AI Agent 時代的無聊基礎建設:地端 OCR API

大家都在講 AI Agent,講 Multi-Agent,講 Agentic Workflow。
但我發現一個有趣的現象:幾乎沒人在講「基礎建設」。
就像蓋房子,所有人都在討論室內設計要多漂亮,但沒人想聊地基怎麼打。
無聊但重要的基礎建設
我這個人還滿享受「基礎建設優化」這件事情的,就像雙十一,大家都想到電商如何行銷策略,但是我一個 IT 人,我是真的雙十一會跑去倉庫現場檢貨,體驗電商的基礎建設。
這幾天大家談 AI Agent、Gemini 3.0 Pro、Nano Banana Pro,但很少人談地端 OCR API 這個「無聊的基礎建設」。沒有它,企業的 AI Agent 根本看不見 60–70% 躺在 PDF 裡的資料(合約、發票、規格書、掃描檔)。因為很多 enterprise 又不能上雲,地端 Agent 沒用。
什麼是好架構
當然關於 OCR API,現在任何會 Vibe Coding 的人幾分鐘就能做出一個能跑的 OCR,但設計的人的「架構品味」好不好真的是另一回事。
最近看到一個挺 solid 的 “Bare Metal” 架構:https://github.com/markuskuehnle/credit-ocr-system
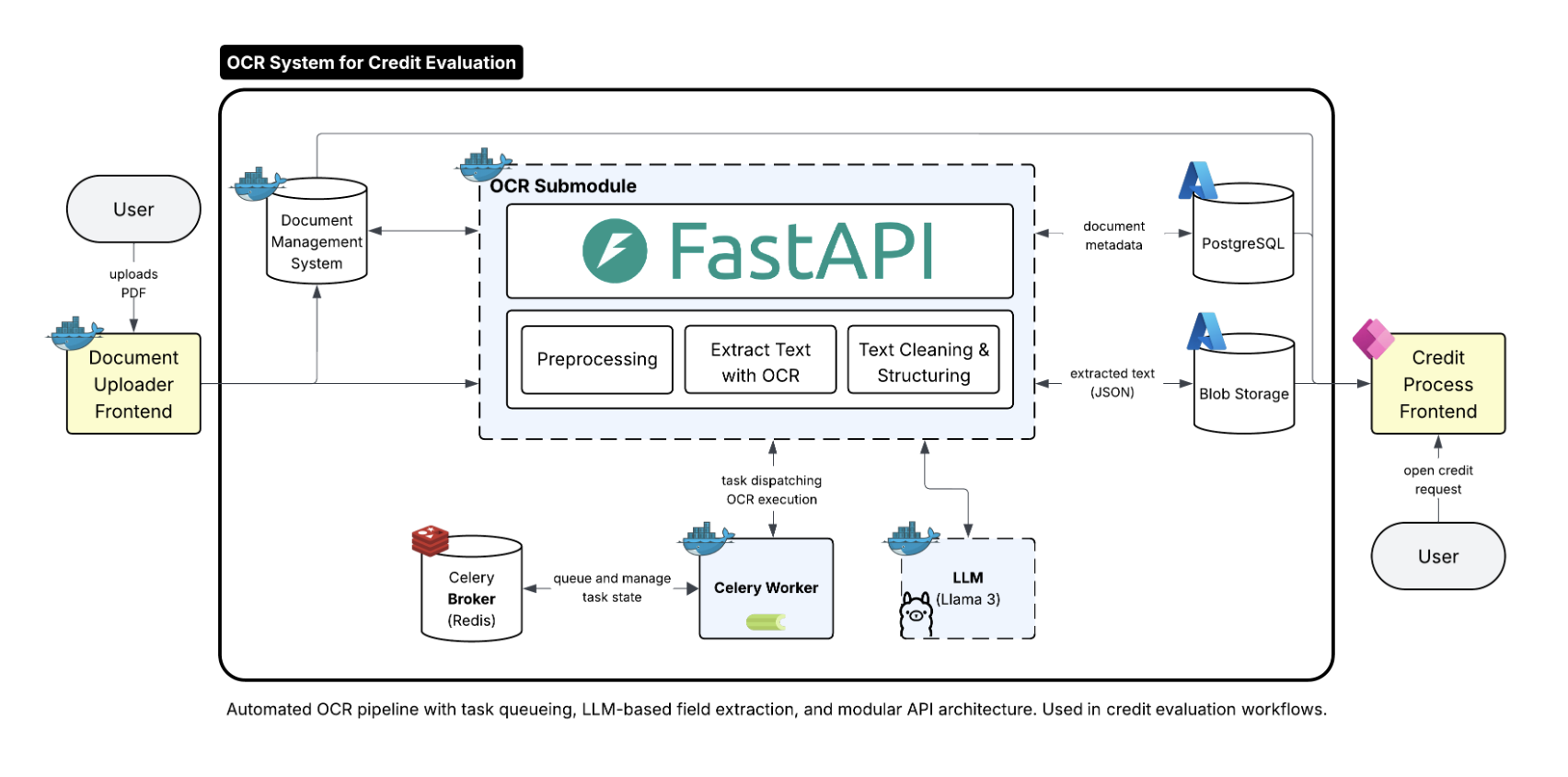
為什麼好?
-
MQ 緩衝 - OCR 處理時間不穩定,圖片大小影響資源太多。MQ 讓流量平整,尖離峰時間 resource 差距不會太大
-
故障隔離 - OCR worker 掛了,其他 pipeline 不受影響
-
水平擴展 - 可以根據 SLA 動態調整 worker 數量
當然這個東西跟 Paperless-ngx 這樣的生產級別的系統,還是弱了點。但是賣點是 source 量是 paperless-ngx 的 1/20,可發展空間好多了。加上在 Vibe Coding 的大時代,有一個很漂亮的架構 Bare Metal 骨架,可以很輕鬆地 Vibe Coding 擴充功能。
既然是地端,有一些成本,像是硬體層面擁抱 CPU 非 GPU。OCR 使用 RapidOCR + ONNX Runtime,可以降低 infra 成本
但魯棒性還有五個坑要注意,不然還是會掛:
-
Dead Letter Retry 機制 - 這是我在 Google 面試 Data Engineer 的考題,一考一個準
-
Docker 資源管理 - 避免 local LLM & OCR 把 Docker Host 拖垮
-
Timeout 與 SLA 綁定 - 不同客戶不同要求,要能調整
-
Document Idempotency - 需要 doc ID 避免重複處理
-
Log Sanitization - OCR 處理很多機敏資料(信用卡拍照),金融企業要特別注意
在 AI可以做每一件事情的時候,我們需要啥?
當產生「系統」的能力已經很廉價的年代,鑒賞「系統」的能力反而變成稀缺。地端 OCR API 很無聊,但這種無聊的基礎建設,才是 AI Agent 真正落地的關鍵。