Loop Engineering 實作指南:五個組件 + 一個記憶體,讓 Agent 自己跑起來

上一篇我們拆解了 Loop Engineering 的三個來源定義,劃了一條邊界線:哪些工作該 Loop 化,哪些不該。
這篇講實作。
上一篇寫完之後,我把 Codex 和 Claude Code 的 Loop 相關功能都實際跑了一輪。概念不難,但「能跑起來的 Loop」和「看起來像 Loop 的一次性腳本」之間的差距,全在細節裡。
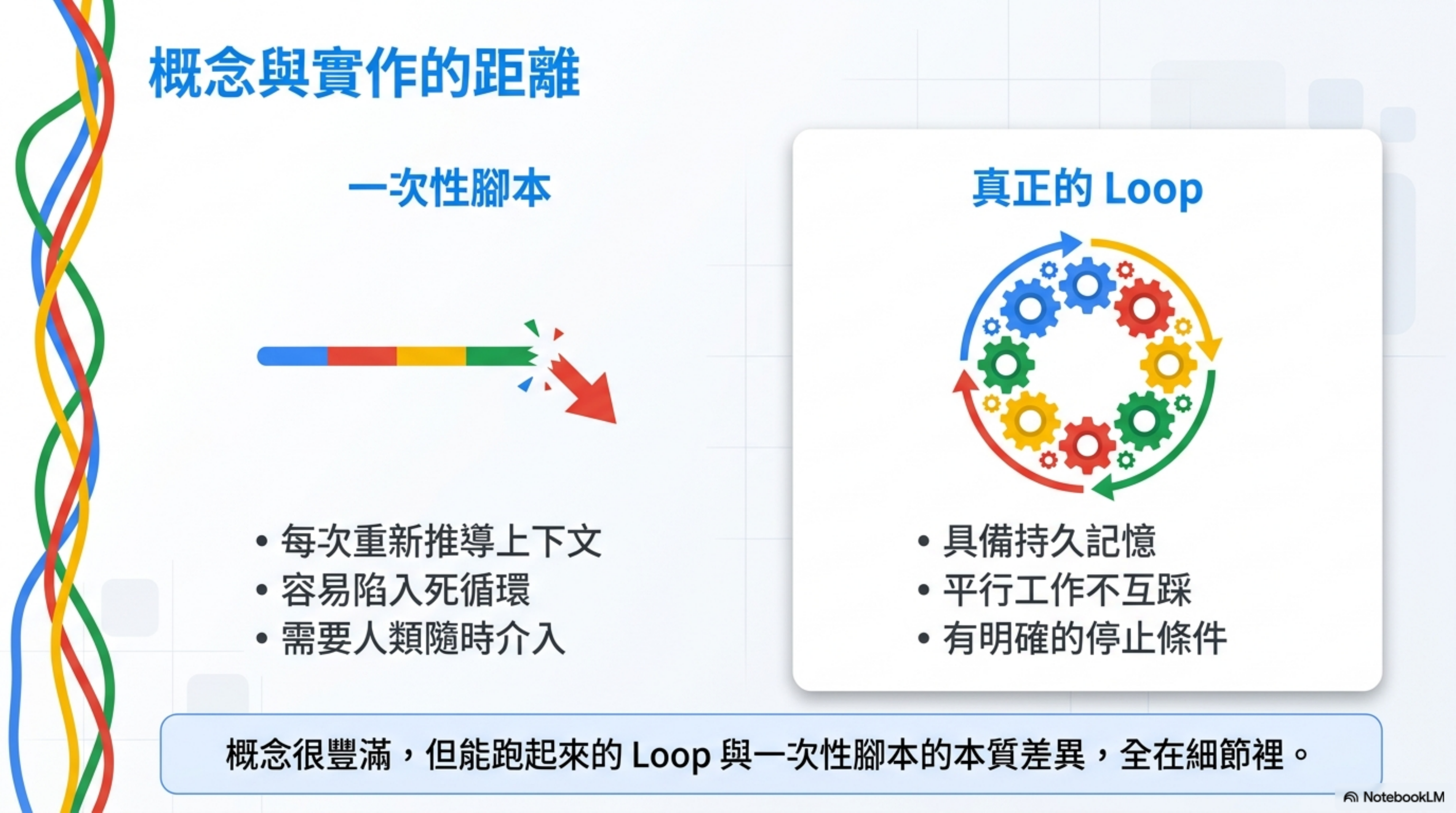
所以這篇不談理論,逐個組件拆解:它是什麼、怎麼設、我自己的使用經驗裡哪些有效哪些踩了坑。
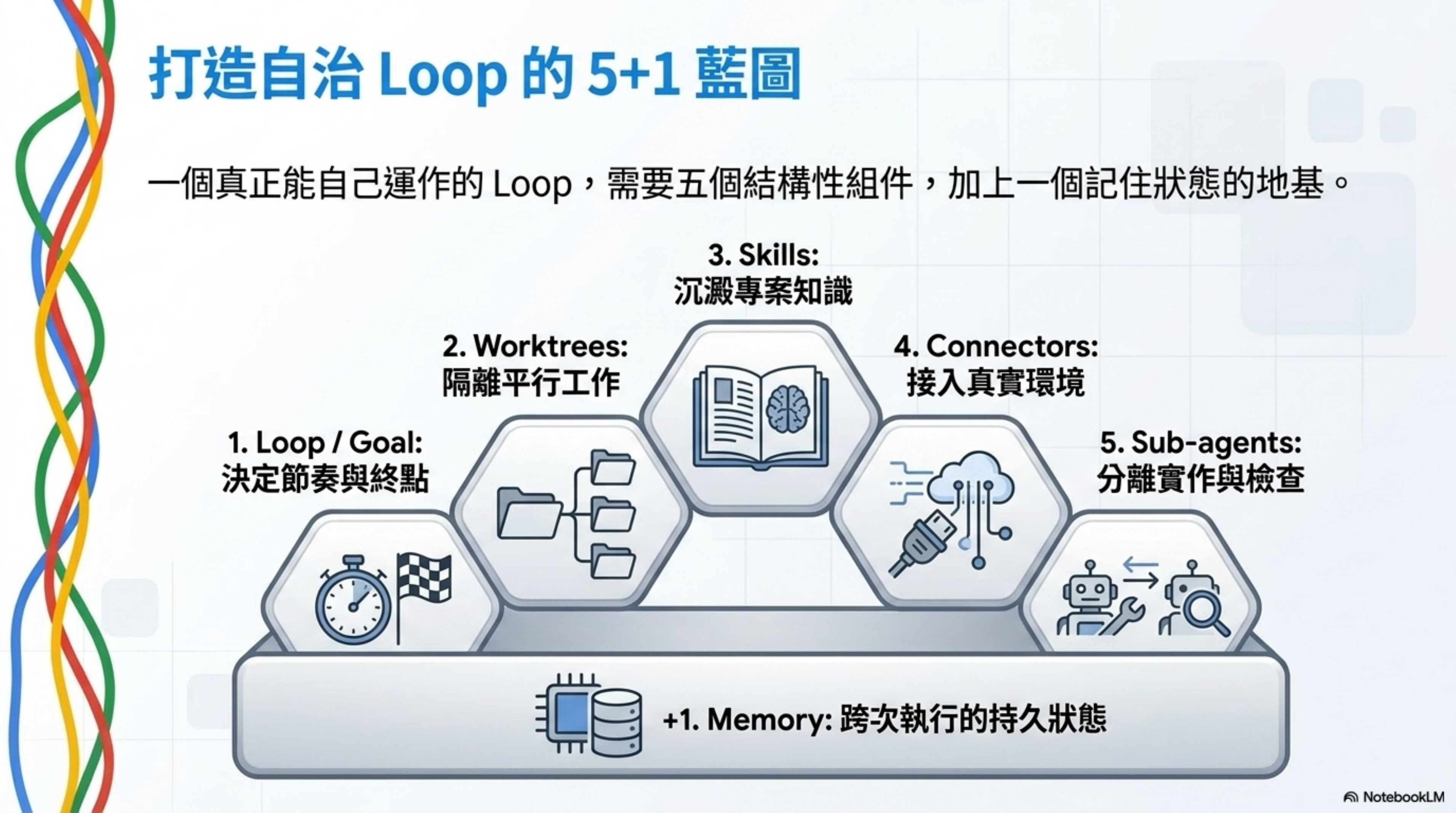
先畫全景:一個 Loop 需要什麼
一個能自己跑的 Loop 需要五樣東西,加上一個記住狀態的地方:
| # | 組件 | 一句話 |
|---|---|---|
| 1 | Loop / Goal | 決定迴圈怎麼跑、什麼時候停 |
| 2 | Worktrees | 讓平行工作的 agents 不會互相踩到對方 |
| 3 | Skills | 把專案知識寫下來,避免 agent 靠猜 |
| 4 | Connectors | 把 agent 接入你已經在用的工具 |
| 5 | Sub-agents | 一個 agent 提想法,另一個 agent 檢查它 |
| +1 | Memory | 跨次執行的持久狀態——agent 會忘記,但 repo 不會 |
每一個組件的「能用」和「好用」之間,都有一段距離。
組件 1:Loop / Goal——迴圈怎麼跑、什麼時候停

Loop Engineering 之所以叫 Loop,是因為 agent 不只跑一次。但「重複跑」有兩種本質不同的模式,搞混了會出事。
/loop——按節奏反覆跑
/loop 是按固定 cadence 反覆執行同一個 prompt 或 command。每隔 N 分鐘醒來一次,做一輪檢查,回報結果。
適合的場景是巡檢型任務——沒有明確的「完成」定義,需要持續監控:
- 每 5 分鐘檢查 CI 狀態
- 每小時掃一次 open issues 有沒有新的 high-priority
- 定期檢查 staging 環境是否正常
/loop 不會自己停。它是一個心跳,你決定節奏,它負責跳。
/goal——跑到條件成立為止
/goal 是完全不同的模式。你給它一個可驗證的停止條件,它一直跑到條件成立:
1
all tests in test/auth pass and lint is clean
然後你就可以離開。
這裡有一個關鍵的設計:判斷條件是否成立的,不是寫代碼的那個 agent。 一個獨立的小模型負責檢查——maker 和 checker 從停止條件本身就開始分離。
適合的場景是收斂型任務——有明確的「完成」定義,需要迭代直到達標:
- 修一個 bug 直到測試通過
- 重構一段代碼直到符合 spec
- 產生文件直到覆蓋所有 API endpoint
選錯模式的代價
用 /loop 做收斂型任務:agent 每輪都重新開始,不記得上一輪試過什麼,可能反覆嘗試同一個失敗的方向。
用 /goal 做巡檢型任務:如果條件永遠不會「完成」(比如「沒有新 bug」——明天就會有),loop 永遠不停,帳單失控。
一句話:有終點的用 /goal,沒終點的用 /loop。
Stop Condition 怎麼設
/goal 的停止條件直接用自然語言寫在 prompt 裡,但必須是可驗證的——不是「代碼品質變好」,而是「all tests pass and lint is clean」。判斷條件是否成立的是一個獨立的小模型,不是寫代碼的那個 agent 自己說了算。這就是 maker/checker 分離被應用到「loop 該不該繼續跑」這個決策本身。
/loop 本身不會自己停,所以你必須設三道保險:
- Budget cap——token 預算用完就停。Claude Code 的 workflow 裡可以用
budget.remaining()檢查剩餘額度,歸零就中斷。 - 收斂檢測——連續 N 次沒有新發現就停。寫在 prompt 裡:「if no new issues found for 3 consecutive runs, stop」。
- 時間上限——跑超過 X 分鐘就停。這是 Karpathy 定義 Loop 的第三要素:每次實驗有固定時間限制。
三道保險缺任何一道,你睡覺的時候 Loop 也在跑,醒來帳單可能已經三位數了。
Codex 和 Claude Code 都有這兩個 primitive,行為一致。Codex 的 /goal 額外支援 pause、resume、clear。
組件 2:Worktrees——平行 Agent 不互踩的基礎
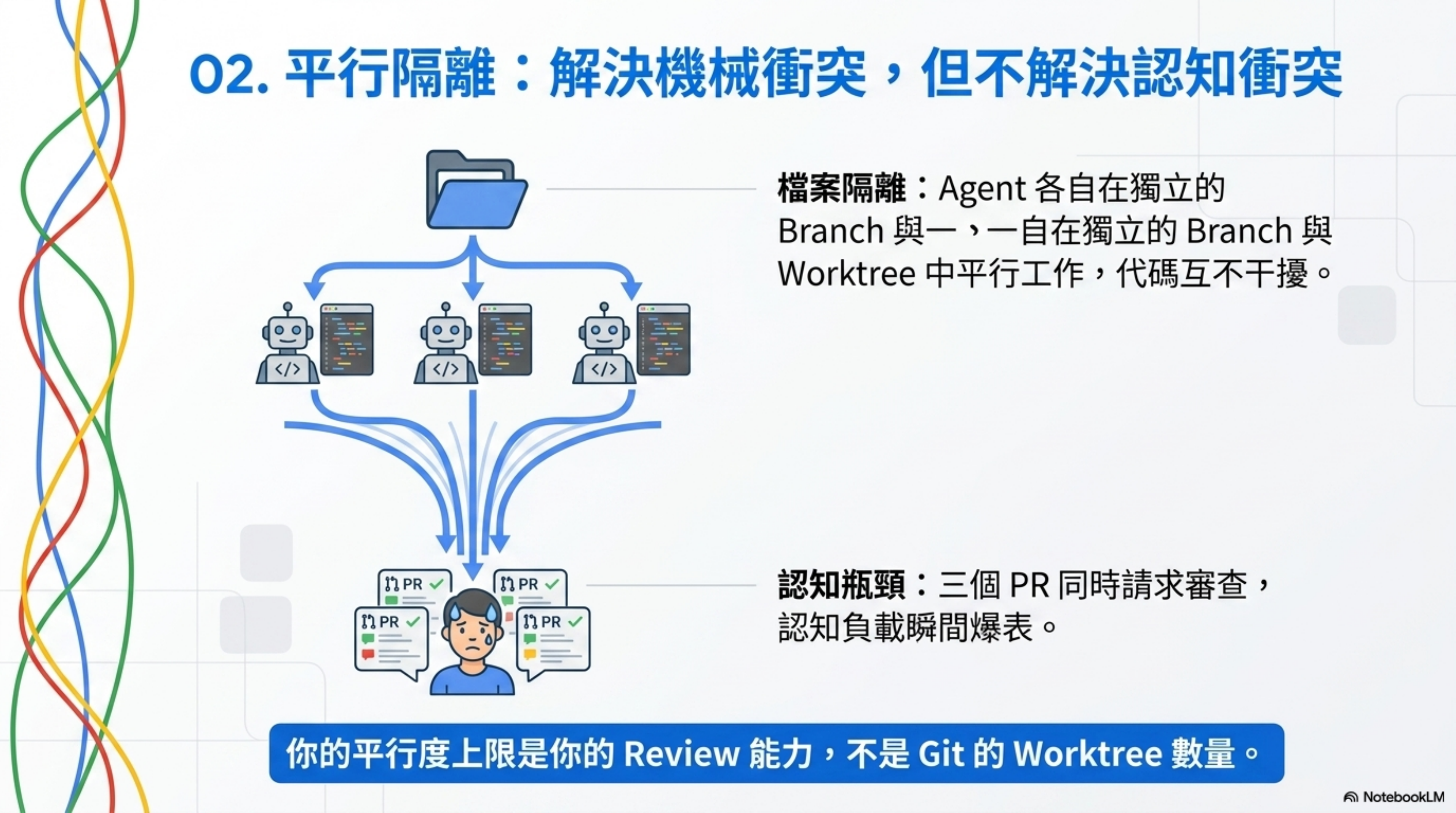
只要你同時跑不止一個 agent,檔案就會開始衝突。
兩個 agents 同時改同一個檔案,本質上跟兩個工程師同時提交同一段代碼一樣麻煩——而且他們事先還沒溝通過。
Git Worktree 怎麼解決這個問題
Git worktree 是一個獨立的 working directory,位於自己的 branch 上,同時共享同一個 repo history。一個 agent 的修改,字面意義上不可能碰到另一個 agent 的 checkout。
Codex 直接內建 worktree 支援,多個 threads 可以同時作用於同一個 repo。
Claude Code 也透過 git worktree 提供隔離。兩種用法:
1
2
3
4
claude --worktree
# 或在 subagent 上設定 isolation
# 每個 helper 獲得一個新的 checkout,結束後自動清理
在 Workflow 腳本裡,你可以對 agent() 設定 isolation: 'worktree',讓每個平行 agent 在自己的 worktree 裡工作。
一個容易忽略的瓶頸
我試過同時開三個 agent 分別處理三個獨立的 bug fix,worktree 隔離了檔案衝突,但三個 PR 同時回來等我 review 的時候,我的認知負載瞬間爆表。最後花在 review 上的時間,比我自己修的還久。
教訓是:worktree 解決的是機械衝突,不是認知衝突。 決定你能同時跑多少 agents 的,不是工具,而是你的 review bandwidth。你的平行度上限是你的 review 能力,不是 git 的 worktree 數量。
組件 3:Skills——讓 Agent 不再每次冷啟動
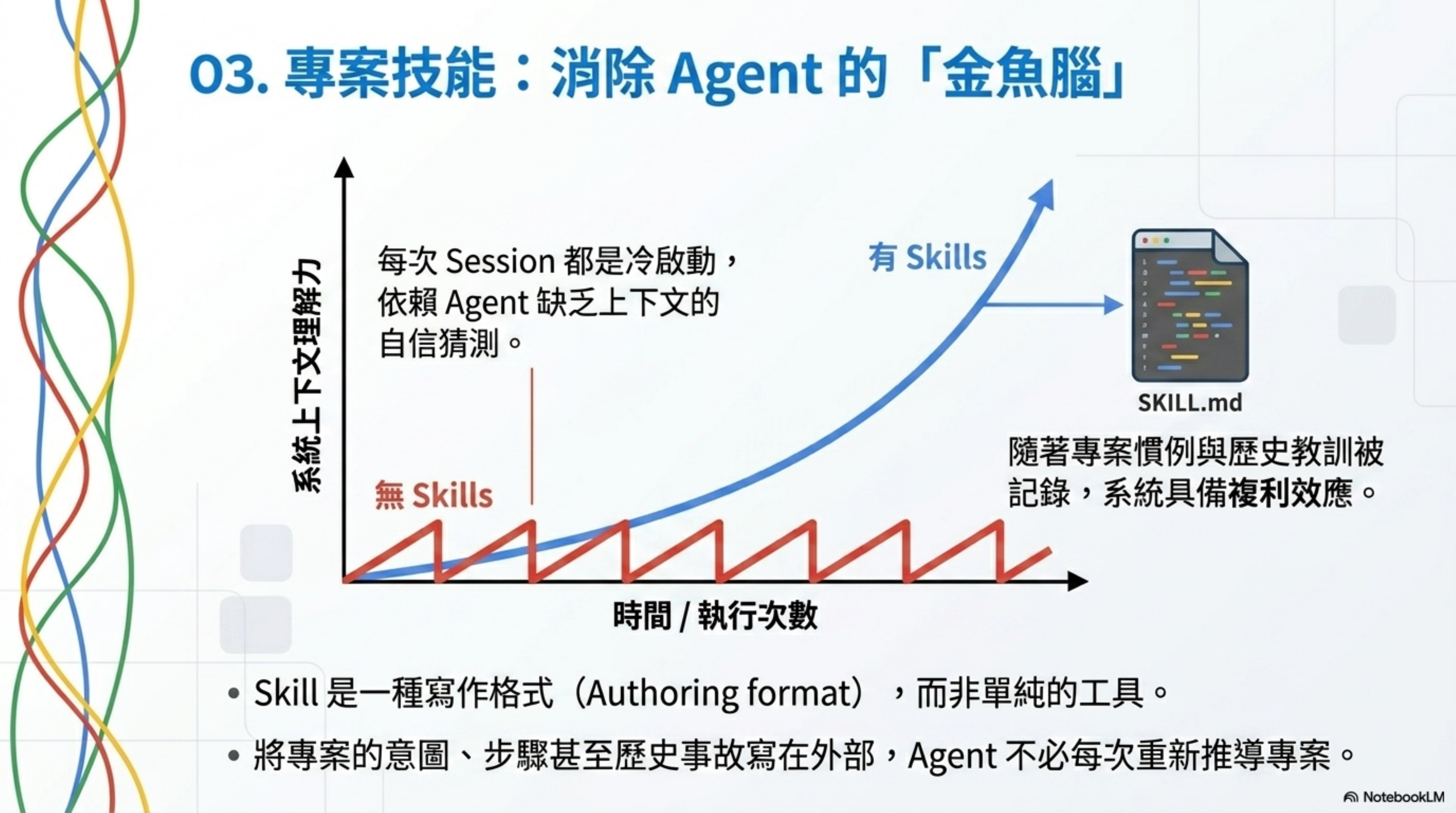
Skill 的作用是讓你不用每次 session 都像金魚一樣重新解釋同一個專案上下文。
格式
兩個工具用的格式相同:一個包含 SKILL.md 的資料夾,裡面存放 instructions 和 metadata,可以附帶 scripts、references、assets。
Codex 在你用 $ 或 /skills 調用時運行 skill;當 task 與 skill description 匹配時也可能自動調用。Claude Code 的做法一樣——Skill 文件定義觸發條件,匹配就自動載入。
為什麼 Skill 不是可有可無的
這是我在 Harness 系列裡反覆強調的一件事:Agent 每次 session 開始都是冷啟動。你的意圖裡有任何空洞,它就會用一種「自信的猜測」把洞填上。
Skill 就是把這種意圖寫在外部:專案慣例、build 步驟、「我們不這麼做是因為以前出過事故」。寫一次,每次執行都讀取。
沒有 Skills 的 Loop,每個週期都要從零重新推導你的整個專案。有了 Skills,它開始有複利效應。
Skill vs. Plugin 的區分
這裡有一個容易混淆的地方。Skill 是 authoring format——你寫的東西。Plugin 是你分發它的方式——當你想跨 repo 共享或打包多個 skills 時,封裝成 plugin。
Codex 是這樣,Claude Code 也是這樣。
我自己的 blog 寫作流程就是一個活的例子:我有一個 blog-creator skill,裡面包含了我的寫作風格、文章結構、禁止使用的詞彙(比如 emoji 和「反直覺」這個開場)。每次 Claude Code 幫我寫文章,它不用猜我想要什麼語氣——Skill 裡都定義好了。
組件 4:Connectors——讓 Loop 看見 Filesystem 之外的世界
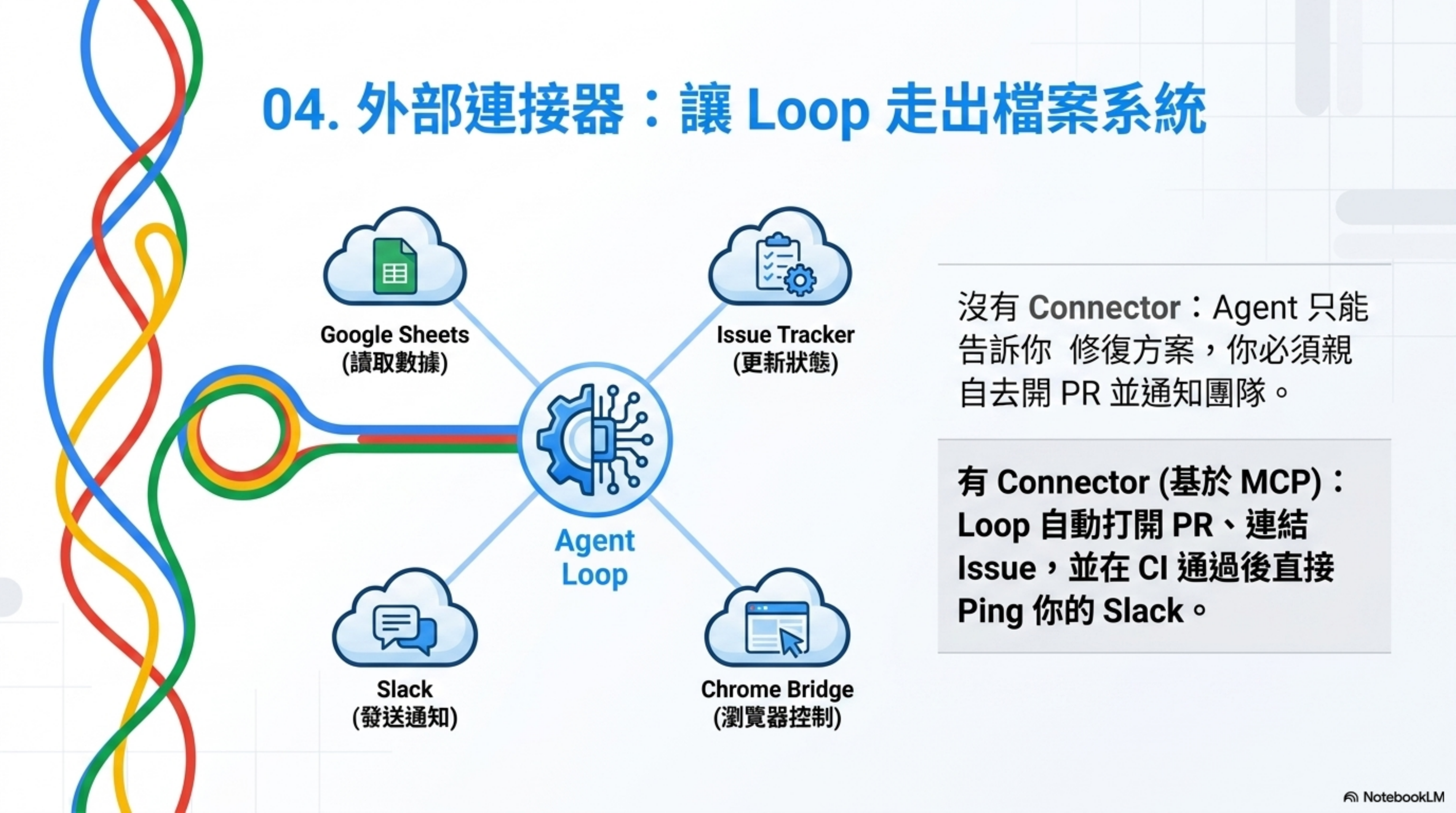
一個只能看見 filesystem 的 Loop,是一個很小的 Loop。
Connectors 基於 MCP(Model Context Protocol),可以讓 agent 讀你的 issue tracker、查數據庫、調用 staging API、在 Slack 發消息。
兩邊都支援 MCP
Codex 和 Claude Code 都支援 MCP。你為其中一個寫的 connector,通常在另一個裡也能直接用。
Plugins 還可以把 connectors 和 skills 打包在一起。這樣你的隊友只要安裝你的 setup,而不用憑記憶重建整套東西。
有 Connector 和沒有 Connector 的差別
沒有 Connector:Agent 說「這是修復方案」,你自己去開 PR、更新 ticket、通知團隊。
有 Connector:Loop 自己打開 PR、連結 issue tracker、CI 變綠後 ping Slack 頻道。
這就是「agent 告訴你它可以做什麼」和「loop 直接在你的真實環境裡行動」之間的距離。
實際考量
我目前用的 MCP connectors 包括 Chrome 瀏覽器控制(用 mcp-chrome-bridge)、Google Drive 存取、Google Sheets 讀寫。最有用的場景是自動化素材收集——agent 可以直接去查 Google Sheets 裡的數據,而不是我手動複製貼上。
但要注意:每多接一個外部系統,就多一個故障點和安全面。 MCP connector 的權限控制目前還在早期,你要清楚知道你給了 agent 什麼權限。
組件 5:Sub-agents——寫的人和檢查的人必須拆開
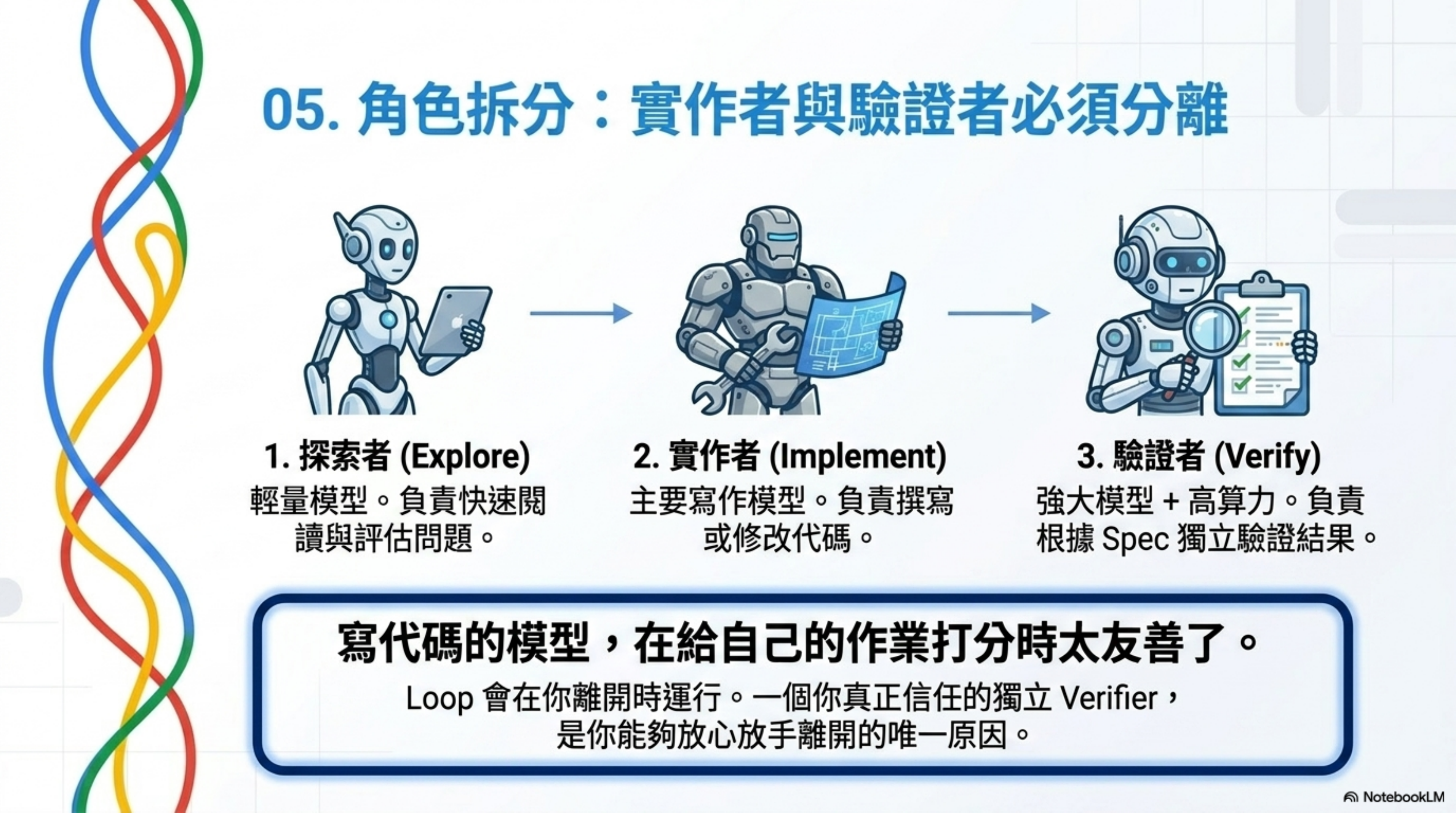
在一個 Loop 中,最有用的結構性設計是把「寫的人」和「檢查的人」拆開。
原因很直接:寫代碼的模型,在給自己的作業打分時太友善了。
一個帶有不同 instructions、甚至使用不同 model 的第二個 agent,能抓住第一個 agent 自我說服後忽略的問題。
怎麼定義 Sub-agents
Codex 在 .codex/agents/ 裡用 TOML 文件定義。每個文件包含 name、description、instructions,以及可選的 model 和 reasoning effort。你的 security reviewer 可以用強模型配 high effort,explorer 可以用快速的 read-only agent。
Claude Code 在 .claude/agents/ 裡做一樣的事,用 agent teams 在不同 agents 之間傳遞工作。
常見的拆分方式
兩個工具裡最常見的模式都是:
- 一個 agent 負責探索(Explore)
- 一個 agent 負責實現(Implement)
- 一個 agent 負責根據 spec 驗證結果(Verify)
這在 Loop 中尤其重要,因為 Loop 會在你不盯著看的時候運行。 一個你真正信任的 verifier,是你能走開的唯一原因。
連停止條件都是 maker/checker
前面組件 1 提到 /goal 的停止條件由獨立模型判斷。這其實就是 sub-agent 模式的應用——maker 和 checker 的拆分,甚至被應用到了「loop 該不該繼續跑」這個決策本身。
成本提醒
Sub-agents 會消耗更多 tokens,因為每一個都要進行自己的 model 和 tool work。要把它們花在「第二意見值得付費」的地方——security review、破壞性操作的確認、跨模組影響的評估。不是每個 lint fix 都需要一個 verifier。
+1:Memory——最容易被低估的組件
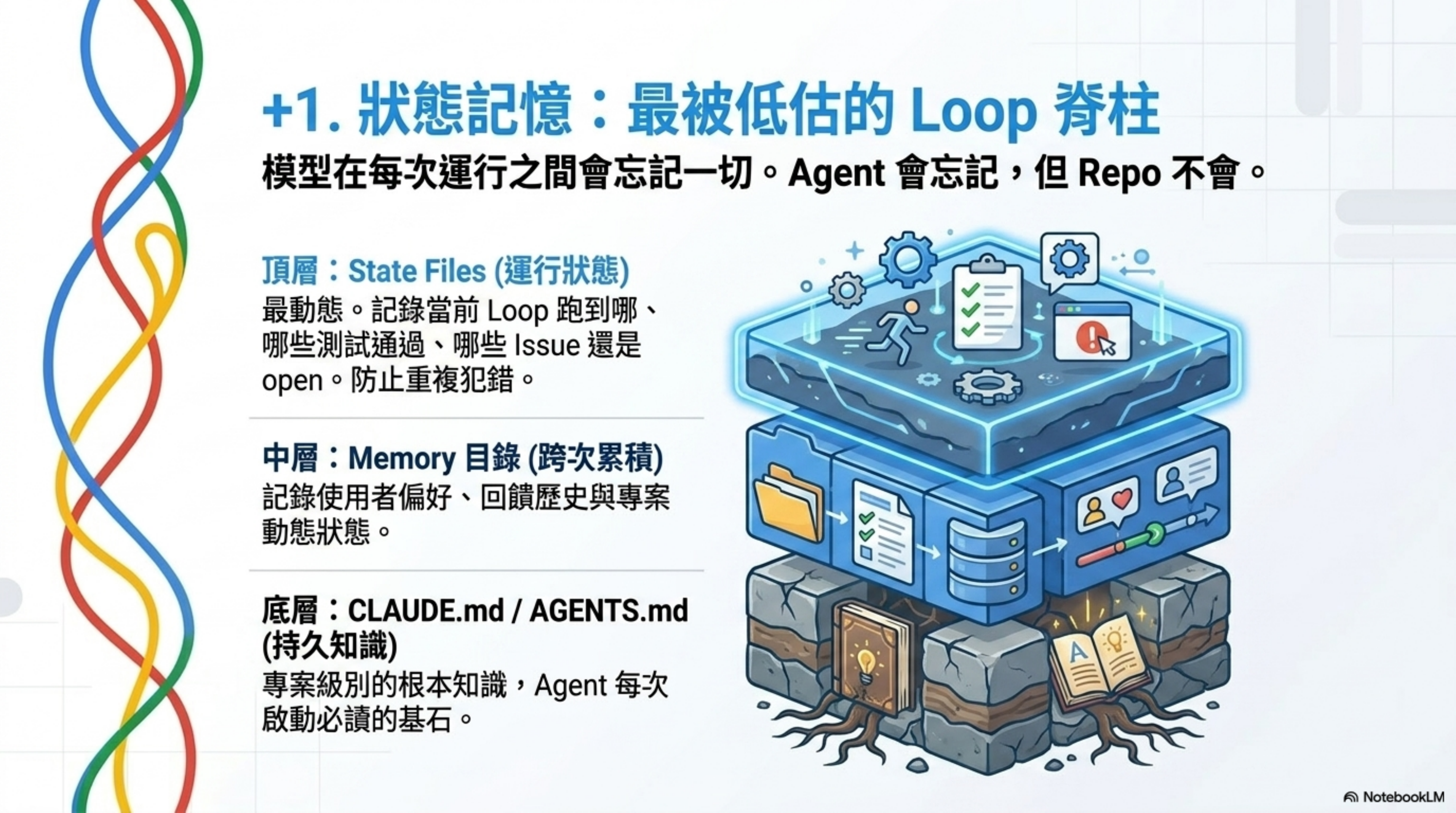
Memory 聽起來簡單到不像重要的東西。但它其實是每個 long-running agent 都依賴的同一個技巧。
為什麼 Memory 是 Loop 的脊柱
模型在每次運行之間會忘記一切。
這句話值得重複一次:模型在每次運行之間會忘記一切。
所以 memory 必須存在磁碟上,而不是只存在 context 裡。Agent 會忘記,但 repo 不會。
Memory 可以是一個 markdown 文件、一個 state file、或者任何存在於單次 conversation 之外、能保存「已完成事項」和「下一步事項」的地方。
我的 Memory 實作
我目前的做法是分層的:
- CLAUDE.md / AGENTS.md——專案級的持久知識,agent 每次啟動都讀
- Memory 目錄——跨 session 的使用者偏好、回饋、專案狀態
- State files——特定 Loop 的執行狀態,記錄上次跑到哪、什麼通過了、什麼還 open
第三層是 Loop 特有的。沒有 state file,下一次運行不知道上一次做了什麼,可能會重複檢查已經修過的問題,或者漏掉上次標記為「需要跟進」的項目。
把四個組件串起來看 Memory 的角色
想像一個完整的 Loop:啟動後,prompt 調用一個 triage skill。Skill 讀取最近的 CI failures、open issues、recent commits,把 findings 寫進一個 markdown 文件。對於每個值得處理的 finding,thread 打開一個隔離的 worktree,派一個 sub-agent 去 draft fix,再派第二個 sub-agent 根據 project skills 和 tests 去 review。Connectors 讓 loop 打開 PR、更新 ticket。
到這裡,四個組件都出場了。但如果沒有 Memory,下一次運行不知道這次做了什麼——可能重複修同一個 bug,或者漏掉標記為「需要跟進」的 finding。
State file 記住嘗試過什麼、什麼通過了、還有什麼仍然 open。 它是整套東西的脊柱。下一次的運行,從這次停止的地方繼續。
五個組件的映射表:Codex vs. Claude Code
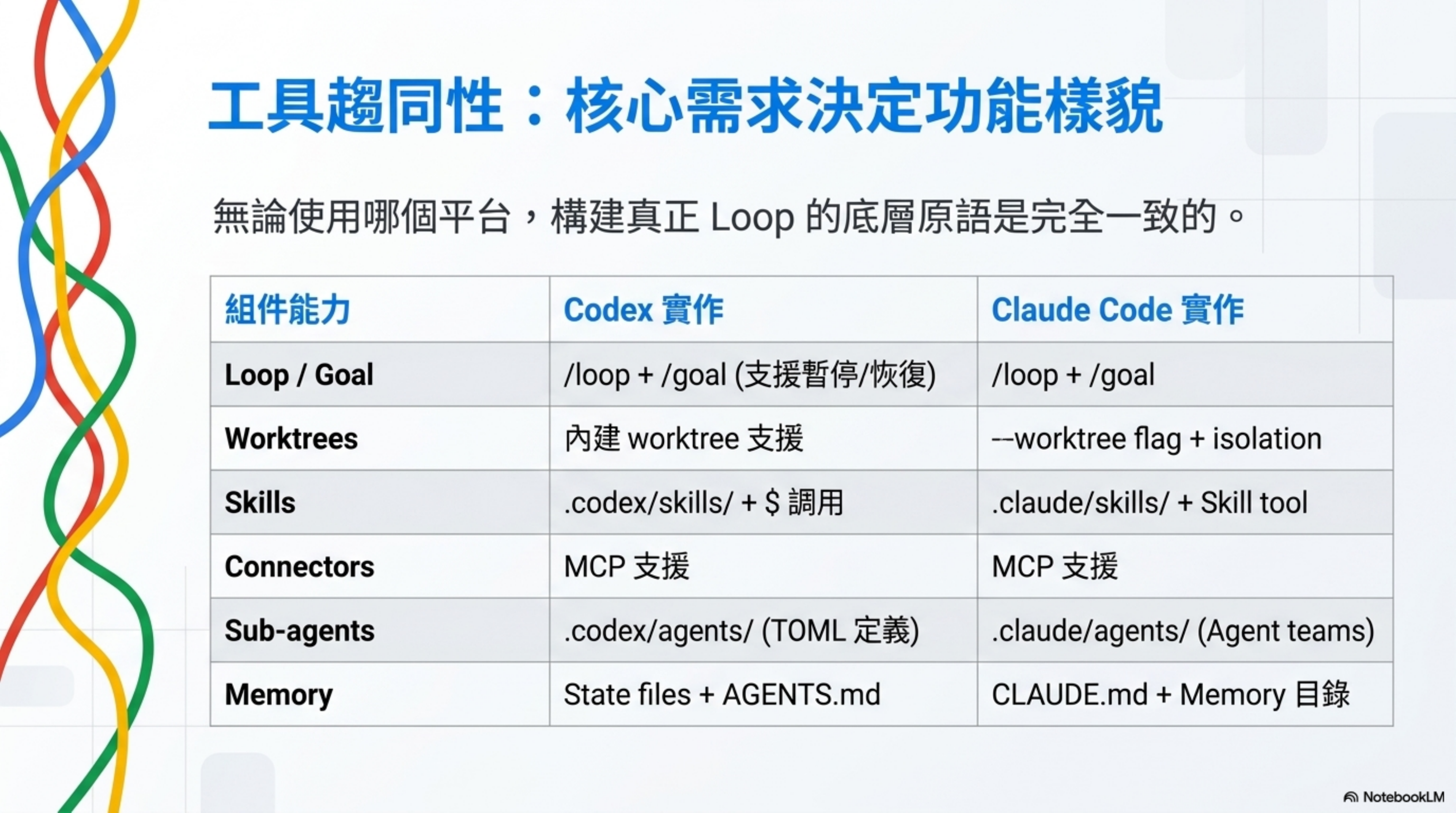
把兩個工具的能力名稱對齊之後,你會發現名字不同,但能力本質上一樣。
| 能力 | Codex | Claude Code |
|---|---|---|
| Loop / Goal | /loop + /goal(pause/resume/clear) |
/loop + /goal |
| Worktrees | 內建 worktree 支援 | --worktree flag + isolation: 'worktree' |
| Skills | .codex/skills/ + $ 調用 |
.claude/skills/ + Skill tool |
| Connectors | MCP 支援 | MCP 支援 |
| Sub-agents | .codex/agents/ TOML |
.claude/agents/ + agent teams |
| Memory | State files + AGENTS.md | CLAUDE.md + Memory 目錄 + state files |
兩邊的趨同不是巧合。當你真的在建 Loop 的時候,你需要的東西就是這些——不管你用哪個工具。
組合起來:一個可以照抄的模板
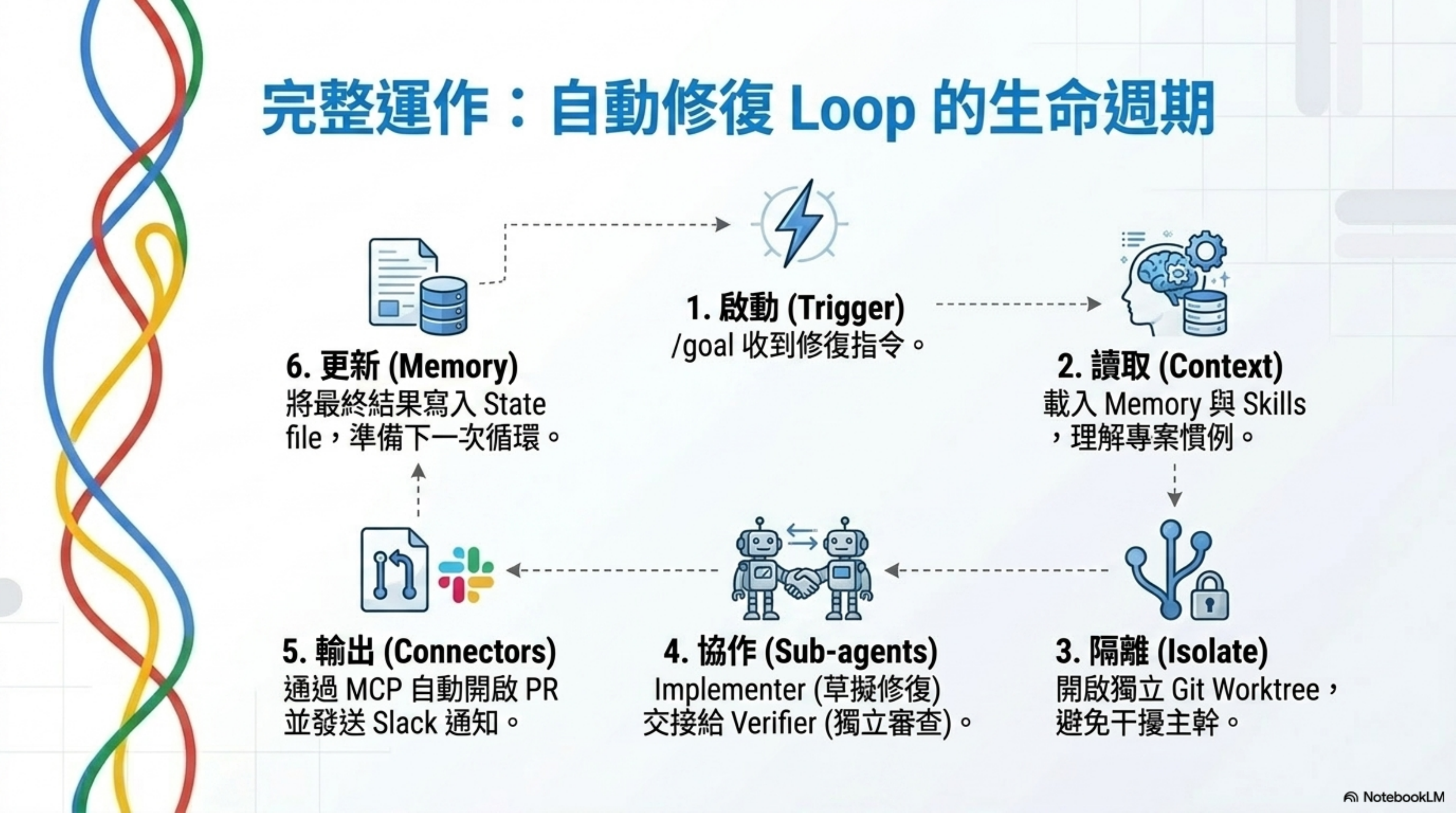
概念講完了,來一個實際能跑的組合。
這是我自己整理的 Loop 設計模板:
Step 1:定義觸發和節奏
1
2
3
觸發方式:cron(每天 09:00)/ event-driven(PR merged 時)/ manual(/loop 5m)
停止條件:metric 達標 / 連續 N 次無新發現 / budget 用完
成本上限:每次運行最多 X tokens
Step 2:確認每個組件就位
1
2
3
4
5
6
□ Loop/Goal:選對模式(有終點 → /goal,沒終點 → /loop),停止條件已定義
□ Worktree:如果需要平行 agent,隔離已設定
□ Skill:專案知識已寫成 SKILL.md,不靠 agent 猜
□ Connectors:需要的外部系統已透過 MCP 接入
□ Sub-agent:verifier 和 maker 是不同的 agent
□ Memory:state file 路徑已定義,格式已確認
Step 3:設計 Loop 的資料流
1
2
3
4
5
6
7
8
9
10
Trigger
→ 讀取 Memory(上次跑到哪)
→ 調用 Skill(專案 context)
→ Agent 1 做 discovery/implementation
→ Agent 2 做 verification
→ 結果寫回 Memory
→ 透過 Connector 執行 action(開 PR / 更新 ticket / 通知)
→ 檢查停止條件
→ 不滿足 → 下一輪
→ 滿足 → 停止,歸檔結果
一個適合我場景的簡單 Loop
我自己在用的一個小型 Loop,沒有上面那麼複雜,但已經在跑:
場景: 每篇新文章寫完後的品質檢查
1
2
3
4
5
觸發:手動(文章完稿時)
Agent 1:檢查文章結構——front matter 完整性、圖片路徑、cross-link 有效性
Agent 2:用不同 context 審文章——是否有禁止用詞、是否有未量化的宣稱
Memory:checklist 結果寫進文章的 review notes
Action:通過 → 觸發 publish skill 部署到 GitHub Pages
這不是自動觸發的——我還沒信任到讓 agent 自己決定什麼時候發文章。但它把我手動要做的 10 分鐘檢查清單壓縮到了 2 分鐘。
三個設計 Loop 時容易犯的錯
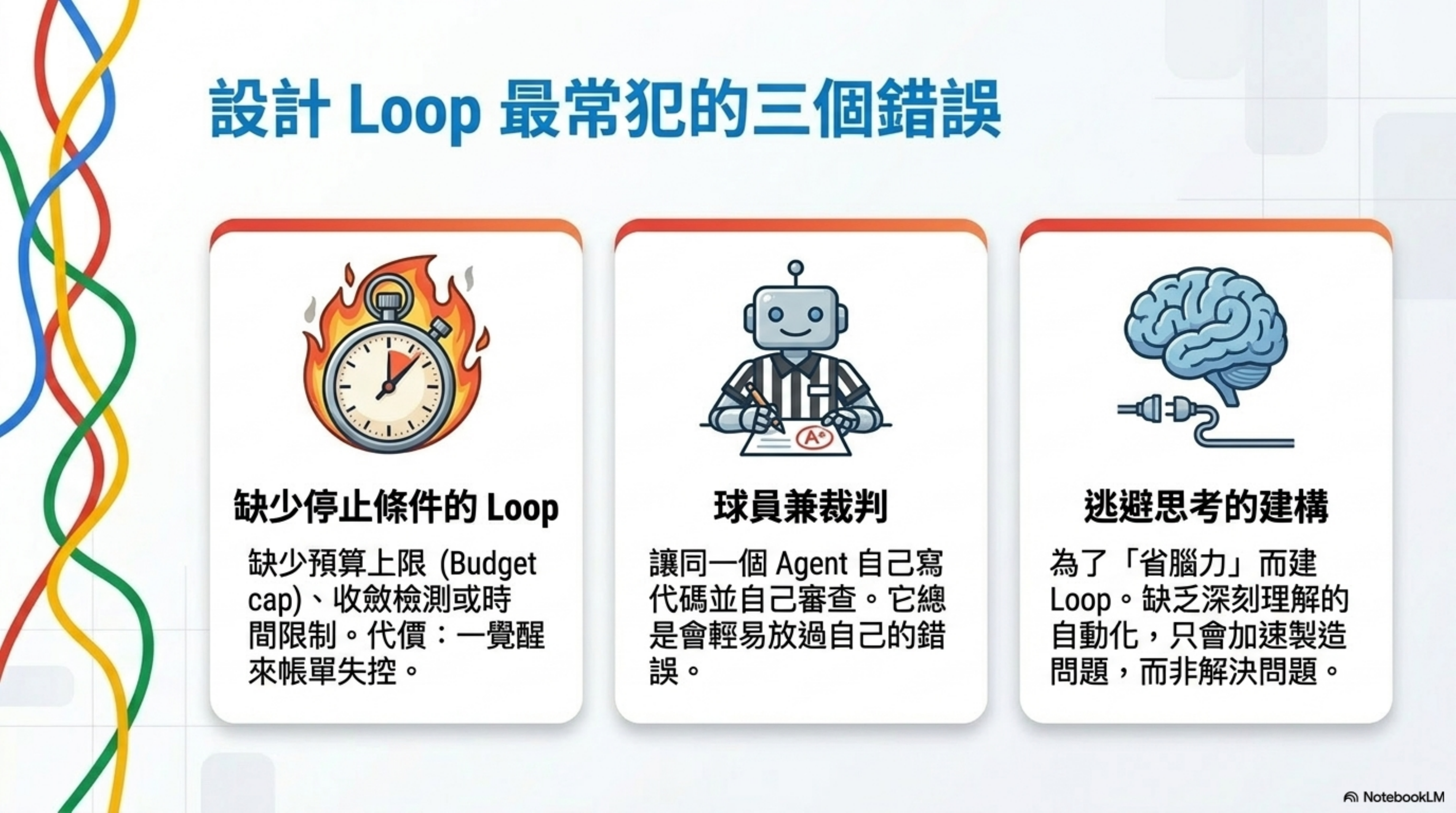
錯誤 1:沒有停止條件的 Loop
Loop 在你睡覺的時候也在跑。如果沒設停止條件,你醒來的時候帳單可能已經失控了。
必須有的三個停止機制:
- Budget cap——token 預算用完就停
- 收斂檢測——連續 N 次沒有改善就停
- 時間上限——Karpathy Loop 的第三要素就是每次實驗有固定時間限制
錯誤 2:讓同一個 Agent 自己改自己審
前面說過了,但再強調一次:寫代碼的模型給自己打分時太友善了。
1
2
❌ Agent 寫代碼 → 同一個 Agent 說「看起來不錯」 → merge
✅ Agent 寫代碼 → 不同的 Agent 用不同的 instructions 審 → 通過才 merge
錯誤 3:為了逃避思考而建 Loop
這是最隱蔽的錯誤。兩個人可以構建完全一樣的 Loop,得到截然相反的結果。一個人用它在自己深刻理解的工作上跑得更快。另一個人用它來避免理解工作本身。
當你帶著判斷力設計 Loop,Loop 是解藥。當你為了省腦力設計 Loop,Loop 是加速劑——加速的是問題,不是解決方案。
Loop 不知道這兩者的區別。但你知道。
坦白說
我現在的狀態,大概用了五個組件裡的三個半:Loop/Goal(/goal 修 bug 到測試過常用,/loop 做定期檢查偶爾用)、Skills(寫得很完整)、Connectors(MCP 在用)、Sub-agents(code review 時有在用 maker/checker 分離)。
Worktree 我還在摸索。主要原因不是技術門檻,而是我的工作性質——寫文章、做顧問、設計架構——大多沒有需要多個 agent 平行改 code 的場景。而且更根本的問題是:我的大部分工作沒有可自動衡量的 metric。沒有 metric,Loop 就退化成「自動跑但不知道自己跑得好不好」的系統。
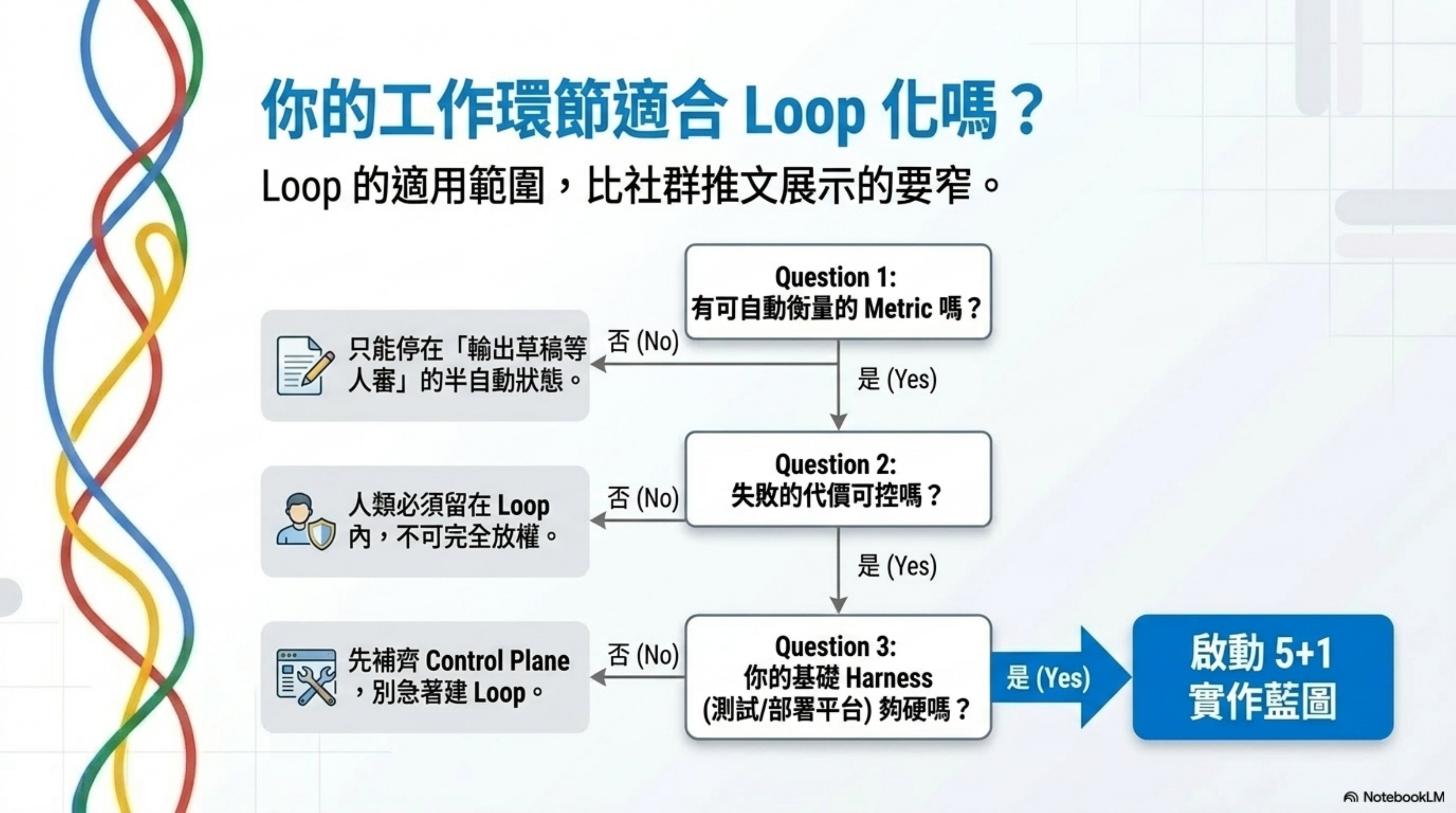
上一篇我的判斷沒有變:Loop Engineering 的核心概念是真的,但適用範圍比推文讓你以為的窄很多。
三個條件決定你能不能有效 Loop 化一個工作環節:
- 有可自動衡量的 metric 嗎? 沒有 → 只能 Loop 到「輸出草稿等人審」
- 失敗的代價可控嗎? 不可控 → 人要在 Loop 裡,不是 Loop 外
- 你的 Harness 夠硬嗎? 不夠 → 先補 Harness,不要急著建 Loop
但這篇的重點是:如果你的場景符合這三個條件,上面的五加一框架和組合模板,是目前最完整的實作路線圖。
Loop 改變工作方式,但它不會把你從工作中移除。設計 Loop 的那個人,需要比寫 Prompt 的人更多的判斷力,不是更少。

延伸閱讀
- Loop Engineering:不再 Prompt Agent,改設計 Loop 讓 Agent Prompt Agent——上一篇,拆解三個來源的定義差異和邊界
- Harness Engineering 完整拆解——Loop 的基礎:Control Plane Pattern
- Agent Harness 三次中心遷移——Prompt 是建議,機制才是規則
- Effective Feedback Compute——Loop 的效率取決於反饋信號的品質