[Agent 模式 Part 8] 告別「金魚腦」AI?Google 重磅發表 Nested Learning:讓模型擁有大腦般的長期記憶
![[Agent 模式 Part 8] 告別「金魚腦」AI?Google 重磅發表 Nested Learning:讓模型擁有大腦般的長期記憶](/assets/images/nested-learning-brain-memory.png "[Agent 模式 Part 8] 告別「金魚腦」AI?Google 重磅發表 Nested Learning:讓模型擁有大腦般的長期記憶")
Google Nested Learning:AI 終於可以「記住」東西了?
副標題: 當 Google 說「架構和訓練是同一件事」,他們到底在搞什麼?
人是怎麼記住事情的
大家都知道睡眠不佳會影響注意力跟記憶力,但很少人知道「人的大腦是怎麼記憶的」。
其實大腦有很明顯的短期記憶跟長期記憶。
短期記憶,比如臨時需要某個知識,你翻翻書看到了,立刻拿來使用,但一下子就忘了。考試前熬夜背的東西,考完立刻還給老師,就是這種。
長期記憶就不一樣了。有很多東西,練習很多次,一直走到一個境界,人家俗稱「讀懂了」、「融會貫通了」,那個就會進入到所謂的深層記憶裡面,很難忘記。騎腳踏車、游泳、母語,都是這種。
這兩種記憶不只是「記得久不久」的差別,而是大腦用完全不同的機制在處理。短期記憶靠的是「當下的神經活動」,長期記憶靠的是「突觸連結的改變」。
而且更關鍵的是:大腦會自動判斷哪些東西值得從短期記憶「升級」到長期記憶。這個機制發生在深層睡眠的時候——大腦會在你睡覺時「整理今天的資料」,判斷哪些記憶重要、值得保留,然後啟動類似「build index」的程序,把這些記憶轉成長期記憶寫入大腦。
這也是為什麼熬夜讀書效果差:你沒給大腦時間做索引建立。
現在的 AI 只有短期記憶
回頭看 LLM,問題就很清楚了。
用 Claude 或 ChatGPT 做專案的人,應該都有過這種經歷:上週你跟 AI 講了專案背景、技術架構、團隊分工,對話非常順暢。這週回來,它完全不記得你是誰。你只好再講一遍。
然後你開始理解,為什麼我們需要 RAG、需要 CLAUDE.md、需要每次對話都把 context 重新餵進去。
嚴格來說,LLM 是有長期記憶的——就是訓練時學到的權重,那是它「出廠時」就寫好的深層記憶。但問題是,出廠之後就不會再更新了。
它跟你對話時用的是 context window,那是短期記憶。關掉視窗,context 就沒了。下次開新對話,一切從零開始。
換句話說,LLM 的長期記憶永遠停在出廠那一刻。它沒辦法把跟你的互動經驗寫入長期記憶——每次對話都像是第一次見面。
擴大短期記憶,不等於擁有長期記憶
現在業界的解法是什麼?
擴大 context window。 從 4K 到 8K、32K、128K、甚至 200K tokens。
這確實有用。但本質上,這只是把短期記憶的容量加大,並沒有解決「沒有長期記憶」的根本問題。
Google Research 的團隊用了一個很精準的比喻:
“That’s like treating amnesia with a bigger notepad.”
失憶症患者的問題不是筆記本太小,而是大腦無法形成新的長期記憶。你給他再大的筆記本,他還是記不住昨天發生的事。
LLM 也是一樣。不管 context window 多大,它都只能「暫時記住」這個對話裡的內容。短期記憶再大,關掉視窗還是沒了。
Fine-tuning 呢?可以讓模型學習新知識,但代價是「災難性遺忘」——學新的,忘舊的。這就像你為了記住新同事的名字,結果忘了老朋友叫什麼。
Google 的反直覺發現
Google Research 在 NeurIPS 2025 發表了一篇論文,叫做 Nested Learning: The Illusion of Deep Learning Architecture。
標題就很挑釁:深度學習架構是一種「幻覺」?
他們的核心觀點是:
模型架構和訓練規則,本質上是同一件事的不同層級。
傳統觀點把「模型」和「訓練演算法」分開看——Transformer 是模型,Adam 是優化器,兩者是獨立的。
但 Google 團隊說:不對。Adam 這種優化器,本質上是一個「關聯記憶模組」,它的工作是壓縮梯度資訊。如果你從這個角度重新理解,優化器其實是模型的一部分,只是更新速度不同。
這聽起來很抽象,但意義很重大。如果優化器是記憶模組,那我們可以設計「更有表達力的記憶」,讓模型在推理過程中持續學習。
向大腦學習:快慢迴路
Nested Learning 的靈感來源,其實是神經科學。
大腦在處理資訊時,並不是單一速度。它有:
- 快速迴路(皮質):處理當下發生的事,反應即時
- 慢速迴路(海馬迴→皮質):在睡眠時整合記憶,把重要的模式固化成長期記憶
這就是為什麼你可能上午學了一堆東西,但真正「記住」是在睡一覺之後。
Nested Learning 把這個概念搬到 LLM 上:
不同層級的記憶,應該用不同的速度更新。
Nested Learning 的三個核心組件
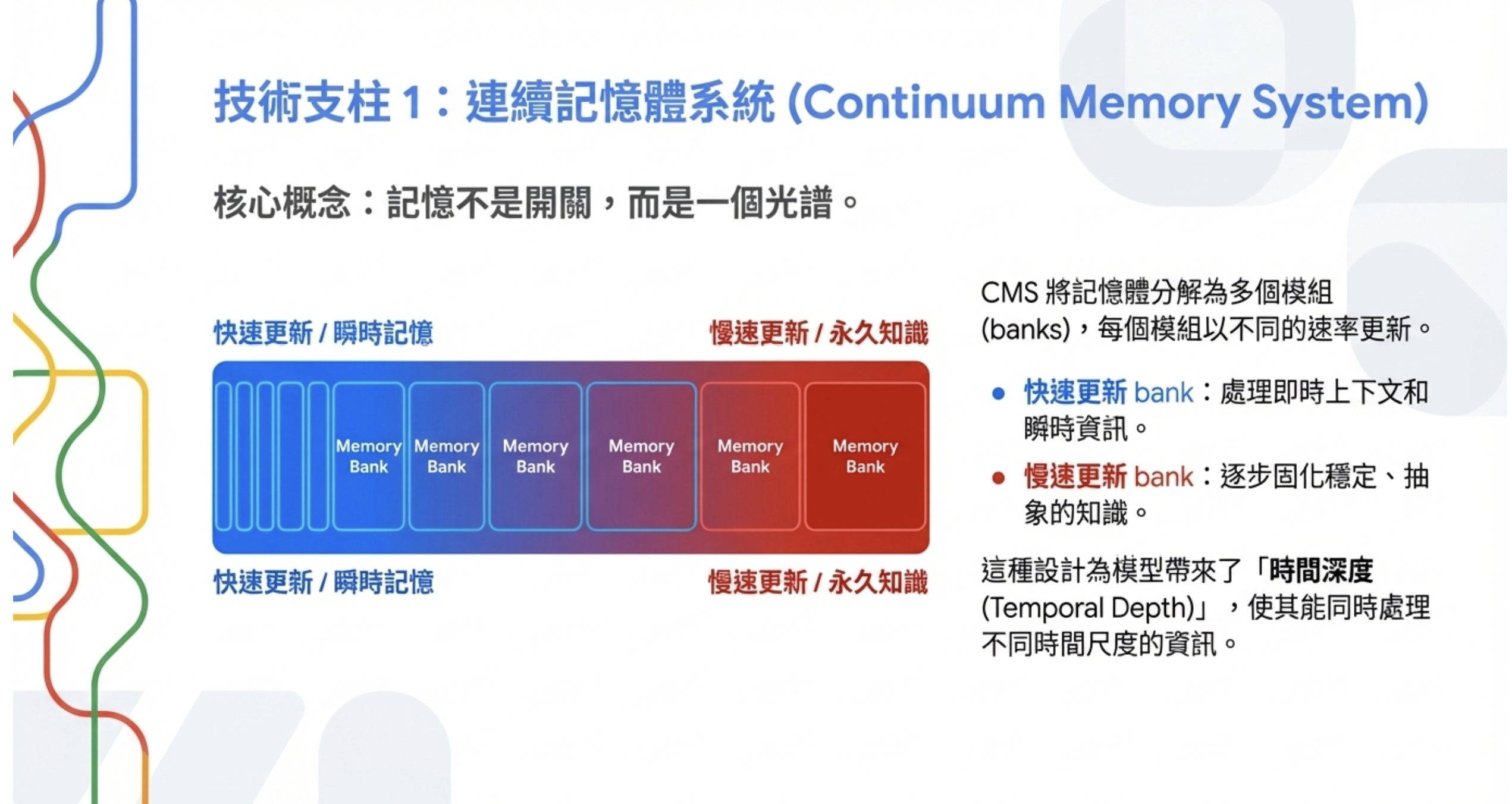
1. Continuum Memory System (CMS) — 連續記憶體系統
CMS 把模型的記憶分成多個「bank」,每個 bank 以不同速率更新:
| 記憶層級 | 更新速度 | 功能 |
|---|---|---|
| 最快層 | 即時 | 處理當前 token |
| 快速層 | 快 | 維持 context window |
| 中速層 | 中 | 累積對話模式 |
| 慢速層 | 慢 | 固化重要知識 |
這給模型帶來了「時間深度」——不只是看眼前的 context,而是能夠累積跨時間的抽象知識。
對比大腦:
| 大腦 | CMS |
|---|---|
| 感覺記憶(毫秒) | 最快層 |
| 工作記憶(秒~分鐘) | 快速層 |
| 短期記憶 | 中速層 |
| 長期記憶 | 慢速層 |
| 海馬迴(記憶整合) | Self-modifying loop |
2. Deep Momentum Gradient Descent — 深度動量梯度下降
這是技術上最關鍵的洞察:
常見的梯度優化器(Adam、SGD with Momentum),本質上是「關聯記憶模組」。
它們的工作是記住過去的梯度資訊,用這些資訊來調整學習方向。從這個角度看,優化器不是「訓練模型的工具」,而是「模型的一部分」——只是更新速度比 weights 更慢。
基於這個洞察,Google 設計了更深、更有表達力的「記憶優化器」,讓模型在推理過程中可以持續學習。

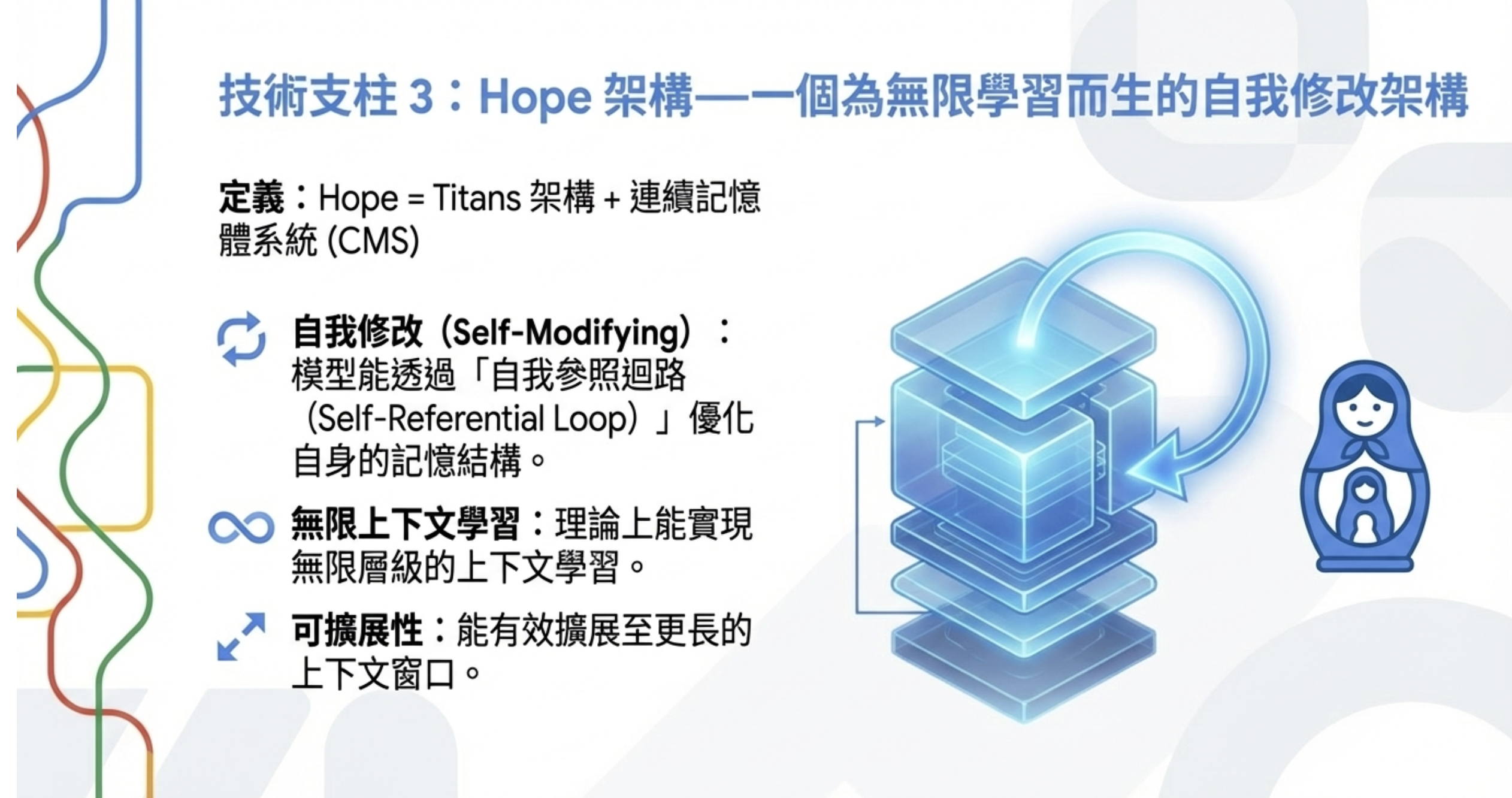
3. Hope Architecture — 自我修改架構
Hope = Titans 架構 + CMS
關鍵特點:
- 自我修改(self-modifying):模型可以優化自己的記憶
- 理論上無限層級的 in-context learning:不受固定 context window 限制
- 自我參照迴路(self-referential loop):模型自己決定什麼資訊要寫入哪一層記憶
這有點像大腦的「後設認知」——你不只在思考,你還在思考「怎麼思考」。
實驗結果:真的有用嗎?
Google 測試了 340M、760M、1.3B 參數的版本,訓練資料量 100B tokens。
對比模型包括:Transformer++、RetNet、Titans、DeltaNet。
結果:
| 模型 | 參數量 | Benchmark 平均分 |
|---|---|---|
| Transformer++ | 1.3B | 52.25 |
| Titans | 1.3B | 56.82 |
| Hope | 1.3B | 57.23 |
測試項目包括 PIQA、HellaSwag、BoolQ 等常見任務。
這個提升幅度說大不大,說小不小。更重要的是,這是一個全新的架構方向,而不是在現有架構上調參數。
坦白說:這離落地還很遠
我必須誠實講幾個問題:
目前只測試到 1.3B 參數。 這離 GPT-4 級別的幾百 B 參數還差很遠。能不能 scale up,還是未知數。
沒有開源實作。 論文是發了,但目前沒有公開的程式碼可以跑。這意味著其他團隊要複製結果,需要從頭實作。
推理成本不明。 多層記憶系統必然增加計算複雜度,但論文沒有詳細分析推理時的 overhead。
實際應用場景待驗證。 Benchmark 分數提升是一回事,真實任務表現是另一回事。
這對我們有什麼意義?
假設 Nested Learning 成熟並且被主流模型採用,可能會改變幾件事:
RAG 的必要性可能降低。 如果模型能真正「記住」專案背景,我們就不需要每次都從向量資料庫撈資料餵給它。
CLAUDE.md 這類 workaround 可能消失。 目前我們用長文件建立專案 context,因為 AI 記不住。如果它能記住,這些 workaround 就不需要了。
Agent 可以真正累積經驗。 現在的 Agent 每次任務都是從零開始。如果有持續學習能力,Agent 可以從過去的任務中學習,越用越強。
個人化 AI 助手成為可能。 AI 可以記住你的習慣、偏好、工作方式,不需要每次都重新說明。
但這些都是「假設」。目前這篇論文還在學術階段,離產品化還有很長的路。
關鍵洞察
「架構和訓練是同一件事」是思維突破。 這不是漸進式改進,而是重新定義問題。過去我們把 Transformer 和 Adam 分開看,現在 Google 說它們是同一個系統的不同層級。這種視角轉換,往往是重大突破的起點。
向大腦學習是正確方向。 大腦已經解決了「持續學習而不遺忘」的問題幾億年。Nested Learning 的多層記憶架構、快慢更新速率,都是借鏡神經科學。這比純數學優化更有潛力。
短期內不會改變我們的工作方式。 這是學術研究,不是產品。即使 Google 內部在做產品化,至少也要 1-2 年才可能看到。我們還是要繼續用 RAG、用 CLAUDE.md、用各種 workaround。
但這指出了一個方向。 LLM 的記憶問題不是無解,而是需要架構層面的創新。Nested Learning 證明了這個方向是可行的。
結語
Nested Learning 不是銀彈,但它指出了一個被忽略的問題:我們一直在用「更大的短期記憶」來解決「沒有長期記憶」的問題。
真正的解法,可能是讓 AI 像大腦一樣,擁有多層、多速度的記憶系統——快的處理當下,慢的固化知識,自動決定什麼值得寫入長期記憶。
這篇論文的價值,不只是提升了幾個百分點的 benchmark 分數,而是打開了一扇門:
模型不只是固定的權重矩陣,而是可以持續進化的記憶系統。
當 AI 終於擁有真正的長期記憶,它才有可能從「工具」變成「夥伴」。
題外話
題外話,長期記憶也不是放進去就永遠好拿。長期記憶像是一個櫃子,如果某個記憶進去之後太久沒用,大腦會慢慢把它放到櫃子的深處——不是遺忘,是變得不好存取。所以要想起來會比較慢,需要更多提示才能 recall。
這也是為什麼教學時會有抽測跟考試:逼大腦不定時存取這些記憶,大腦就會把它放在櫃子比較前面的位置。IT 人應該秒懂——這就是 LRU(Least Recently Used) 的概念,最近常用的放前面,很久沒用的往後丟。
常見問題 Q&A
Q: Nested Learning 跟 RAG 有什麼不同?
RAG 是「外掛記憶」——用向量資料庫存資料,推理時檢索。模型本身還是不會學習。Nested Learning 是「內建記憶」——模型在運作過程中持續更新自己的記憶。兩者可以互補,但解決問題的方式完全不同。
Q: 這跟 Fine-tuning 有什麼差別?
Fine-tuning 是離線訓練,更新完成後模型就固定了。而且 Fine-tuning 會災難性遺忘。Nested Learning 是線上學習,在推理過程中持續更新,而且用多層記憶系統避免遺忘。
Q: 什麼時候我們能用到這個技術?
保守估計 1-2 年。這篇論文剛發表,還沒有開源實作,也沒有在大規模模型上驗證。即使 Google 內部在做產品化,也需要時間。
Q: 這會讓 prompt engineering 消失嗎?
不會。Nested Learning 解決的是「長期記憶」問題,不是「理解指令」問題。你還是需要清楚地告訴 AI 你要什麼。但你可能不需要每次都解釋專案背景了。
延伸閱讀
- Google Research Blog: Introducing Nested Learning
- 原始論文: Nested Learning: The Illusion of Deep Learning Architecture
- VentureBeat 報導: Google’s ‘Nested Learning’ paradigm could solve AI’s memory problem
相關連結:
- 部落格首頁:https://ai-coding.wiselychen.com
- LinkedIn:https://www.linkedin.com/in/wisely-chen-38033a5b/