[Agent Part 2] Plan & Exec 臨機應變 vs 讀著路書跑
![[Agent Part 2] Plan & Exec 臨機應變 vs 讀著路書跑](/assets/images/ChatGPT-Image-2025---11---1----------11_27_12.png "[Agent Part 2] Plan & Exec 臨機應變 vs 讀著路書跑")
WRC 賽車最經典的場面就是除了賽車手開著市售車款飛天遁地以外,最有趣的就是旁邊坐著一個副駕,讀著一本稱為「路書」的路線圖,用一些簡略的話去指引賽車手前進。 這個設計在追求速度的賽車界很有趣,因為坐一個副駕更重呀,為何需要把複雜的任務分成兩個角色——規劃者和執行者?
原因很簡單,WRC的賽道都是非常複雜,路況多變的越野賽到,他們經驗發現「規劃者搞清楚計劃,執行者全力執行然後隨機應變最有效率」

回到 AI Agenrt ,你有沒有想過當一個 AI 被指派一個複雜任務,它的腦子裡是怎麼想的? 上一篇我們比較 AI Workflow 跟經典的 ReAct Agent, 我們看到 ReAct Agent 最後解決了客戶問題。但你有沒有想過,在 ReAct Agent 的彈性的優點下有沒有哪個致命的問題。今天來介紹一下一個新的 Agent 模型,或許是現在大家最常看的 Plan & Exec 模型。
Plan-and-Execute
Plan-and-Execute(計畫與執行)架構的出現,其實是對 ReAct 高成本和低效率問題的直接回應。 它的核心思想很簡單:把 Agent 的工作流明確地分成兩個獨立的階段。
- 第一階段是「規劃」。這裡交給最強大的 LLM 做一件事:一次性思考清楚,生成一個詳細的、多步驟的完整計畫。不著急執行,就是想清楚。
- 第二階段是「執行」。計畫已經定好了,執行器就按照計畫逐一完成每個步驟。這裡不需要每次都調用大型 LLM來做決策。可以用更輕量級的模型,甚至簡單的規則來執行。
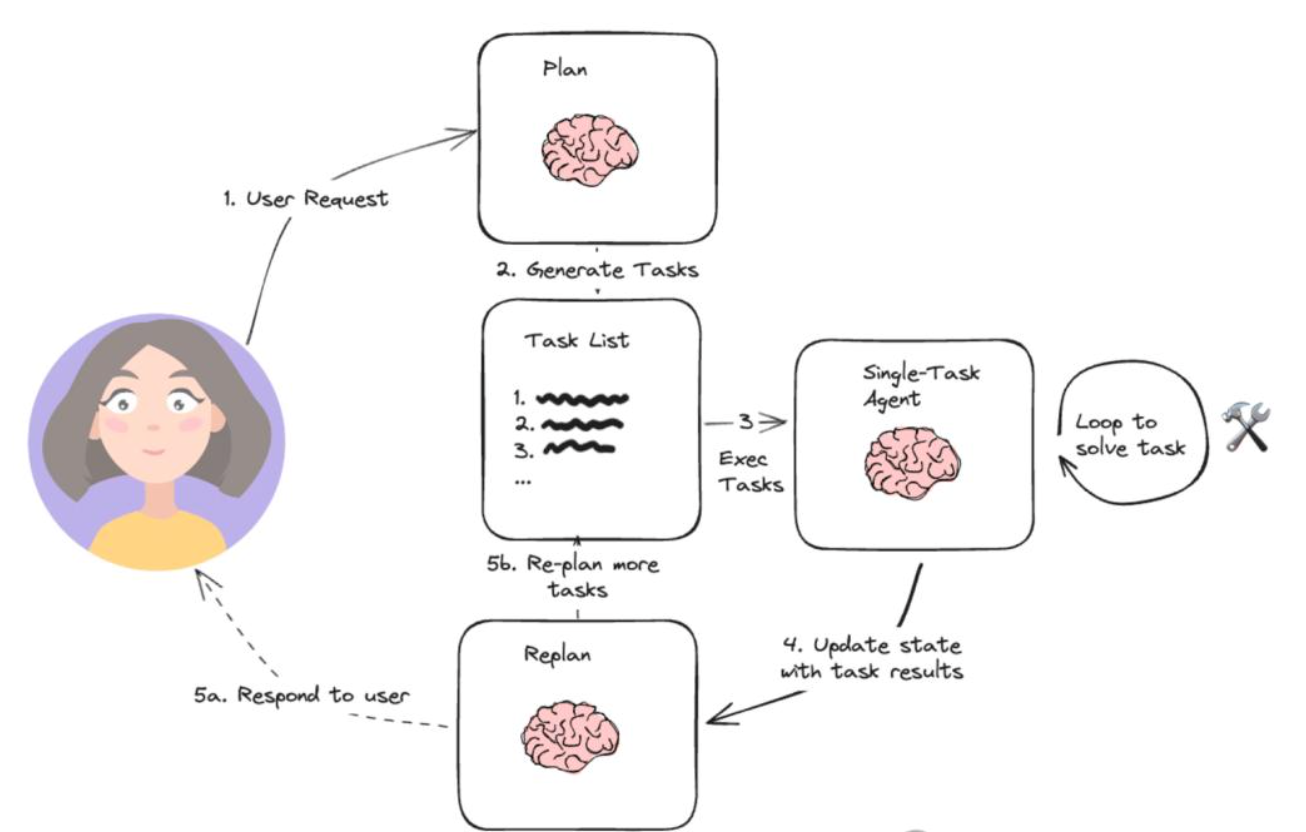
為什麼這樣更好? ReAct 的問題是每一步都要 LLM 思考,所以成本高、速度慢。Plan-and-Execute 的優勢是思考集中在規劃階段,執行階段使用輕鬆便宜的 LLM。 WRC的車手也說,因為 WRC 路線實在太過複雜,一個人真的記不住路書又要靈機應變,所以真的需要副駕駛,基本上車手就是遇到 token 爆炸的問題。
跟 ReAct 比優點:
- 大幅降低成本 — 不需要每一步都調用昂貴的大型 LLM。只在初始規劃和計畫失敗需要重新規劃時才用它。執行階段可以用更小、更快的模型,大大節省成本和時間。
- 避免局部最優 — ReAct 邊走邊想,容易走進死胡同。Plan-and-Execute 強制 LLM 在出門前就做全局思考,一次性想清楚所有邊界情況,避免了局部最優的陷阱。
跟 ReAct 比缺點:
- 應變能力弱,魯棒性差 — 計畫是寫死的,執行過程中可以應對狀況,但是沒有 ReAct 做得那麼好 。一旦某個步驟失敗,只能靈活性。
- 執行效率有限 — 很多 Plan-and-Execute 的實現還是一步一步來,無法並行。所以效率提升空間還很大(比起其他可以平行 run 的 模式) 。
場景差距
跟聊天機器人來比的話,ReAct 更適合是一個陪伴型的 ChatBot , 或是知識問答 ChatBot ,他靈活簡單,問到特定問題模型邊想邊查,但是較難處理複雜問題(超過5步),容易出現局部最優但是不是全局最佳。
Plan & Exec 更適合是「旅遊規劃」聊天機器人,或是 Coding Agent,用戶說需求到模型規劃整個對話路線(確認問題到查詢方案到提供建議到執行決策)到逐步引導用戶走完流程。缺點就是首個回應慢(需要較長規劃時間)。
Plan & Exec 跟 ReAct 的經典使用
老實說,並沒有看到哪個工具都用 ReAct ,也沒有看到哪個工具一定用的是 Plan & Exec。首先,商務場景下根本就不可能看到純 ReAct ,現實上一定採取限制步數的 ReAct ,因為純 ReAct 遇到無法解決的問題一定是 token 爆炸
ReAct 舉例
一般現在有水準,可以搜尋的 Chatbot ,幾乎都是 受限制ReAct 的教科書案例
像是我故意問ChatGPT 5 Thinking:「對比 Claude 5、GPT-6、Gemini 最新版本在推理、代碼生成、多語言方面的表現,給出具體測試數據」。有沒有注意到,我故意問錯的問題( 2025/11/1 時間,Claude公開只出到 4.5 ,GPT只出到 6),要考驗他們除錯都能力。
ChatGpt:思考 → 搜尋多個來源(新聞、技術論壇、官方公告)→ 觀察結果 → 再思考「我找到的夠完整嗎」→ 可能再搜尋補充 → 最後綜合回答。你能看到它的思考過程,它在即時調整搜尋策略。
Plan & Exec 舉例
同比 Plan & Exec 最直觀的例子就是 Deep Research 了,尤其是 Gemini 的 Deep Research 在 UI 設計上根本就是教科書級別 Plan & Research 介紹

當我問到 Gemini 「幫我解釋 react 跟plan and exec 在ai agent 模式的不同 」,他會先給你一個研究大綱,等你確認後,再去每一步搜尋,調整,每一步都有可能找錯資料,但是會在每一步的範疇內微調。
當然,Claude Code 的 Plan Mode 也是很好很直觀的 Plan&Exec; 的案例。當我們下達修改某個 feature,通常都只要稍微複雜,就會需要先 Plan 列出來後才進行修改
你的 Agent 是盲目加速還是讀著路書跑?
之前說到如果環境多變化,你需要 ReAct 來保證魯棒性,但是如果環境多變化,任務又很複雜——你需要 Plan-and-Execute。 整體用 Plan 保證不亂走,局部用 ReAct 靈活應對。就像真實的 WRC:副駕手寫好路書,永遠看著整個賽道全局最優,但主駕手在每個彎道仍然要靠直覺微調。這才是 WRC 的勝利方程式,兼顧全局跟細節的微調。
AI Agent 系列導航
本文是 AI Agent 完整指南 的一部分。
上一篇: [Part 1] Workflow 型和 ReAct 型,誰更像你?
下一篇: [Part 3] Interleaved Thinking — 穩定性是現在 Agent 落地的重要關鍵
系列文章:
- [Part 1] Workflow vs ReAct
- [Part 2] Plan & Execute(本文)
- [Part 3] Interleaved Thinking
- [Part 5] Dual-Agent 架構
- [Part 7] LATS 決策大腦
- Agent Security