OneFlow 演算法:重新思考 Multi-Agent 的價值

過去一年,Multi-Agent(多智能體)幾乎變成 AI 工作流的政治正確。
當單一 Agent 表現遇到瓶頸,直覺式的解法就是一句話:「人不夠多,再加幾個 Agent。」
這聯繫很合理。畢竟人類社會不也是這樣運作的嗎?一個人做不完,就找更多人來幫忙。
但來自德克薩斯大學奧斯汀分校與 Amazon 團隊的一篇論文 Rethinking the Value of Multi-Agent Workflow,直接對這股風潮潑了一盆冷水。
論文的核心結論非常直接:
很多 Multi-Agent 系統,並沒有你想像中那麼聰明,反而是在燒錢。
OneFlow 的成績單
在我深入解釋之前,先看數據。
OneFlow 是一個單一 Agent 架構,但它的表現:
| Benchmark | OneFlow 成績 | 說明 |
|---|---|---|
| HumanEval(程式碼生成) | 92.1% | 追平甚至超過多種複雜 Multi-Agent 基線 |
| GSM8K(數學推理) | 93.3% | 同樣追平或超越 Multi-Agent 方案 |
關鍵是:
- 推理成本顯著更低
- 系統複雜度大幅下降
- 不需要協調多個 Agent 之間的溝通
這對「Multi-Agent 一定更強」的信仰來說,是一次正面衝擊。
為什麼讓人不舒服?致命的技術限制:KV Cache
因為它挑戰了一個直覺假設:
單一 Agent 能力有限 → 用多個 Agent 分工協作 → 整體能力上升
這個假設在人類世界是對的。一個人蓋不了房子,十個人可以。
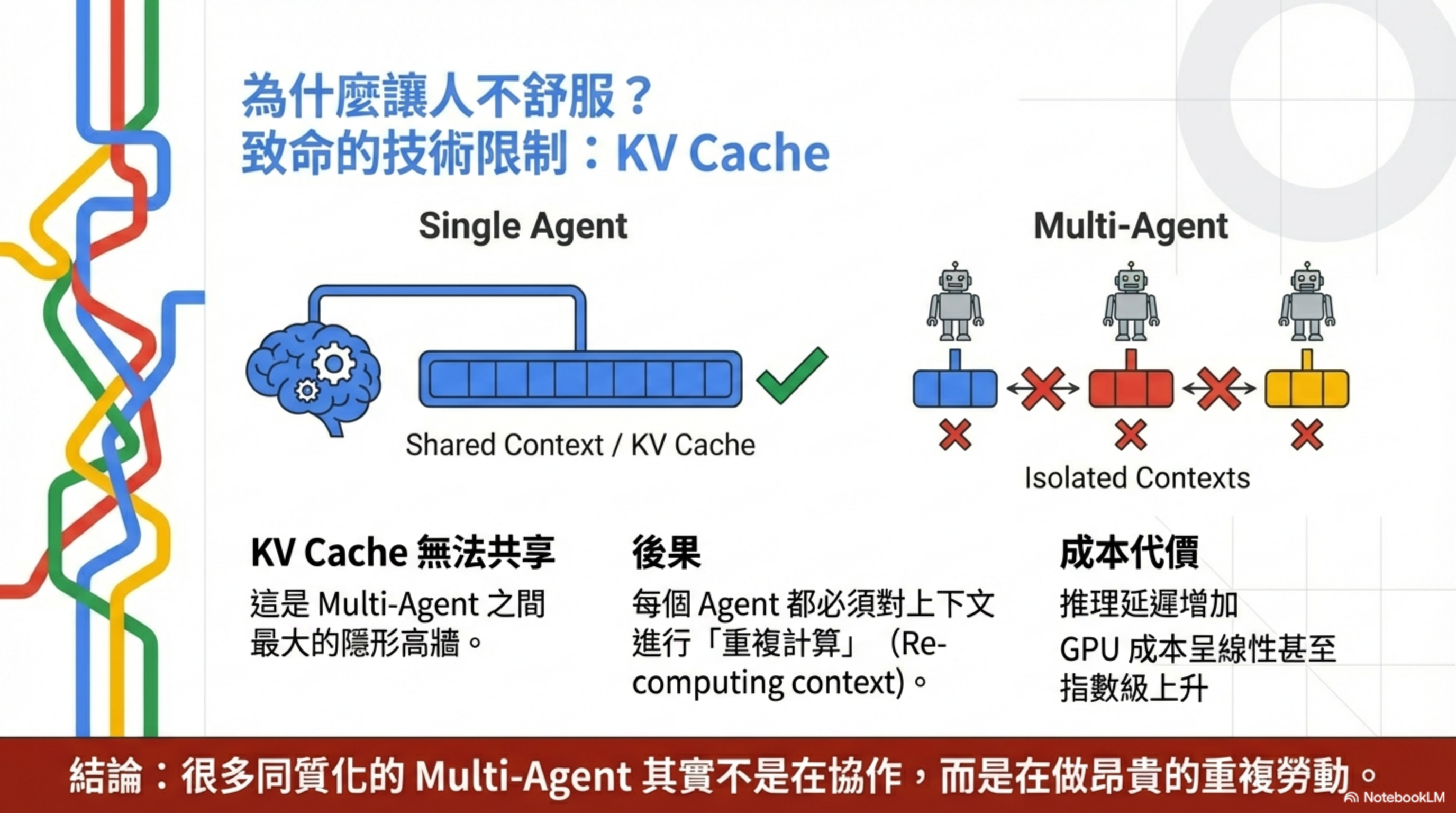
但在 LLM 的世界,這個假設有一個致命的技術限制:KV Cache 無法共享。
這是論文中點出的一個關鍵、但常被忽略的技術現實。
什麼是 KV Cache?簡單講,就是 LLM 在推理過程中,會把之前處理過的 token 的中間計算結果存起來,下一個 token 就不用重算。這是 LLM 能夠快速回應的核心機制之一。
但問題來了:Multi-Agent 之間,KV Cache 無法共享。
結果是什麼?
- 每個 Agent 都在重複消耗上下文計算
- 推理延遲增加
- GPU 成本線性甚至指數級上升
換句話說,很多同質化的 Multi-Agent 並不是在協作,而是在做重複勞動。
這也是為什麼在真實生產環境中,你會發現:
- Demo 很炫
- 帳單很痛
OneFlow 的解法:將外部協調轉為「內部推理」
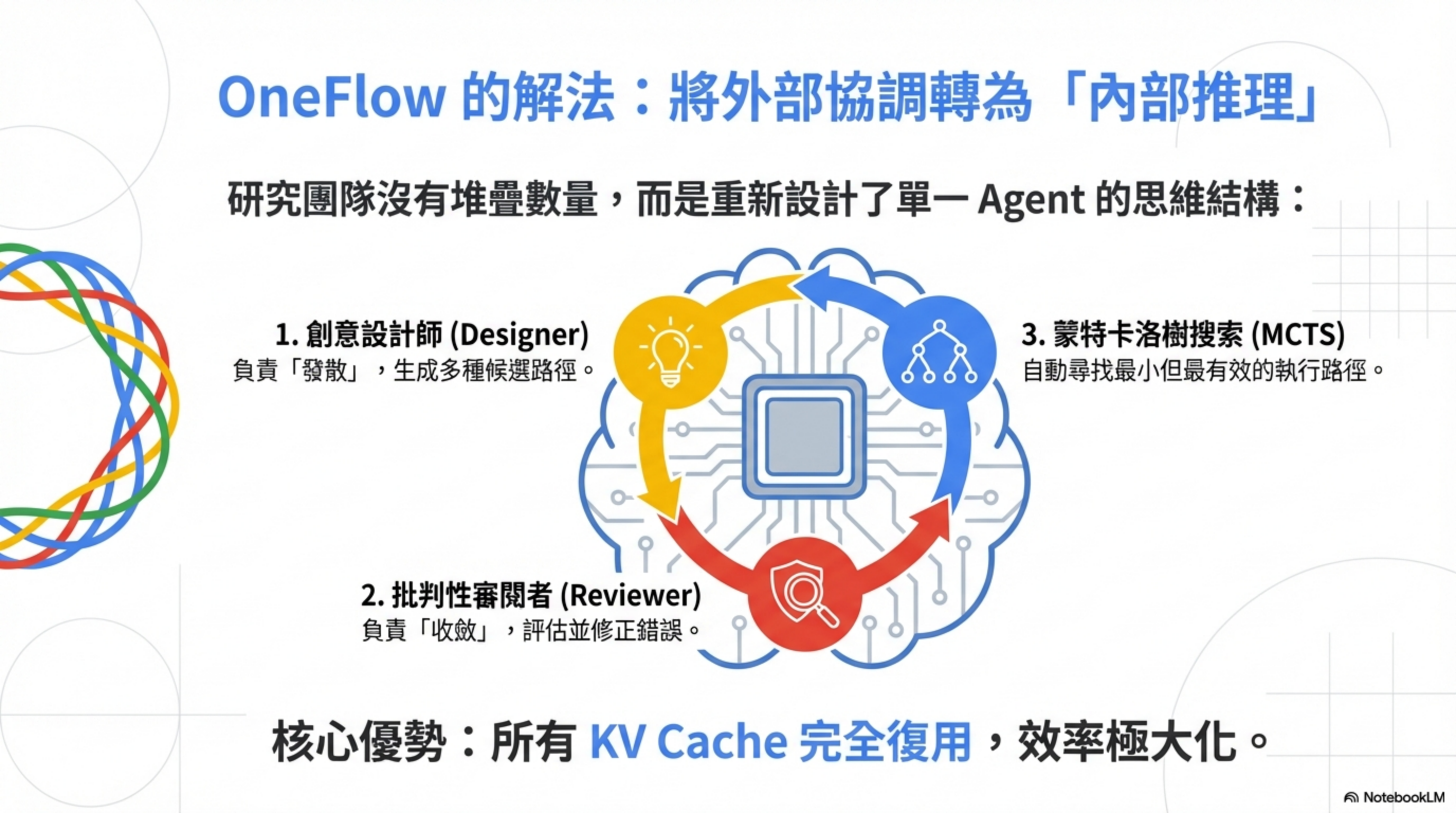
研究團隊沒有堆 Agent 數量。他們重新設計了單一 Agent 的內部結構與搜索策略。
核心是一個雙元角色架構:
1. 創意設計師(Designer)
負責生成候選解法。這個角色的任務是「發散」—— 盡可能想出多種可能的路徑。
2. 批判性審閱者(Reviewer)
負責評估、否定、修正。這個角色的任務是「收斂」—— 篩選出最有可能成功的路徑。
3. 蒙特卡洛樹搜索(MCTS)
結合上述兩個角色,自動探索「最小但最有效」的執行路徑。
這三個東西加在一起,本質上是把 Multi-Agent 的「外部協調」變成了「內部推理」。
重點是:這一切,發生在單一 LLM Agent 內部。
什麼時候 Multi-Agent 還是有價值的?
我不是說 Multi-Agent 完全沒用。但它需要被證明「真的有必要」。
Multi-Agent 有價值的場景
- 真正的專業分工:不同 Agent 使用不同的 base model,各自針對特定任務優化
- 資訊隔離需求:安全性考量,某些 Agent 不應該看到全部 context
- 物理分散:Agent 運行在不同的地理位置或基礎設施上
- 人類協作模擬:真的需要模擬多人討論、辯論的場景
Multi-Agent 只是在燒錢的場景
- 同質化 Agent:多個 Agent 用同一個 model,只是 prompt 不同
- 串行依賴:Agent A 做完才能給 Agent B,沒有真正的並行優勢
- 過度分解:把一個 Agent 能做的事拆成三個 Agent 做
如果你的 Multi-Agent 系統裡,每個 Agent 都用同一個 model、都能看到同樣的 context、只是 prompt 不同 ——
恭喜你,你不是在做 Multi-Agent,你是在做「昂貴的單一 Agent」。
這讓我想到之前寫的 Claude Code 架構分析
讀到這裡,你可能會問:那 Anthropic 的「雙 Agent 架構」呢?那不也是 Multi-Agent 嗎?
這是一個很好的問題,也是我之前在 Anthropic 官方解密:為什麼 Claude Code 這麼好用? 這篇文章分析過的主題。
答案是:完全不一樣的東西。
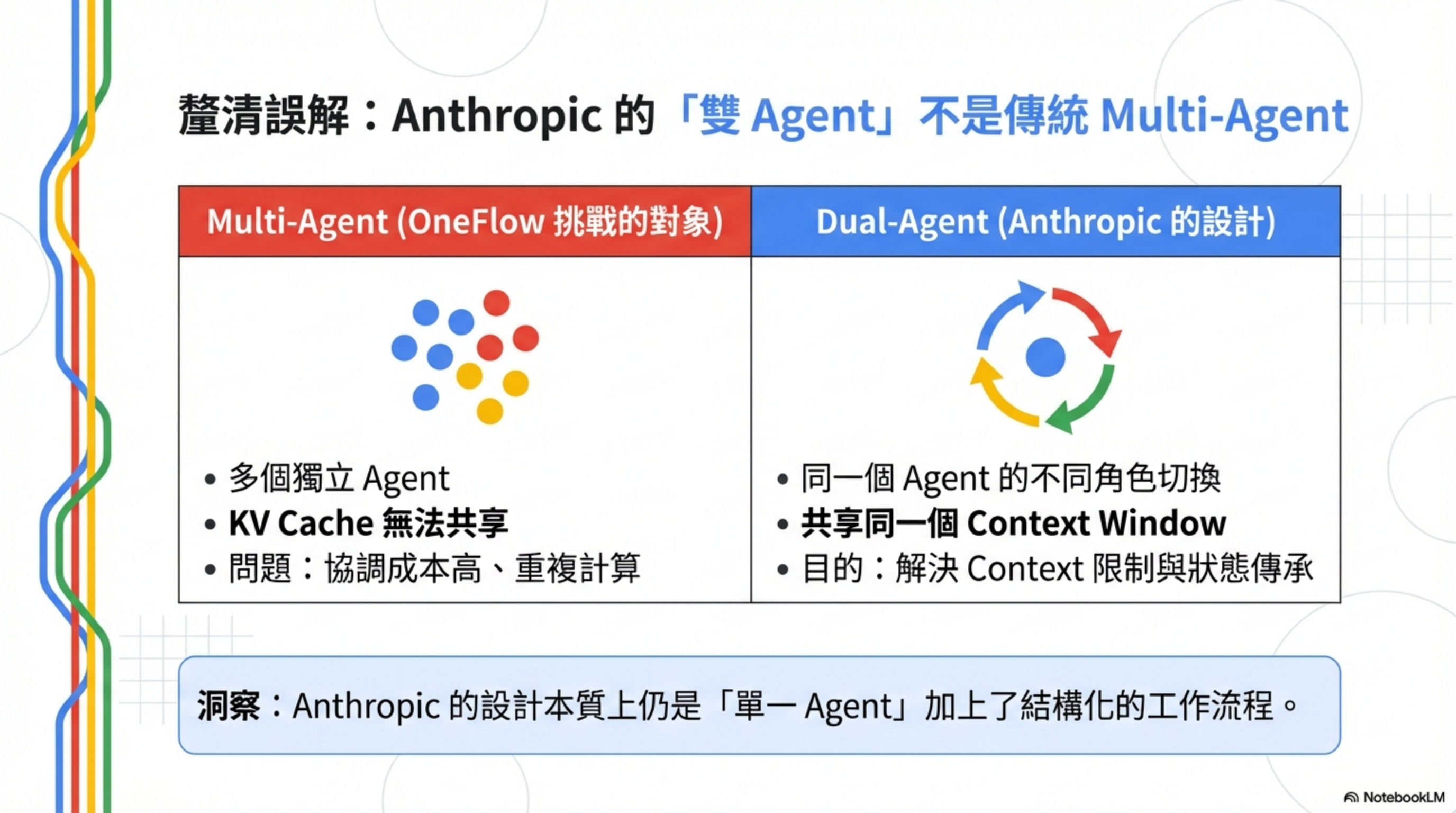
OneFlow 批評的 Multi-Agent vs Anthropic 的 Dual-Agent
| 維度 | Multi-Agent System(OneFlow 挑戰的對象) | Dual-Agent Architecture(Anthropic 的設計) |
|---|---|---|
| Agent 數量 | 多個獨立 Agent 同時運作 | 同一個 Agent 的不同角色 |
| 資源消耗 | 每個 Agent 獨立消耗 context | 共享同一個 context window |
| KV Cache | 無法共享(OneFlow 的核心批評) | 不存在這個問題 |
| 設計目的 | 分工協作 | 解決 context window 限制 |
| 典型問題 | 協調成本、重複計算 | 狀態傳承、長時任務管理 |
Anthropic 的雙 Agent 架構解決的問題是:
「context window 會用完」,而不是「一個 Agent 不夠強」。
當任務需要幾十到數百個功能時,單一 context window 裝不下所有資訊。Anthropic 的解法不是「加更多 Agent」,而是:
- 結構化狀態記錄:用 JSON manifest + git + progress file 保存任務狀態
- 角色切換:同一個 Agent 在不同階段扮演不同角色(Initializer → Coding Agent)
- 跨 session 傳承:每次新 session 開始時,Agent 先「Onboarding」自己
這更像是給 Agent 設計一套工作方法論,而不是「找更多 Agent 來幫忙」。
核心洞察:Anthropic 的「雙 Agent」本質上還是 OneFlow 說的「單一 Agent」—— 只是加上了結構化的工作流程。
我用 Claude Code 的實戰印證
我自己用 Claude Code 的經驗,其實也印證了 OneFlow 的觀察。
Claude Code 本質上就是一個「超級個體」—— 它不是靠多個 Agent 協作來完成任務,而是單一 Agent 具備多種能力:
- 寫 code
- 去相關 PRD 抓 spec
- 啟動 python venv
ps檢查 process 狀態netstat看 port 狀況curl測試 API- 掃 log 找錯誤
top看 CPU 佔用kill -9重啟服務- 包 Docker 和 K8S
- 部署到 Google Cloud
這一切,Claude Code 都可以完全不需要人介入就完成。
為什麼?因為所有狀態都在同一個 context 裡面,不需要在不同 Agent 之間傳遞、翻譯、對齊。
單一 Agent + 完整工具集 + 足夠強的推理能力 = 比多個 Agent 更有效率。
對 2026 的預測
如果 2024-2025 的關鍵詞是:
「Agent 越多,看起來越先進」
那 2026 的關鍵詞很可能會變成:
極致能效比(Cost / Performance)
原因很簡單:
- LLM 本身在變強:單一 Agent 的能力上限在快速提升
- 成本壓力在增加:企業開始認真算 AI 的 ROI
- 複雜度稅在累積:Multi-Agent 系統的維護成本會隨時間指數增長
對企業與個人來說,這是一件非常現實的好消息:
- 更少的模型調用
- 更低的 GPU 成本
- 更可控的系統複雜度
真正的趨勢:從「堆 Agent」到「優化工作流」
把 OneFlow 和 Anthropic 的架構放在一起看,我看到的趨勢是:
2024: 「任務太複雜?加更多 Agent!」 2025: 「等等,這樣成本爆炸了…」 2026: 「單一強 Agent + 結構化工作流 = 最佳解」
Anthropic 的雙 Agent 架構和 OneFlow 的結論其實是殊途同歸:
- OneFlow 說:把多 Agent 的協作能力「內化」到單一 Agent 裡
- Anthropic 說:給單一 Agent 設計結構化的工作方法論
兩者都在說同一件事:不要用「加人頭」解決問題,要用「優化流程」解決問題。
決策框架:你該選哪種架構?
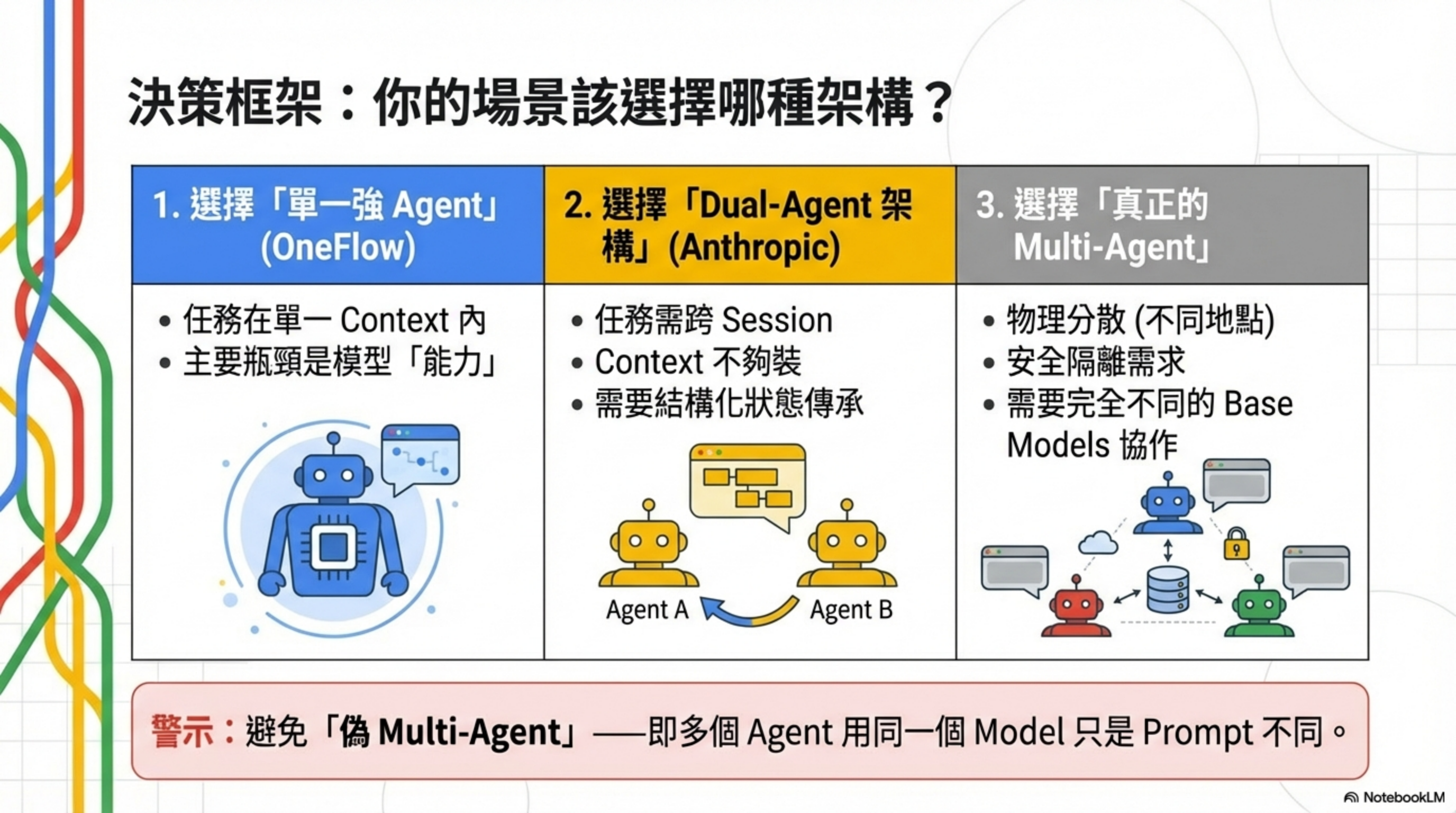
把這篇文章的分析整理成一個簡單的決策框架:
選擇「單一強 Agent」(OneFlow 路線)當:
- 任務可以在單一 context window 內完成
- 你用的是同一個 model
- 主要瓶頸是「能力」而不是「記憶」
選擇「Dual-Agent 架構」(Anthropic 路線)當:
- 任務需要跨越多個 session
- Context window 不夠裝所有資訊
- 需要結構化的狀態傳承機制
選擇「真正的 Multi-Agent」當:
- 不同 Agent 用不同的 model(真正的專業分工)
- 有安全隔離需求
- 需要物理分散或跨組織協作
- 本質上是「多人協作」的場景
避免「偽 Multi-Agent」:
- 多個 Agent 用同一個 model
- 只是 prompt 不同
- 串行執行沒有並行優勢
- 可以用單一 Agent + 更好的 prompt 解決
一個留給所有人的問題
如果你是決策者,你會選擇哪一個?
- 雇用一群普通 AI 助理,彼此開會、彼此懷疑、彼此重複工作
- 還是打造一個被優化到極致、能獨立完成任務的「全能單兵」
也許,OneFlow 給出的答案已經很清楚了。
坦白說
這篇論文的結論,可能會讓很多正在做 Multi-Agent 的團隊感到不舒服。
我自己的看法是:Multi-Agent 不會消失,但它會從「默認選項」變成「需要被證明的選項」。
就像微服務架構一樣 —— 不是不好,但「為什麼要拆」這個問題,應該先於「怎麼拆」。
同樣的邏輯:
「為什麼需要多個 Agent」這個問題,應該先於「怎麼讓 Agent 協作」。
延伸閱讀
- Anthropic 官方解密:為什麼 Claude Code 這麼好用? —— 深入理解 Dual-Agent 架構如何解決長時任務問題
論文資訊
論文標題: Rethinking the Value of Multi-Agent Workflow: A Strong Single Agent Baseline
arXiv ID: 2601.12307
作者團隊: 德克薩斯大學奧斯汀分校 + Amazon
核心貢獻:
- 提出 OneFlow 算法,證明單一 Agent 可以達到 Multi-Agent 同等甚至更好的效果
- 點出 KV Cache 無法共享這個被忽略的技術限制
- 建議將「優化到極致的單一 Agent」作為 Multi-Agent 研究的強力 baseline
Wisely Chen / 2026-01-27