Langfuse 架構演進:為什麼從全 PostgreSQL 走向 ClickHouse,但 RLS 場景 PostgreSQL 仍是王者

當 Langfuse 在 2024 年底宣布 v3 架構大改,把 traces、observations、scores 從 PostgreSQL 遷移到 ClickHouse,很多人以為這是「PostgreSQL 不行了」的訊號。
但實際上,這是一個經典的 技術 Tradeoff 案例。
先聊聊 Langfuse 是什麼
如果你在做 LLM 應用開發,應該聽過 Langfuse。
簡單講,Langfuse 是一個 開源的 LLM 可觀測性平台,GitHub 上超過 19,000 顆星,MIT License 可以自由 self-host。
為什麼需要 LLM Observability?
傳統軟體除錯靠 log 和 stack trace。但 LLM 應用不一樣——它是 non-deterministic(非確定性)的。
同樣的 prompt,今天跑和明天跑可能得到不同結果。沒有 observability 工具,除錯基本上是猜的。
Langfuse 提供什麼?
| 功能 | 說明 |
|---|---|
| Tracing | 完整記錄每個 request:prompt、response、token usage、latency、tool calls |
| Prompt Management | 版本控制、協作迭代,不用改 code 就能換 prompt |
| Evaluations | LLM-as-a-Judge、user feedback、manual labeling |
| LLM Playground | 直接在 tracing 裡跳到 playground 測試修改 |
| 50+ 整合 | Python/JS SDK、OpenTelemetry、LangChain、LiteLLM… |
根據 Langfuse 官方文件,它的核心價值是:
讓你能追蹤 LLM 應用的每一個步驟——從 prompt 到 output,包括 retrieval、embedding、API calls。
這對除錯、成本追蹤、合規 audit 都很關鍵。
Langfuse v2 → v3:為什麼要換架構?
根據 Langfuse 官方 Blog,到 2024 年中,他們的 PostgreSQL 架構已經撐不住了:
- billions of rows 的 tracing 資料
- 複雜的 aggregation 查詢跨多個 UI
- 快速擴張的客戶產生海量資料
原本簡單的 PostgreSQL 架構,同時支撐 Cloud 和 Self-hosted 版本,開始出現嚴重瓶頸。
問題出在哪?
PostgreSQL 是 row-based storage,對於 OLTP(交易處理)場景非常強。但當你要處理:
- 數十億行的 tracing 資料
- 時間序列的 aggregation 查詢
- 高吞吐量的寫入
這時候 row-based 的設計就變成劣勢了——查詢時間變長、資源消耗變高。
新架構長什麼樣?
Langfuse v3 的架構變成:
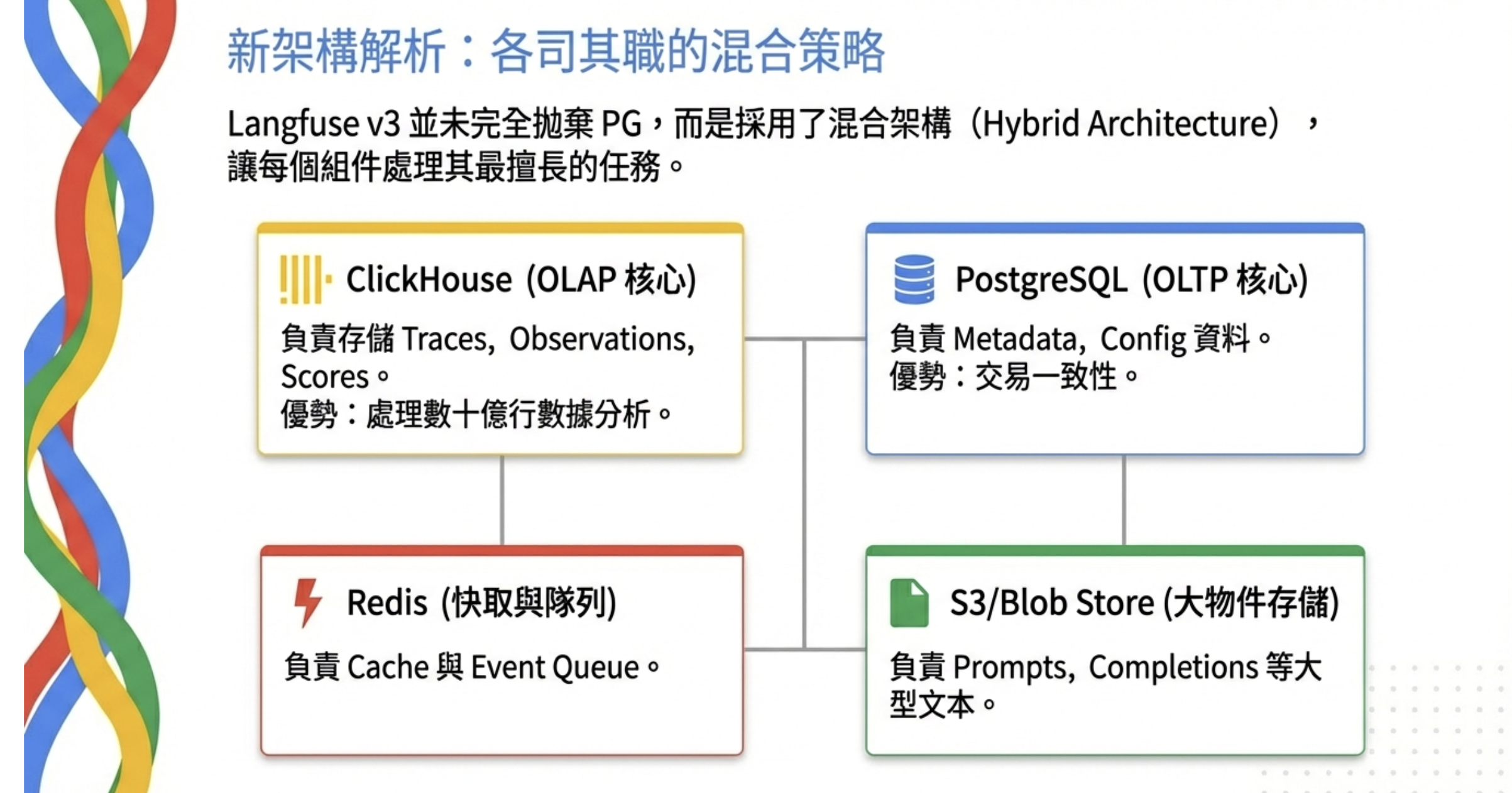
| 元件 | 用途 |
|---|---|
| ClickHouse | OLAP 儲存(traces, observations, scores) |
| Redis | 快取 + 事件佇列 |
| S3/Blob Store | 大型物件儲存(prompts, completions) |
| PostgreSQL | 保留給 metadata 和設定資料 |
| Async Worker | 非同步處理事件 |
根據 ClickHouse 官方案例,這個架構讓他們能處理「billions of rows」的客戶資料,而且超過 1,000+ self-hosted 部署已經在生產環境運行。
但是:PostgreSQL RLS 的優勢是原生的
這裡有個關鍵點:Langfuse 的架構改動是針對 OLAP 場景。
如果你的需求是 多租戶資料隔離、交易安全、CRUD API 直接暴露給前端,PostgreSQL 的 Row-Level Security (RLS) 仍然是王者。
RLS 對比表
| 特性 | PostgreSQL RLS | ClickHouse RLS |
|---|---|---|
| 主要用途 | 應用程式邏輯隔離、交易安全 | 多租戶數據分析隔離 |
| 寫入保護 | ✅ 強制檢查 (WITH CHECK) | ❌ 主要是讀取過濾 |
| 效能風險 | ⚠️ 高(若規則複雜會拖垮 DB) | 🟢 低(基於列式過濾,速度快) |
| 動態參數 | current_setting('app.tenant_id') |
getSetting('custom_tenant_id') |
| 最適合場景 | 直接給前端用的 CRUD API(如 Supabase) | 為不同客戶提供 Analytics Dashboard |
為什麼 PostgreSQL RLS 更安全?
根據 Svix 的 RLS 深度分析:
RLS 提供 defense in depth(縱深防禦):即使你的程式碼有 bug,資料庫也不會回傳或修改租戶範圍外的資料。
這是 ClickHouse 無法做到的。ClickHouse 的 RLS:
- 不支援 correlated subqueries
- 沒有 UPDATE 語句(mutation 很貴)
- Session role 切換需要管理並發
根據 AWS 的多租戶指南,PostgreSQL RLS 是「將隔離策略強制執行在資料庫層級」的最佳實踐。
第三條路:PostgreSQL 全覆蓋 + 擴展方案
所以結論是什麼?
如果你的需求是:
- LLM observability 的完整 log 追蹤
- 需要 audit trail 和可解釋性
- 多租戶 RLS 隔離是硬需求
PostgreSQL 仍然可以做全覆蓋。
但當資料量太大的時候,你可以選擇:
方案 A:TimescaleDB
TimescaleDB 是基於 PostgreSQL 的時間序列擴展:
- Hypertables:自動按時間分區,查詢只掃描相關 chunks
- Continuous Aggregates:增量刷新,不用每次全表掃描
- 壓縮:30-40% 儲存空間減少
- 效能:比原生 PostgreSQL 快 200 倍(根據 TigerData 官方)
適合場景:IoT、metrics、monitoring、LLM tracing logs
方案 B:ParadeDB
ParadeDB 是基於 Tantivy(Rust 版 Lucene)的 PostgreSQL 擴展:
- Columnar storage:適合分析查詢
- Full-text search:可以取代 ElasticSearch
- 與 pgvector 整合:支援 hybrid search
適合場景:搜尋導向的 log 分析、需要全文檢索的 observability
對比表
| 特性 | TimescaleDB | ParadeDB |
|---|---|---|
| 主要用途 | 時間序列資料 | 全文搜尋 + 分析 |
| 架構 | Hypertable 按時間分區 | Columnar storage + 搜尋索引 |
| 適合 | IoT、metrics、tracing | 搜尋、ElasticSearch 替代 |
| 與 PG 整合 | 完全相容 RLS | 完全相容 RLS |
實務建議:什麼時候該用哪個?
情境 1:小規模 Self-hosted Langfuse
建議:直接用 PostgreSQL
- 資料量 < 100GB
- 不需要複雜的 aggregation
- RLS 隔離是硬需求
情境 2:中規模,需要時間序列分析
建議:PostgreSQL + TimescaleDB
- 資料量 100GB - 1TB
- 需要按時間範圍查詢
- 需要保留 RLS 能力
情境 3:大規模,需要全文搜尋
建議:PostgreSQL + ParadeDB + S3
- 資料量 > 1TB
- 需要搜尋 prompts/completions
- 可以把冷資料移到 S3
情境 4:超大規模,純分析場景
建議:跟 Langfuse v3 一樣,PostgreSQL + ClickHouse 混合
- 資料量 > 10TB
- 不需要 RLS(或另外處理)
- 主要是 analytics dashboard
關於 AI 可解釋性與 Audit Trail
這裡要強調一個常被忽略的點:為什麼 log 架構選擇這麼重要?
高風險 AI 系統的提供者必須保留自動生成的 logs 至少六個月。
這不是技術問題,是合規問題。
Audit Trail 需要什麼?
- Prompt history:使用者輸入了什麼
- Model decisions:模型決策過程
- Output modifications:輸出被修改了什麼
- Guardrail executions:護欄觸發了什麼
- Administrator actions:管理員做了什麼
這些 logs 必須是:
- Encrypted:加密儲存
- Access-restricted:存取控制
- Preserved:依法規保留
為什麼 PostgreSQL RLS 在這裡更強?
因為 RLS 可以確保:
即使有 bug,資料庫也不會回傳租戶範圍外的 audit logs。
這是 defense in depth。ClickHouse 的 RLS 主要是讀取過濾,不是寫入保護。
結論
Langfuse 從全 PostgreSQL 改成 ClickHouse + Redis + PostgreSQL 混合架構,是為了解決 OLAP 規模問題。
但這不代表 PostgreSQL 不行了。相反地:
- RLS 場景:PostgreSQL 仍然是最強的選擇
- Audit Trail:PostgreSQL 的 defense in depth 更可靠
- 中小規模:PostgreSQL + TimescaleDB/ParadeDB 足以應付
技術選擇永遠是 trade-off。
不是「最新的最好」,而是「最適合你的場景的最好」。
參考資源
- Langfuse v3 Infrastructure Evolution
- Langfuse and ClickHouse: A new data stack
- PostgreSQL RLS for Multi-Tenant Applications
- Row Level Security: Defense in Depth
- AWS Multi-tenant Data Isolation with PostgreSQL RLS
- TimescaleDB GitHub
- The AI Audit Trail: Compliance and Transparency
這篇文章不是要說 ClickHouse 不好,而是要強調:在 RLS、audit trail、合規需求的場景下,PostgreSQL 的設計哲學仍然是最可靠的選擇。