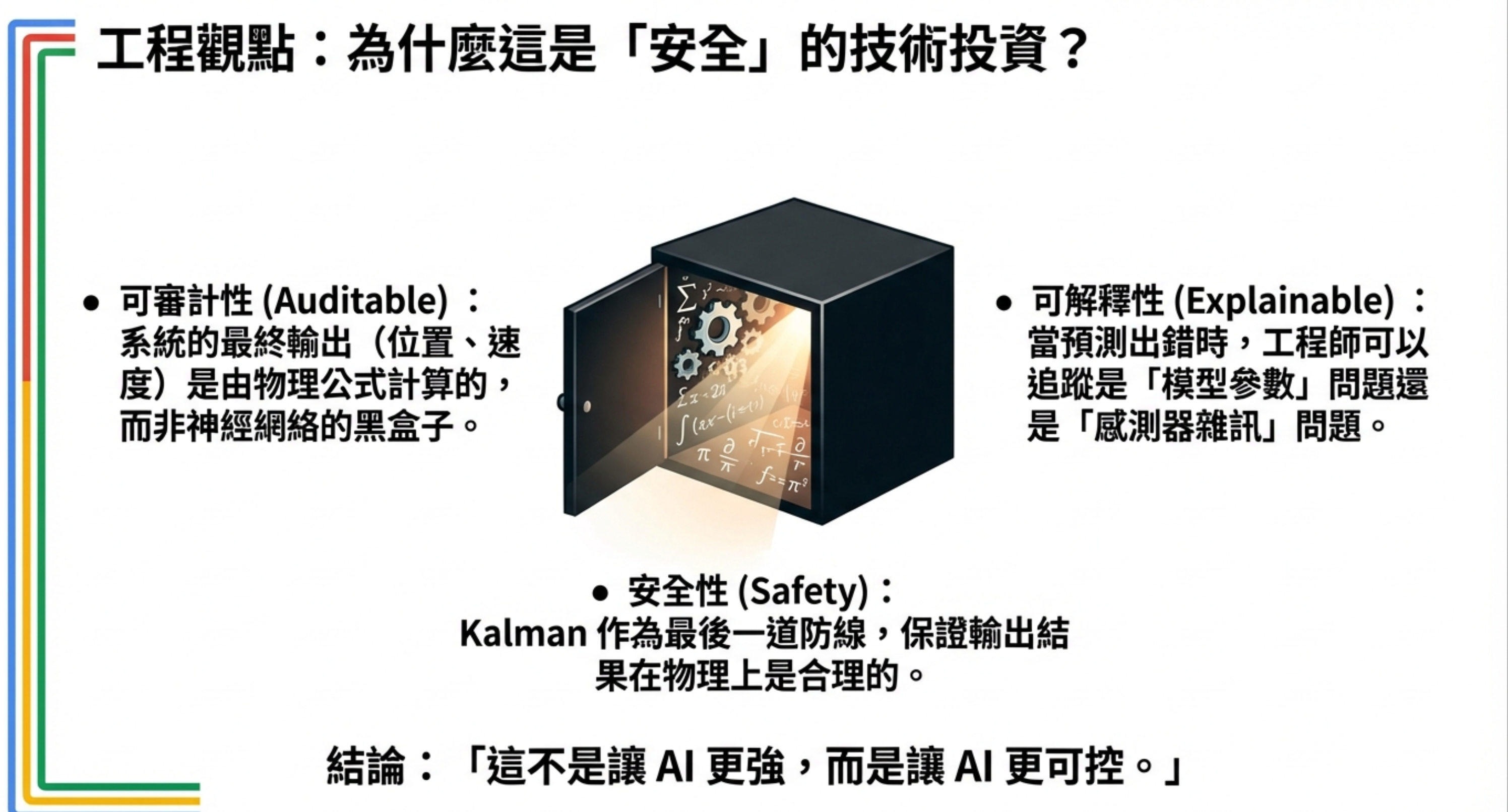
這個組合的價值,不是讓 AI 更強,而是讓 AI 更可控。
可審計性(Auditable)
系統的最終輸出(位置、速度)是由物理公式計算的,而非神經網絡的黑盒子。
當老闆問「為什麼 ETA 變了?」你可以打開狀態向量,逐步解釋每一步的推導。
可解釋性(Explainable)
當預測出錯時,工程師可以追蹤是「模型參數」問題還是「感測器雜訊」問題。
這對除錯至關重要——你知道要調 Transformer 還是調 Kalman。
安全性(Safety)
Kalman 作為最後一道防線,保證輸出結果在物理上是合理的。
車不會瞬移、速度不會負值、不確定性會被追蹤。這些都是 end-to-end 模型無法保證的。
結論
這不是讓 AI 更強,而是讓 AI 更可控。
核心論文整理
如果你想深入,這幾篇是這個方向的代表作:
| 論文 | 核心貢獻 | 應用場景 |
|---|---|---|
| KalmanFormer | Transformer 學 Kalman Gain | 多感測器融合 |
| A-KIT | Transformer 學噪聲協方差 | 水下載具導航(+49.5% 精度) |
| Transformer+LSTM+EM-KF | 序列模型輔助參數估計 | 時間序列預測 |
| Can Transformer Represent KF? | 理論分析 Transformer 表達能力 | 理論研究 |
關鍵洞察
-
Transformer + Kalman 不是「誰取代誰」,而是分工:Transformer 看趨勢,Kalman 保證物理合理
-
Feature Space ≠ Latent State Space:Transformer 學的是 pattern,不是真實狀態
-
這是「AI 被收編進工程理性」的過程:不是讓 AI 更強,而是讓 AI 更可控
-
審稿友善 = 問題老 × 方法新 × 基線硬:這是為什麼這條線最近很熱
-
適用場景:需要「可解釋 + 穩定 + 物理合理」的系統
常見問題 Q&A
Q: 這跟 Agent 的「Guardrails」概念有什麼關係?
其實核心邏輯很像。Guardrails 是「讓 LLM 不要亂來」,Kalman 是「讓狀態估計不要亂來」。兩者都是在「AI 能力」之外加上「工程約束」。
Q: 我不做追蹤 / 導航,這跟我有關嗎?
如果你做時間序列預測、多感測器融合、或任何「輸入有噪音」的場景,這個框架都值得參考。核心思想是:不要讓 AI 完全自由發揮,要給它物理約束。
Q: 這會取代傳統 Kalman Filter 嗎?
不會。這是「增強」而非「取代」。傳統 KF 在模型準確、噪聲已知的場景還是最優解。Transformer 的加入是為了處理「模型不準」或「噪聲會變」的場景。
延伸閱讀
- Agent 模式 Part 3:Autonomous & Cyclic Agent - 類似的「控制 + 學習」雙系統架構
- PostgreSQL 作為 AI 記憶庫 - 另一種「用傳統工具約束 AI」的思路
- Google Nested Learning - 另一個把傳統理論帶回深度學習的研究方向
這篇文章更偏向「技術探討」而非「實戰總結」。我們還沒有完整的生產案例,但這個方向的邏輯很清楚:AI 越強,越需要「剎車系統」。Kalman,就是那個剎車。