MSA:4B 模型打贏 235B RAG 系統,記憶力不靠外掛的時代來了?

MSA:4B 模型打贏 235B RAG 系統,記憶力不靠外掛的時代來了?
EverMind AI 的 Memory Sparse Attention(MSA)論文,把「記憶」直接長進注意力機制裡,100M tokens、O(L) 複雜度、2 張 A800 就能跑。聽起來太好了,我們來拆開看看到底怎麼回事。
這篇論文的核心問題
又到了週二看論文的時間,今天來看一篇很有意思的論文:MSA(Memory Sparse Attention)。
這篇的核心問題很簡單:當知識量變得非常大時,模型到底怎麼「找資料並推理」?
它的答案不是做一個更快的 RAG,而是——把「找資料」變成模型思考的一部分。
過去我們做 RAG,其實是兩件事分開:
- 外部 retriever 負責找資料
- LLM 負責推理
問題是:找錯資料,後面再強也沒用。
MSA 的做法是把這件事直接改掉:把 retriever 內建進 attention 裡。也就是說:
- 模型自己決定該看哪些資料
- 檢索策略可以隨最終答案一起優化
- 找資料與推理變成同一個過程
結果是:檢索不再是前處理,而是推理的一部分。
這個差異帶來的影響其實很大
在知識密集任務(文件、知識庫、企業資料)裡,問題通常不是模型不夠聰明,而是:
- 資訊分散
- 需要跨文件整合
- 答案藏在不同地方
在這種情況下,檢索能力其實就是推理上限。
這也是為什麼論文裡出現一個很誇張的結果:Qwen3 4B + MSA,可以打贏 KaLMv2 retriever + 235B Qwen3 的 RAG 系統。不是因為 4B 更強,而是它「每一步都看對資料」。
先把三種主流做法講清楚
Fine-tune(微調) — 把知識直接學進模型裡
- 優點:反應快、推理穩定
- 缺點:更新成本高、容易遺忘、容量有限
RAG(檢索增強) — 知識放外部,用 retriever 撈進來
- 優點:可擴展、知識更新快
- 缺點:檢索錯就全錯,無法端到端優化
MSA(這篇論文) — 知識仍在外部,但檢索能力內建在模型裡
- 優點:可擴展 + 可訓練 + 檢索與推理融合
- 缺點:訓練成本高
從應用角度看,MSA 的 impact 很直接
- RAG pipeline 可以大幅簡化 — chunking、embedding 模型、向量數據庫、reranking 模型這些都可能不需要了,因為檢索能力內建在模型裡
- 成本下降,小模型可行 — 4B + MSA 打贏 235B + RAG,推論成本可能差幾十倍。企業文檔問答場景,TCO 的差距是數量級的
- 多文件推理能力變強 — 現在跨文檔推理要寫一堆 Agent workflow,MSA 的 Memory Interleave 把這件事內建了
- 但現階段是「理解 + 觀望」 — 模型還沒開源,benchmark 還沒被社群驗證,別急著重寫系統
在企業知識庫、內部文件問答這類場景,幾乎是最直接的落地方向。如果這條路走通,未來的 AI Agent 系統,可能會比現在簡單很多。
搞清楚 MSA 到底在做什麼之後,我們來拆開看它怎麼做到的。
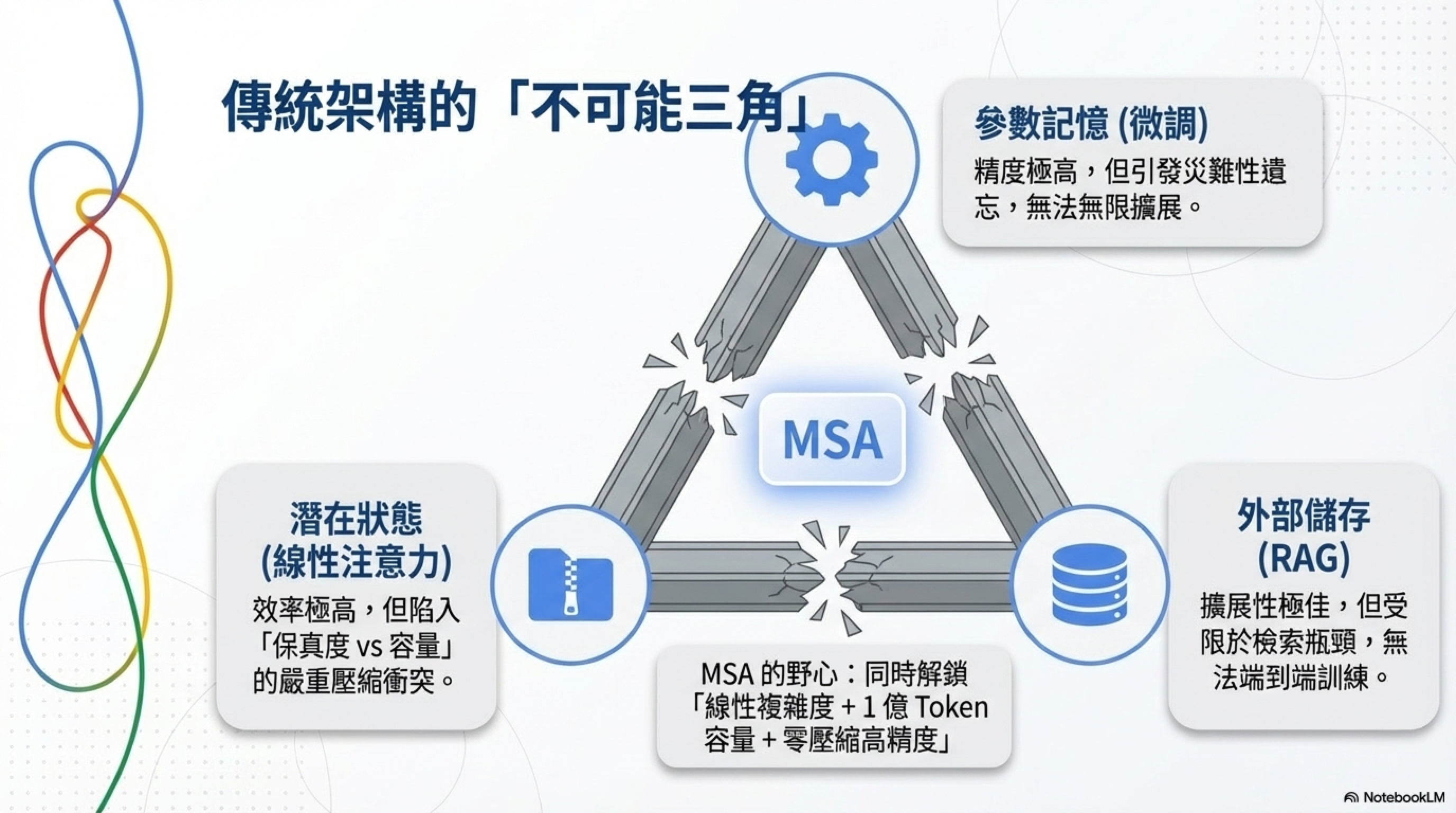
LLM 記憶的「不可能三角」
論文提出一個很有意思的框架——LLM 記憶系統的不可能三角:
| 方案 | 強項 | 根本問題 |
|---|---|---|
| 參數記憶(微調) | 精度高 | 不可擴展,災難性遺忘 |
| 外部儲存(RAG) | 擴展性好 | 檢索精度瓶頸,不可端到端訓練 |
| 潛在狀態記憶(線性注意力) | 效率高 | 保真度 vs 容量的衝突 |
MSA 的野心是同時做到:線性複雜度 + 1 億 token 容量 + 高精度。
四個核心機制,逐個拆解
1. Memory Sparse Attention:不是全看,是挑著看
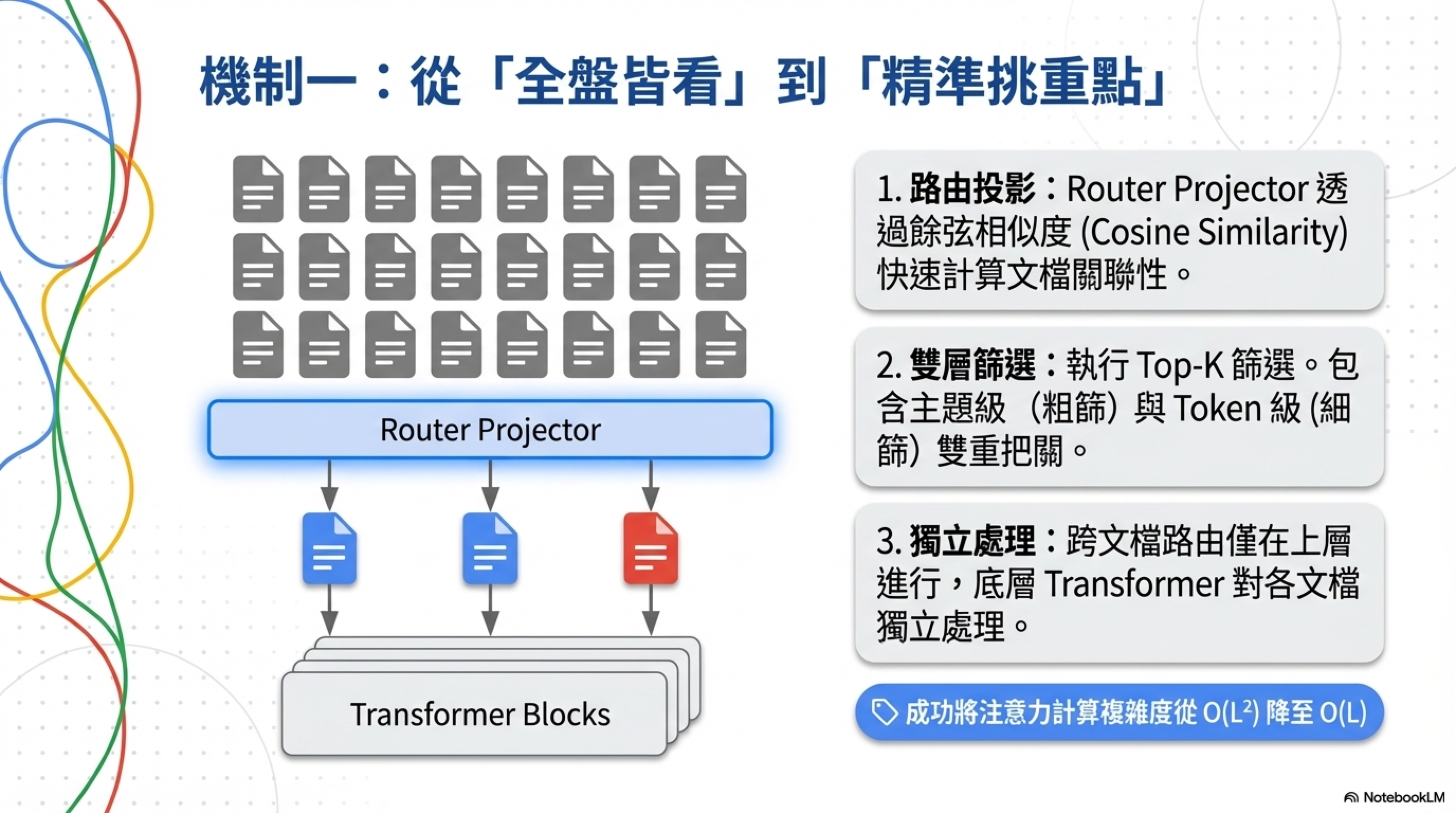
傳統 Transformer 的注意力是「每個 token 看所有 token」,O(L²)。MSA 的做法是:
- 一個 router projector 先算每個文檔跟查詢的相關性(cosine similarity)
- Top-k 選擇:只挑最相關的文檔段落做注意力計算
- 雙層篩選:粗篩(主題級)+ 細篩(token 級)
- 底層 Transformer 各文檔獨立處理,上層才做跨文檔路由
關鍵差異:整個檢索過程是可微分的、端到端訓練的。RAG 的 retriever 是凍結的,檢索錯了模型也學不到教訓。MSA 的路由器跟語言模型一起訓練,檢索品質會隨訓練改善。
2. Document-wise RoPE:64K 訓練,100M 推論
這可能是最聰明的設計。
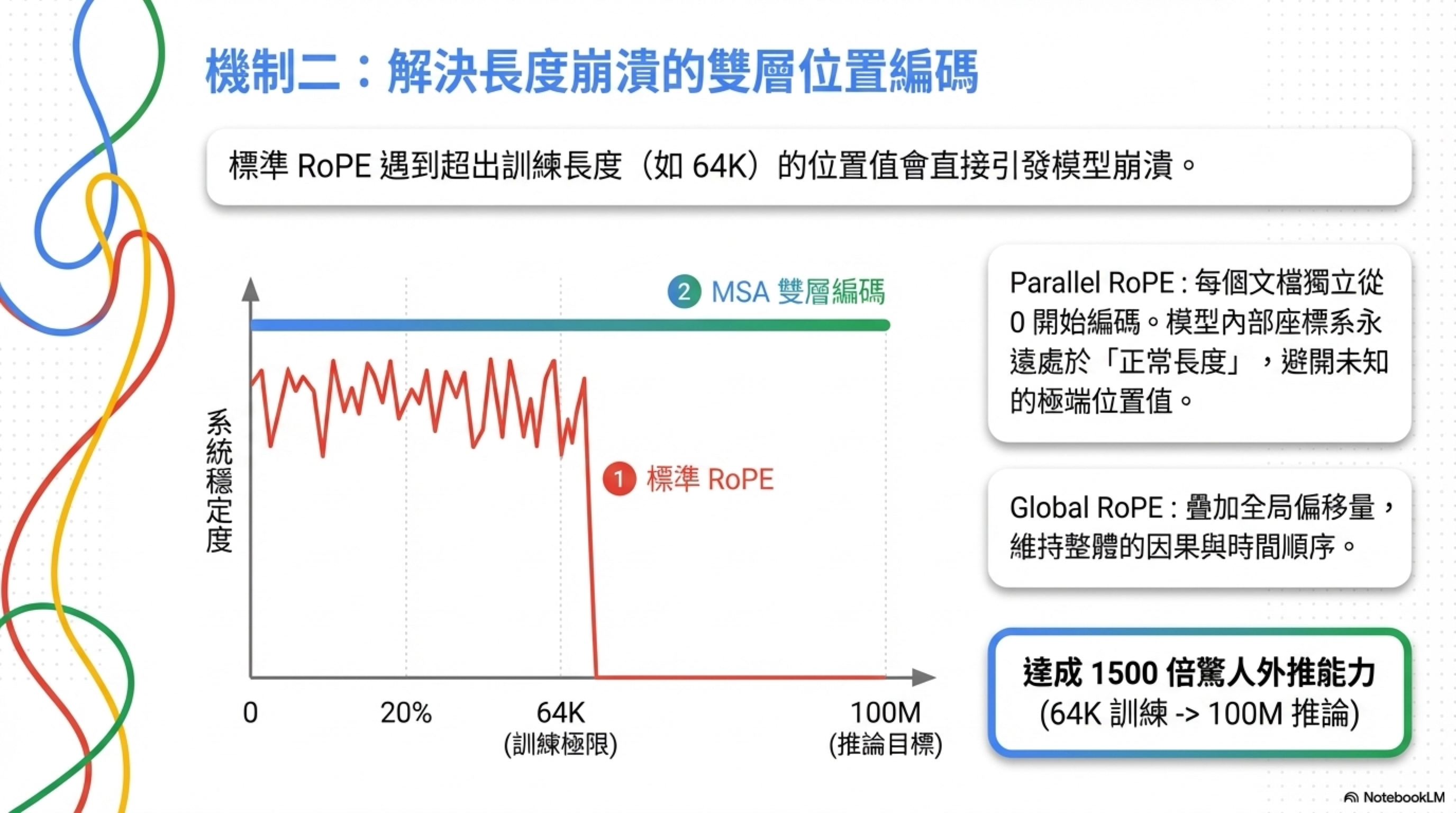
標準 RoPE 給整個序列分配絕對位置。你在 64K 長度上訓練,推論時遇到第 100M 個 token,模型從沒見過這麼大的位置值,直接崩潰。
MSA 用了兩層位置編碼:
- Parallel RoPE:每個文檔獨立從 0 開始編碼。模型的內部座標系永遠是在處理「一個正常長度的文檔」,不會遇到超出訓練分佈的位置值。
- Global RoPE:在 query 端加上全局偏移,保持因果關係和時間順序。
結果:64K 訓練長度外推到 100M,是 1500 倍的外推能力。從 32K 到 1M tokens,NIAH(大海撈針)準確率只掉了 3.93 個百分點。
3. KV Cache 分層儲存:GPU 搜、CPU 存
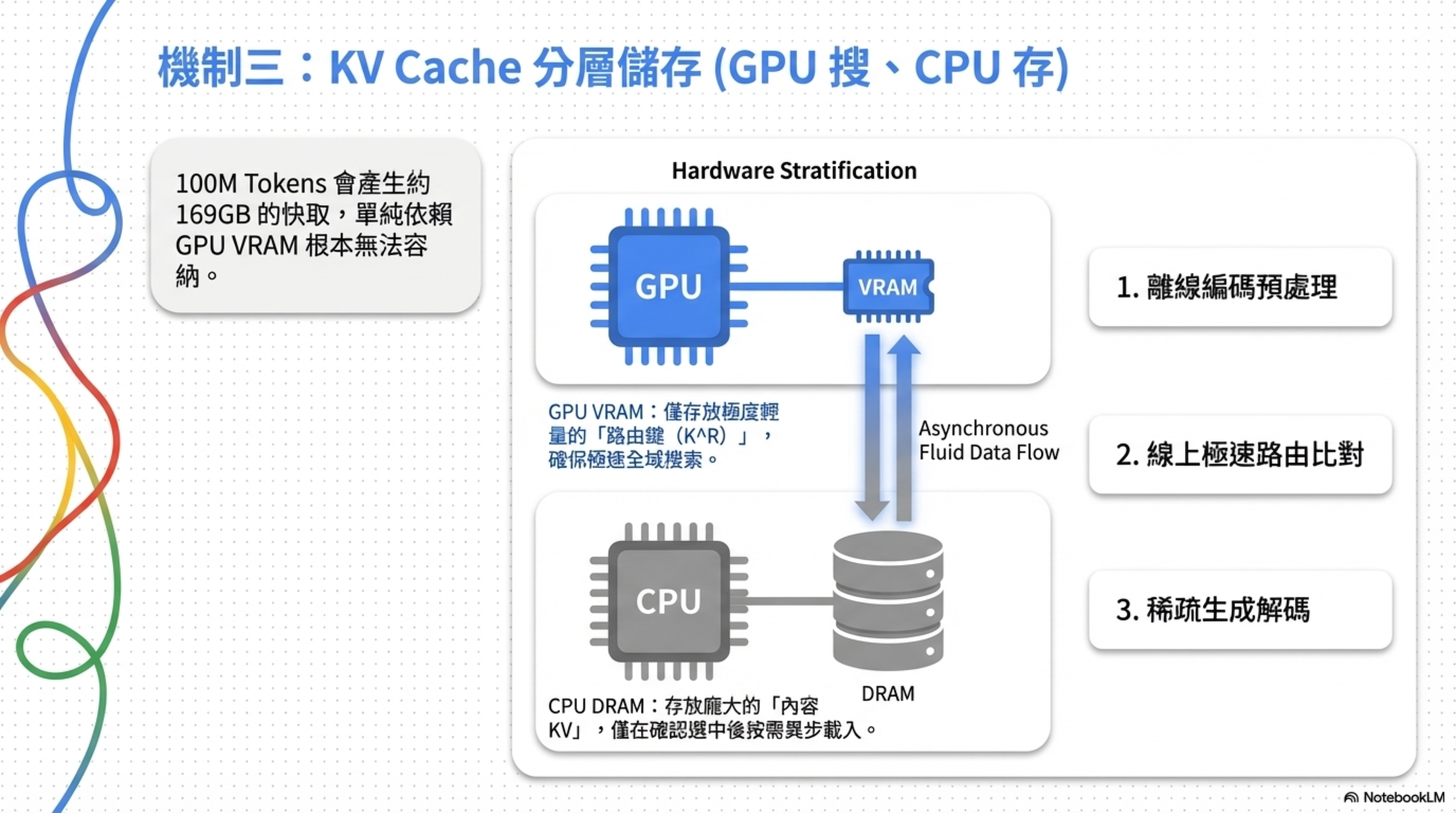
100M tokens 的 KV cache 大概 169GB,全放 GPU 顯然不行。MSA 的策略:
- 路由鍵(K^R):放 GPU VRAM,用於快速搜索
- 內容 KV:放 CPU DRAM,按需載入
- 異步預取:搜索和載入流水線化
推論三階段:
- 離線編碼:把整個語料庫預處理一次,快取每個文檔段的壓縮表示
- 線上路由:query 進來,跟快取的路由鍵比對,選 top-k 文檔
- 稀疏生成:只在選中的文檔上做標準自回歸解碼
硬體需求:100M tokens 推論只需 2 張 A800 GPU。
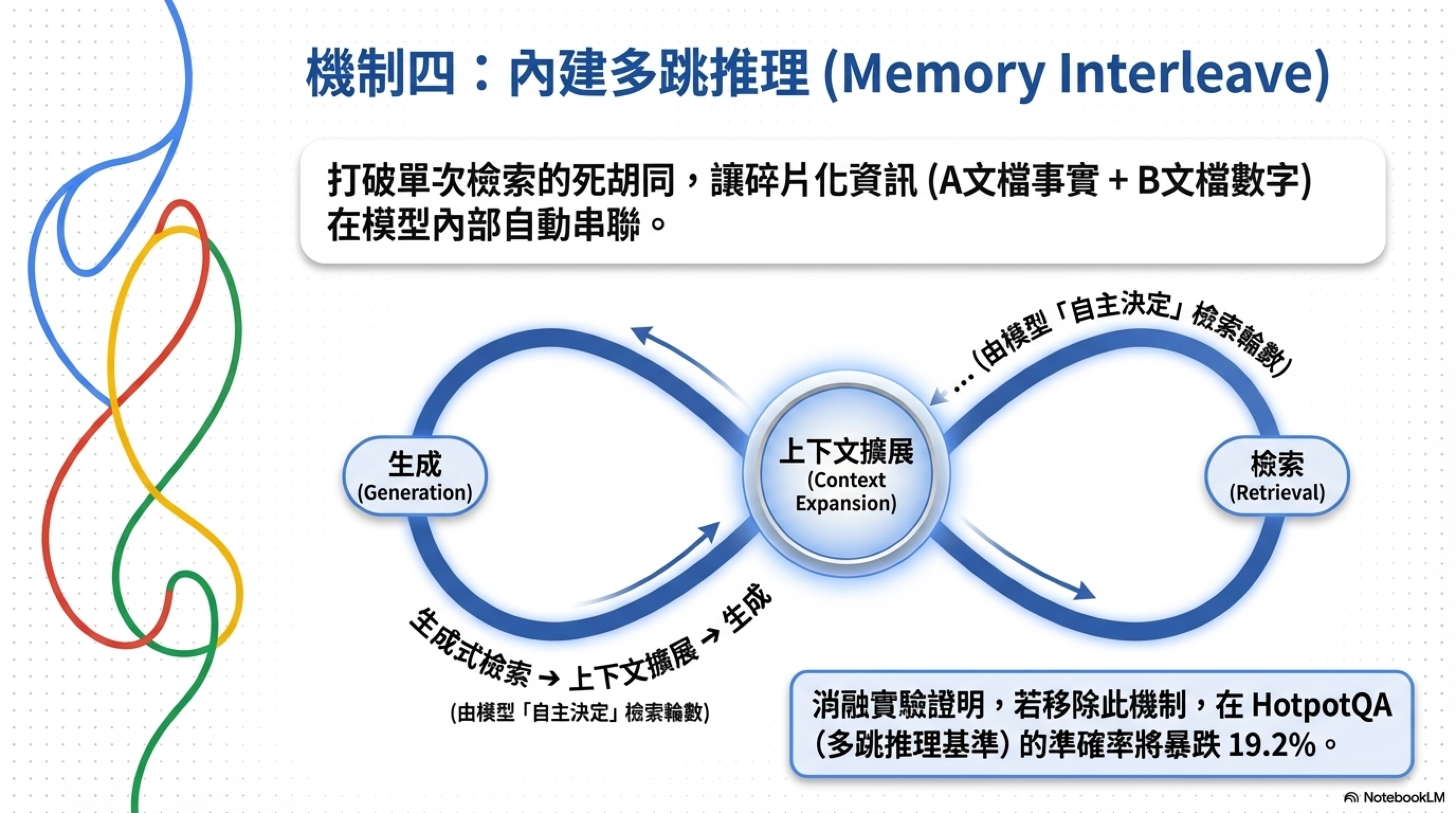
4. Memory Interleave:碎片化資訊也能串起來
企業知識最頭痛的就是:答案不在一份文檔裡,要從 A 文檔拿一個事實、B 文檔拿一個數字、C 文檔拿一個時間點,串起來才是完整答案。
MSA 的 Memory Interleave 機制:
生成式檢索 → 上下文擴展 → 生成 → 再檢索 → …
模型自主決定需要幾輪檢索。消融實驗顯示,拿掉 Memory Interleave,平均分數掉 5.3%,但在 HotpotQA(多跳推理基準)上掉了 19.2%。
數字說話:4B 打贏 235B
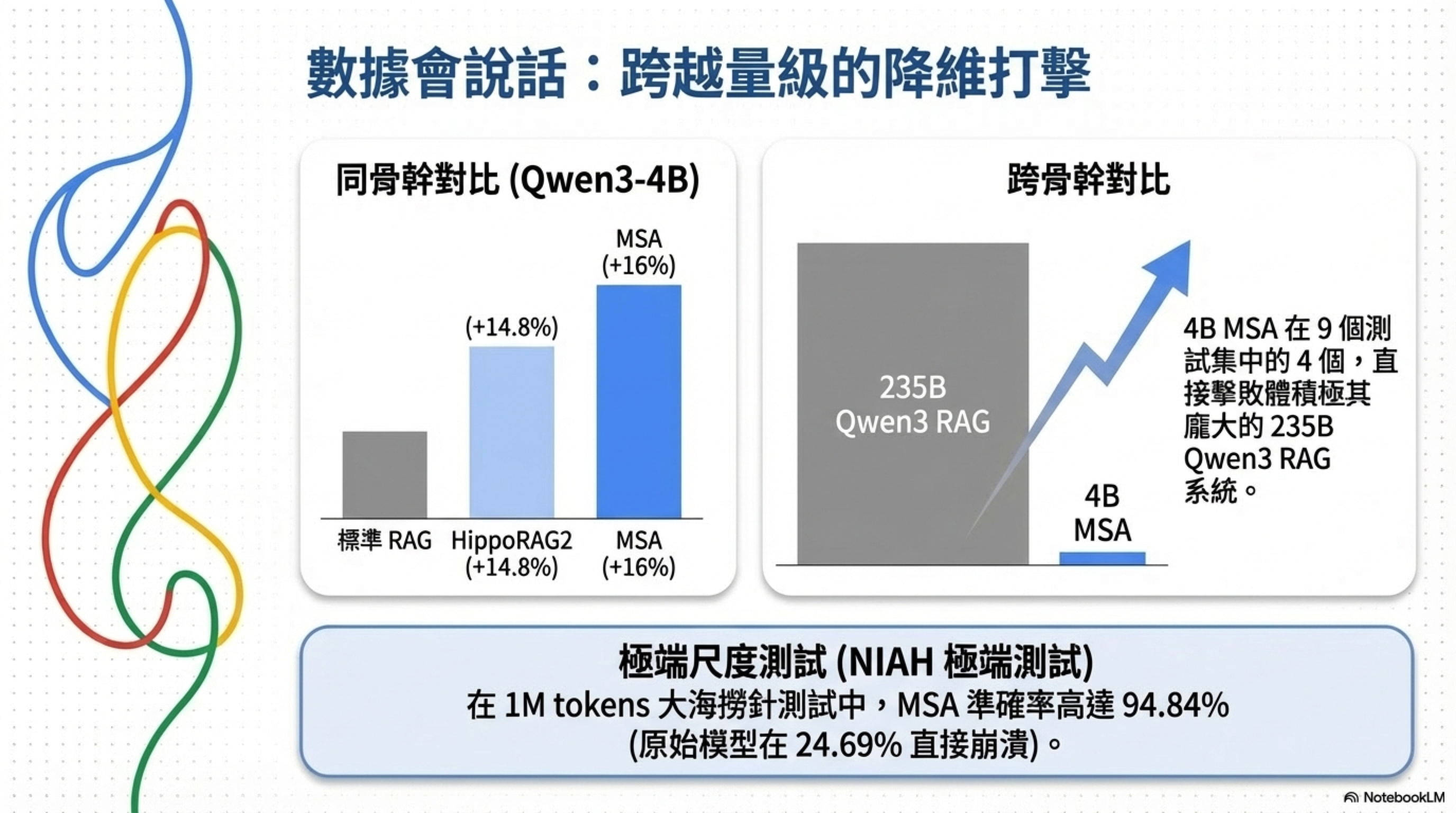
同骨幹對比(都用 Qwen3-4B)
9 個 QA 數據集上:
| 系統 | 平均分 | vs MSA |
|---|---|---|
| 標準 RAG | 2.559-3.242 | MSA 高 16% |
| RAG + Reranking | ~3.37 | MSA 高 11.5% |
| HippoRAG2 | ~3.27 | MSA 高 14.8% |
| MSA (4B) | 3.760 | — |
跨骨幹對比(MSA 4B vs 大模型 RAG)
對手用 KaLMv2 retriever + 235B Qwen3 或 70B Llama 3.3 做生成器:
- MSA (4B) 在 9 個數據集中的 4 個領先
- 部分數據集領先 5-10.7%
- 這是 4B 模型打贏 58 倍大的 235B 模型
極端尺度測試
MS MARCO QA 上:
- 16K tokens:4.023 分
- 100M tokens:3.669 分
- 跨 4 個數量級,衰退不到 9%
NIAH(大海撈針)1M tokens:
- MSA:94.84%
- 原始 Qwen3-4B:24.69%(直接崩潰)
跟現有方案的正面對比
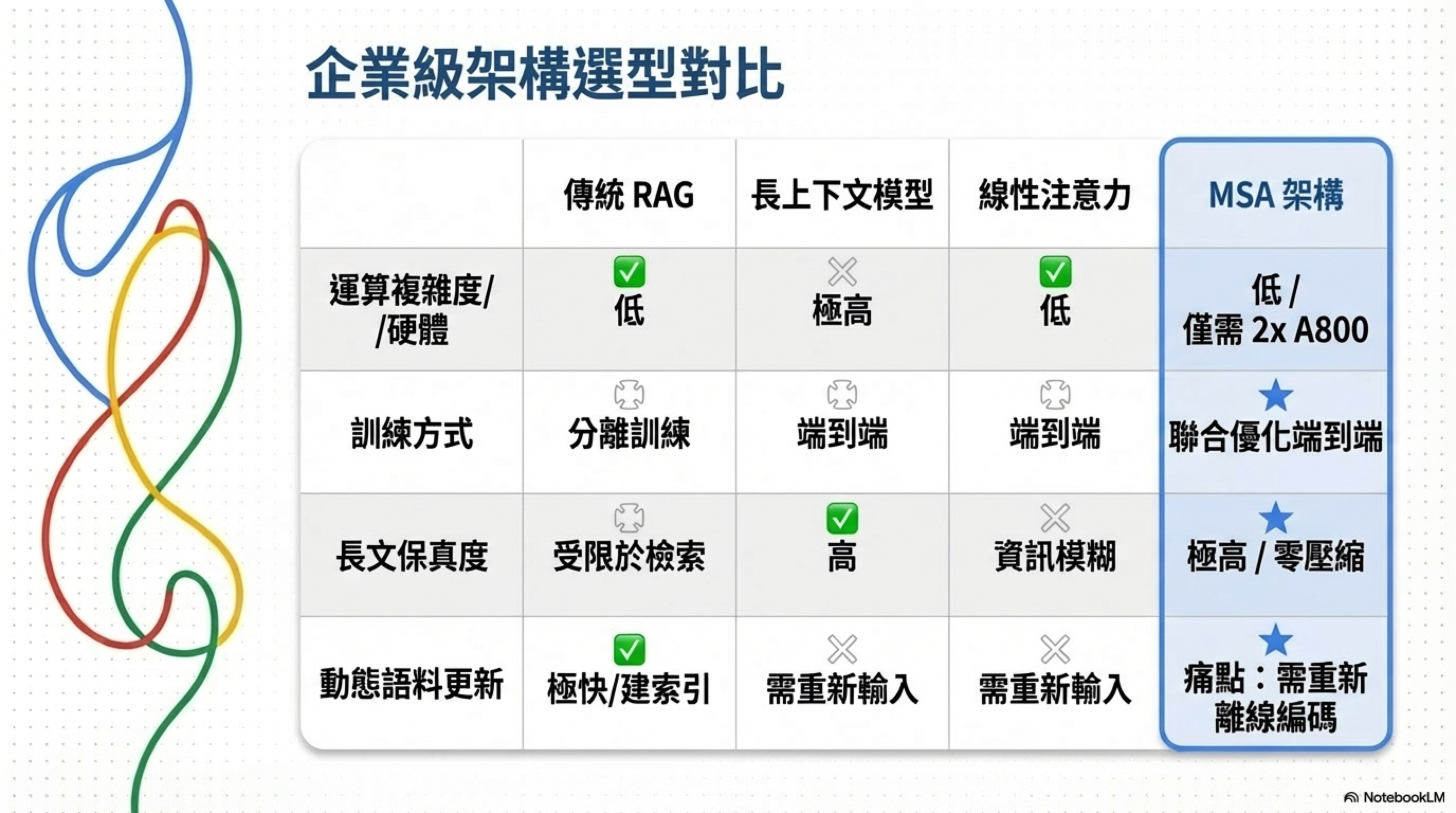
MSA vs RAG
| 面向 | RAG | MSA |
|---|---|---|
| 檢索器 | 凍結,獨立訓練 | 端到端可微分 |
| 訓練方式 | 檢索器和生成器分開練 | 聯合優化 |
| 多跳推理 | 需要複雜的 Agent pipeline | 內建 Memory Interleave |
| 4B 模型表現 | 3.242(最佳) | 3.760(+16%) |
| 語料更新 | 重建索引即可 | 需要重新離線編碼 |
MSA vs 長上下文模型
| 面向 | 長上下文模型 | MSA |
|---|---|---|
| 複雜度 | O(L²) 或 O(L log L) | O(L) |
| 實際上限 | 128K-1M | 100M |
| 硬體需求 | 大規模 GPU 叢集 | 2x A800 |
| 位置外推 | 訓練長度以外就崩 | 1500 倍外推 |
MSA vs 線性注意力(Mamba、RWKV)
| 面向 | 線性注意力 | MSA |
|---|---|---|
| 複雜度 | O(L) | O(L) |
| 資訊損失 | 壓縮累積,越長越糊 | 選擇性保留,不壓縮 |
| 1M tokens 準確率 | 顯著衰退 | 94.84% |
坦白說:幾個需要冷靜的地方
數字很漂亮,但有幾件事得講清楚:
1. 模型還沒開源
GitHub 上寫著 “Coming Soon”。論文有了、數字有了、但第三方還沒辦法獨立復現。在 AI 領域,「論文數字」跟「實際部署效果」之間的落差,大家都懂。
2. 訓練成本不低
MSA 做了 158.95B tokens 的持續預訓練。這不是一般團隊能負擔的。論文用的是 Qwen3-4B,如果要遷移到其他基座模型,這個預訓練成本得重新算。
3. 語料更新的代價
RAG 的一個優勢是語料更新只需重建索引。MSA 的離線編碼階段意味著語料變動需要重新處理(雖然可能支持增量更新,但論文沒明確說)。
4. 尚未經過同行評審
論文發布在 Zenodo,不是 NeurIPS、ICML 這些頂會。EverMind AI 是盛大集團孵化的新公司,團隊實力需要更多作品來證明。
5. 只測了 4B 模型
MSA 在 4B 模型上效果驚人,但在 7B、14B、70B 上表現如何?規模效應是否線性?這些問題還沒有答案。

關鍵洞察
1. 「記憶」正在從外掛變成原生能力
RAG 是把記憶外掛到模型外面,MSA 是把記憶長進模型裡面。這個方向性的轉變,可能比具體數字更重要。
2. 位置編碼是長上下文的核心瓶頸
Document-wise RoPE 的設計揭示了一個被低估的問題:位置編碼的外推能力決定了模型能「看多遠」。不解決這個,堆再多硬體也沒用。
3. 端到端可微分是正確方向
RAG 最大的結構性問題就是 retriever 和 generator 各練各的。檢索錯了,生成器也學不到教訓。MSA 的端到端訓練讓整個系統可以從最終答案的品質反向優化每一環。
4. 小模型 + 好架構 > 大模型 + 笨架構
4B 打贏 235B 不是因為 4B 更聰明,是因為 MSA 的架構讓模型把算力花在刀刃上。這跟我一直說的一樣——架構設計的價值被嚴重低估。