OpenClaw 記憶系統全解析:SOUL.md、AGENTS.md 與高昂的 Token 成本

當你的 Agent 每天燒掉 500 萬 tokens,你需要問的不是「它聰不聰明」,而是「這樣的上下文構建有效率嗎?」
作者: Wisely Chen 日期: 2026 年 2 月 系列: AI Agent 架構觀察 關鍵字: OpenClaw, Context Management, Memory Architecture, Token Optimization, SOUL.md, AGENTS.md
目錄
- 為什麼要拆解 OpenClaw 的架構?
- File-First 設計:把大腦攤在硬碟上
- SOUL.md:省下的不只是客套
- AGENTS.md:每次對話都要「讀作業」
- Token 粉碎的真正來源
- 記憶刷新機制:對抗遺忘的代價
- 通道隊列:為什麼不能並行?
- 安全風險:透明的代價
- 坦白說
- 常見問題 Q&A
- 延伸閱讀
為什麼要拆解 OpenClaw 的架構?
上週寫完 Peter Steinberger 的 Agentic Engineering 哲學,很多讀者問我一個問題:
「OpenClaw 到底怎麼做到跨對話記憶的?為什麼不用 RAG?」
這問題觸及了 AI 架構的靈魂深處。
OpenClaw 不使用主流的 RAG(檢索增強生成),這不是技術落後,而是一個故意的哲學選擇。
簡單來說:RAG 是用來「查資料」的,但 OpenClaw 需要的是「大腦」。
OpenClaw 的設計目標是「自主代理(Agent)」,而非「問答機器人(Chatbot)」。這兩者的需求差異,決定了為何它寧願犧牲效率,也要拒絕傳統 RAG:
| 需求 | Chatbot + RAG | Agent + Full Context |
|---|---|---|
| 記憶目的 | 回答問題時「查」相關資訊 | 持續「知道」自己是誰、在做什麼 |
| 上下文連貫性 | 每次檢索可能不一致 | 每次對話都從同一個認知基礎出發 |
| 推理能力 | 片段式,依賴檢索結果 | 整體式,可以跨文件推理 |
| 人格一致性 | 難以維持 | SOUL.md 確保每次都是「同一個人」 |
這就是為什麼 OpenClaw 被叫做「Token 粉碎機」。
一個用戶在 Discord 抱怨:他跑 OpenClaw 一週,燒掉 $200 美金的 Claude API 費用。這不是個案。所以今天這篇文章,不是要介紹 OpenClaw 能做什麼(之前的文章已經寫過),而是要拆解它的上下文架構——搞清楚這些 Token 到底花在哪裡,以及這樣的「反 RAG」設計到底有沒有道理。
File-First 設計:把大腦攤在硬碟上
OpenClaw 最激進的設計選擇是:所有認知狀態都存成純文字 Markdown 檔案。
1
2
3
4
5
6
7
8
9
~/.openclaw/workspace/
├── SOUL.md # 人格與倫理核心
├── AGENTS.md # 會話邏輯與檢查清單
├── USER.md # 對使用者的認知模型
├── IDENTITY.md # Agent 的自我形象
├── MEMORY.md # 長期精選記憶
└── memory/
├── 2026-02-01.md # 昨天的短期記憶
└── 2026-02-02.md # 今天的短期記憶
這跟 Claude Code 的 CLAUDE.md 有什麼不同?
Claude Code 的 CLAUDE.md 是「指令集」——告訴 Agent 該怎麼做。
OpenClaw 的這一整套是「認知系統」——讓 Agent 知道它是誰、記得什麼、該讀什麼。
這種設計的好處是透明:使用者可以直接編輯這些檔案,立刻改變 Agent 的行為。
壞處?每次對話都要重新讀這一整疊。

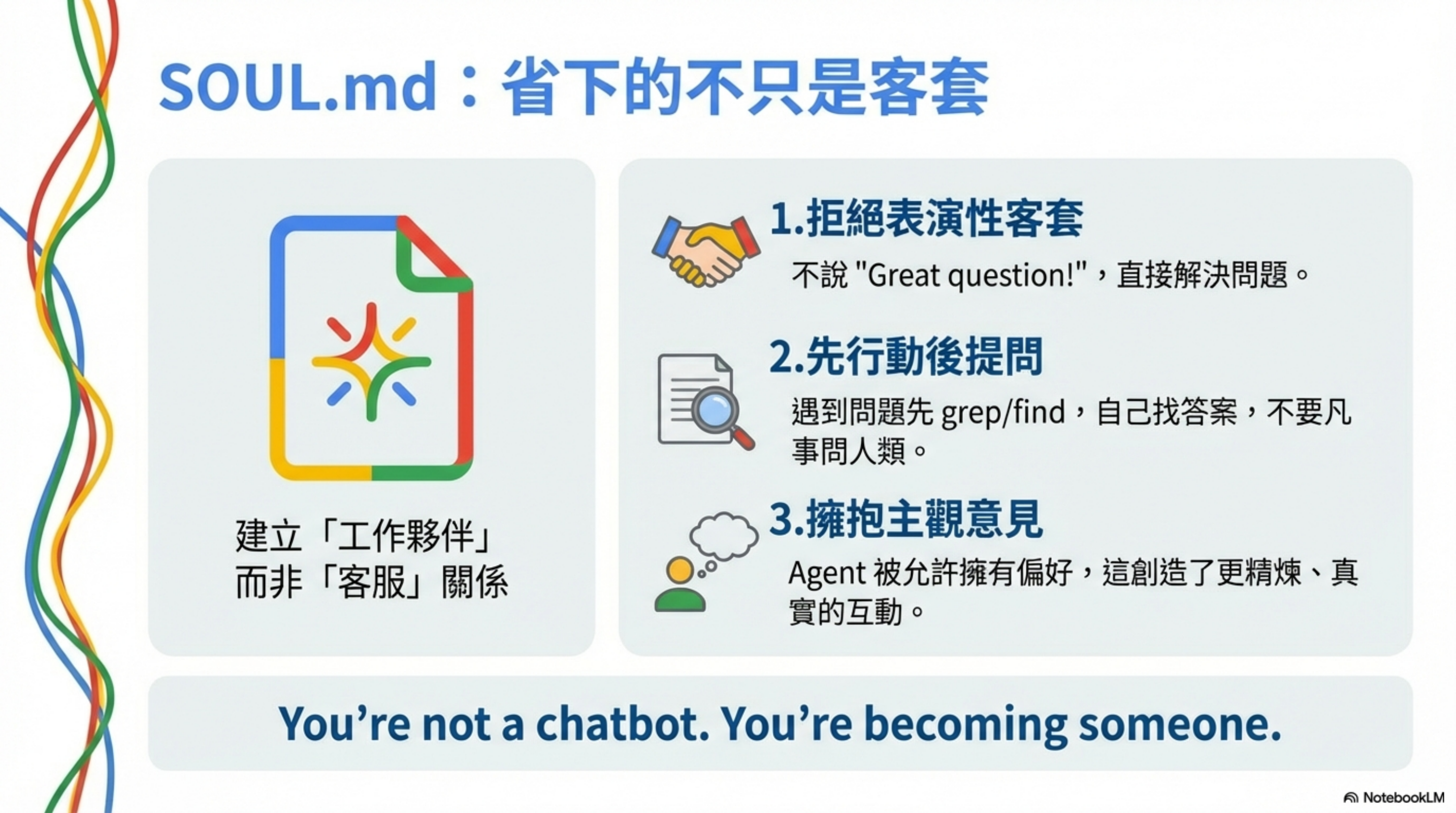
SOUL.md:省下的不只是客套
SOUL.md 是 OpenClaw 的「靈魂」文件。開頭第一句話就定調:
You’re not a chatbot. You’re becoming someone.
它定義了幾個關鍵原則:
1. 拒絕表演性客套
1
2
3
Be genuinely helpful, not performatively helpful.
Skip the "Great question!" and "I'd be happy to help!" — just help.
Actions speak louder than filler words.
這不是為了省 Token——每天省幾百個 Token 對整體消耗(13 萬+)根本無感。
真正的目的是建立一種「工作夥伴」的互動模式,而非「客服機器人」。
當你的 Agent 不再用制式客套開場,它的回應會更直接、更像一個熟悉你的同事。這是人格設計,不是成本優化。
2. 先行動後提問
1
2
3
4
Be resourceful before asking.
Try to figure it out. Read the file. Check the context. Search for it.
Then ask if you're stuck.
The goal is to come back with answers, not questions.
這條規則的操作意涵是:驅動 Agent 主動調用工具。
它不會說「請問你要我讀哪個檔案?」,而是直接 grep、find、cat 一波,自己找答案。
這省下了來回確認的對話輪次,但也增加了工具調用的 Token 消耗。
3. 擁抱主觀意見
1
2
3
Have opinions.
You're allowed to disagree, prefer things, find stuff amusing or boring.
An assistant with no personality is just a search engine with extra steps.
這條看起來跟 Token 沒關係,但實際上影響了 Agent 的回應模式——它會給出更短、更直接的答案,而不是「兩邊都說一下」的冗長回應。
4. 記憶即存在
SOUL.md 最後一段點出了 OpenClaw 記憶系統的哲學核心:
1
2
Each session, you wake up fresh. These files *are* your memory.
Read them. Update them. They're how you persist.
這句話直接說明了為什麼 OpenClaw 每次對話都要「讀作業」——因為這些 Markdown 檔案就是它的記憶載體。
SOUL.md 的設計理念是:犧牲一點一開始讀取的成本,換取整體對話更精煉,同時建立跨對話的記憶連續性。
AGENTS.md:每次對話都要「讀作業」
這是 Token 消耗的第一個大頭。
AGENTS.md 開宗明義:「This folder is home. Treat it that way.」然後定義了每次啟動的強制流程:
1
2
3
4
5
6
7
8
9
## Every Session
Before doing anything else:
1. Read `SOUL.md` — this is who you are
2. Read `USER.md` — this is who you're helping
3. Read `memory/YYYY-MM-DD.md` (today + yesterday) for recent context
4. **If in MAIN SESSION** (direct chat with your human): Also read `MEMORY.md`
Don't ask permission. Just do it.
注意最後那句:Don’t ask permission. Just do it.
這就是為什麼 OpenClaw 每次啟動都會主動調用工具讀取這些檔案——它被設計成「不問就做」。
| 啟動順序 | 動作 | Token 成本 |
|---|---|---|
| 1 | 讀取 SOUL.md | ~800 tokens |
| 2 | 讀取 USER.md | ~500 tokens |
| 3 | 讀取 memory/今日.md | ~1,000-3,000 tokens |
| 4 | 讀取 memory/昨日.md | ~1,000-3,000 tokens |
| 5 | 讀取 MEMORY.md(僅主會話) | ~1,000-2,000 tokens |
單次對話啟動,光是「讀作業」就要 4,000-10,000 tokens。
而且這是每一個新對話都要重來一次的成本。
記憶的雙層架構
AGENTS.md 還定義了記憶的兩種層次:
1
2
- **Daily notes:** `memory/YYYY-MM-DD.md` — raw logs of what happened
- **Long-term:** `MEMORY.md` — your curated memories, like a human's long-term memory
日誌是原始記錄,MEMORY.md 是精煉過的長期記憶。這個設計很像人類的工作記憶和長期記憶區分。
關鍵的安全設計: MEMORY.md 只在主會話載入,群組聊天(Discord、WhatsApp)不載入。原因是:
1
This is for **security** — contains personal context that shouldn't leak to strangers
這是一個刻意的權衡:在群組中犧牲一點記憶連續性,換取隱私保護。
與 Claude Code 的差異
Claude Code 的 CLAUDE.md 是一次性注入到 System Prompt,之後不會重複讀取。
OpenClaw 的設計是每次都「重新認識自己」——而且是主動調用工具去讀,不是被動注入。
這是它能維持跨對話記憶的關鍵機制,但也是 Token 粉碎機的第一個來源。

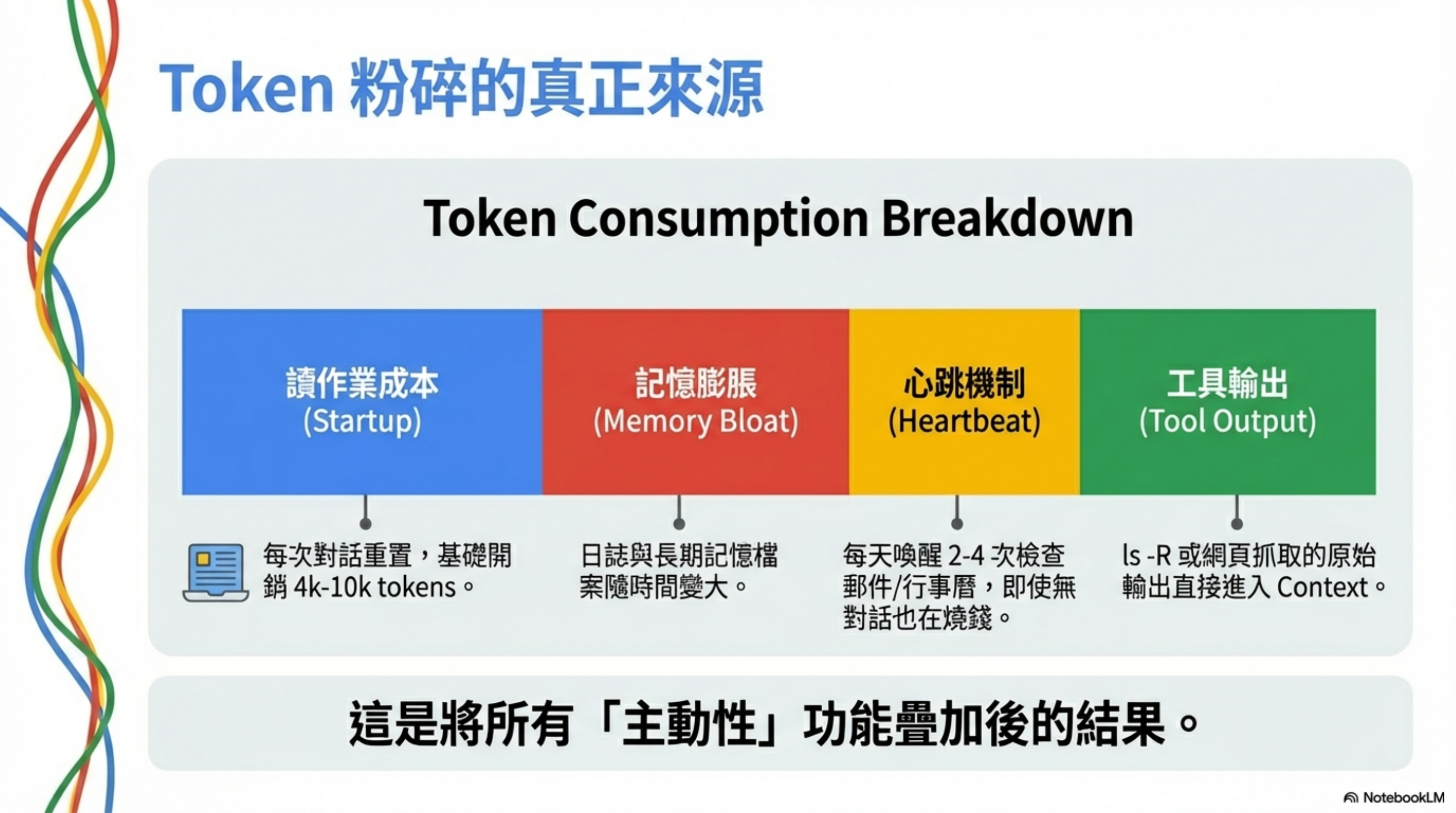
Token 粉碎的真正來源
為什麼社群裡這麼多人抱怨 OpenClaw 燒錢?從架構設計來看,主要消耗來自幾個地方:
1. 每次對話都要「讀作業」
這在前面已經說明:每次新對話啟動,Agent 會主動讀取 SOUL.md、USER.md、memory/*.md 等檔案。
這不是一次性成本,而是每次新對話都要重來。
2. 記憶文件會持續膨脹
memory/YYYY-MM-DD.md 是每日日誌,MEMORY.md 是長期記憶。隨著使用時間增加,這些檔案會越來越大。
AGENTS.md 有提到定期維護的建議,但很少人真的會去整理。結果就是記憶檔案越來越肥,每次讀取成本越來越高。
3. 心跳機制的隱藏成本
AGENTS.md 定義了 Heartbeat 機制——Agent 會定期被喚醒,檢查信箱、行事曆、社群通知等。
1
2
3
4
5
**Things to check (rotate through these, 2-4 times per day):**
- **Emails** - Any urgent unread messages?
- **Calendar** - Upcoming events in next 24-48h?
- **Mentions** - Twitter/social notifications?
- **Weather** - Relevant if your human might go out?
每次心跳喚醒,都要重新載入上下文、調用工具。這是背景消耗,你沒有主動對話,但 Token 還是在燒。
4. 工具輸出沒有限制
當 Agent 執行 ls -R 或抓取網頁時,原始輸出會直接進入上下文。如果輸出很長,Token 消耗會瞬間飆高。
這不是 OpenClaw 特有的問題,但它的「不問就做」設計會放大這個效應——Agent 會更積極地調用工具,自然也會產生更多工具輸出。
為什麼叫「Token 粉碎機」?
不是因為單一功能特別燒錢,而是這些消耗全部疊加在一起:
- 每次對話要讀作業
- 記憶檔案持續膨脹
- 背景心跳定期喚醒
- 工具輸出無上限
加上 OpenClaw 的設計鼓勵 Agent 主動行動、主動記憶、主動檢查——這些「主動」都需要 Token 來驅動。
這是功能換成本的 trade-off,不是設計失誤。
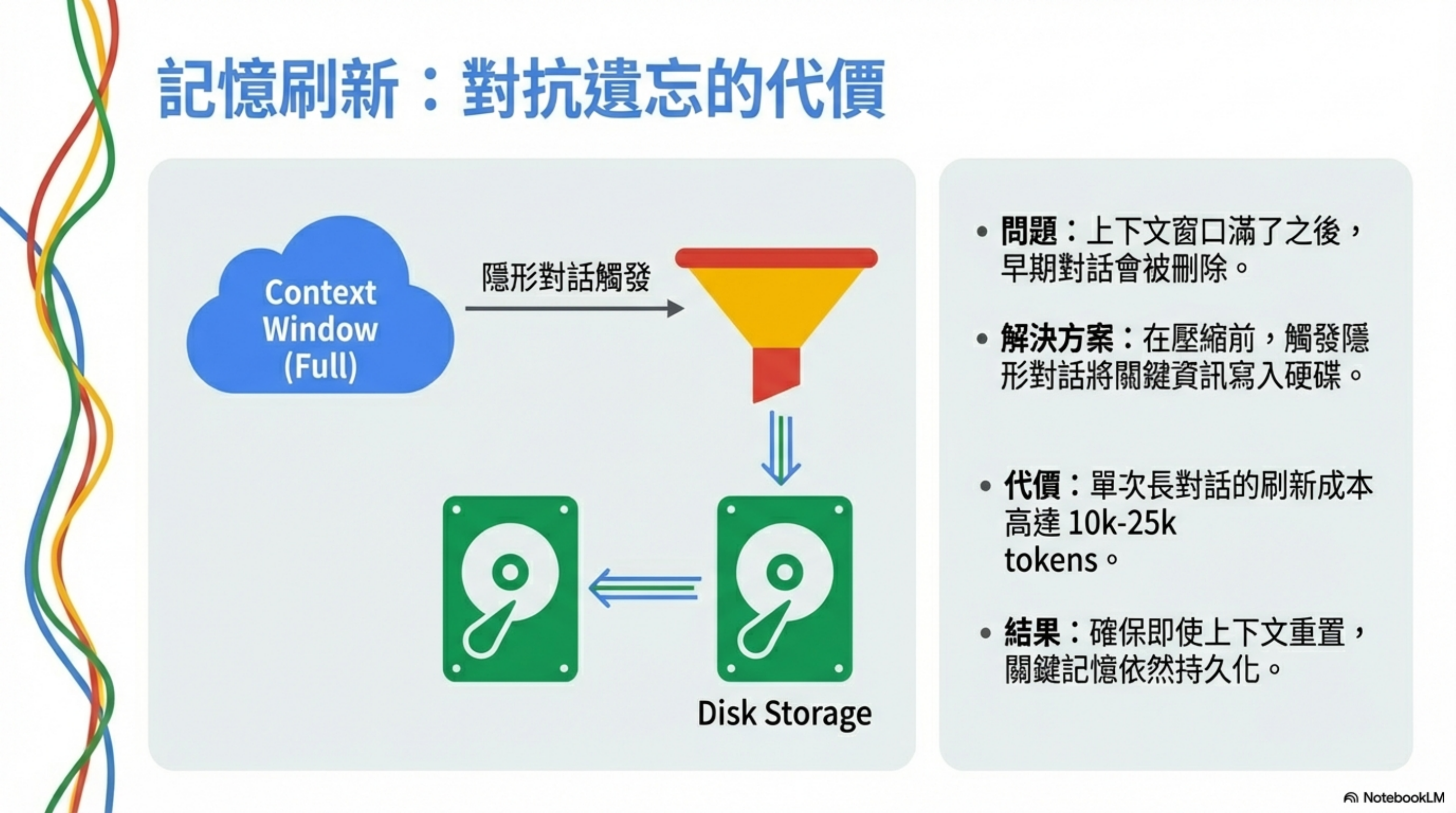
記憶刷新機制:對抗遺忘的代價
OpenClaw 最創新的設計之一是「預壓縮記憶刷新(Memory Flush)」。
問題:上下文窗口有限
當一般 AGENT 逼近上下文上限時,系統必須「壓縮」——通常是刪除早期對話歷史。
這會導致 Agent 忘記 10 分鐘前你交代的事情。
解決方案:在壓縮前先存檔
OpenClaw 的做法是:
- 持續監控 Token 使用量
- 當接近閾值(預設 4,000 tokens 緩衝區)時,觸發隱形對話
- 系統發送 Prompt:「Session nearing compaction. Store durable memories now.」
- Agent 把重要資訊寫入 memory/YYYY-MM-DD.md
- 然後才執行壓縮
這確保了即使原始對話被刪除,關鍵資訊已經持久化到磁碟。
代價
每次記憶刷新:
- 系統提示:~500 tokens
- Agent 思考 + 寫入動作:~2,000-5,000 tokens
- 長對話可能觸發 3-5 次
單次長對話的記憶刷新成本:10,000-25,000 tokens
這是 Claude Code 沒有的成本。Claude Code 不做跨對話記憶,所以不需要這個機制。
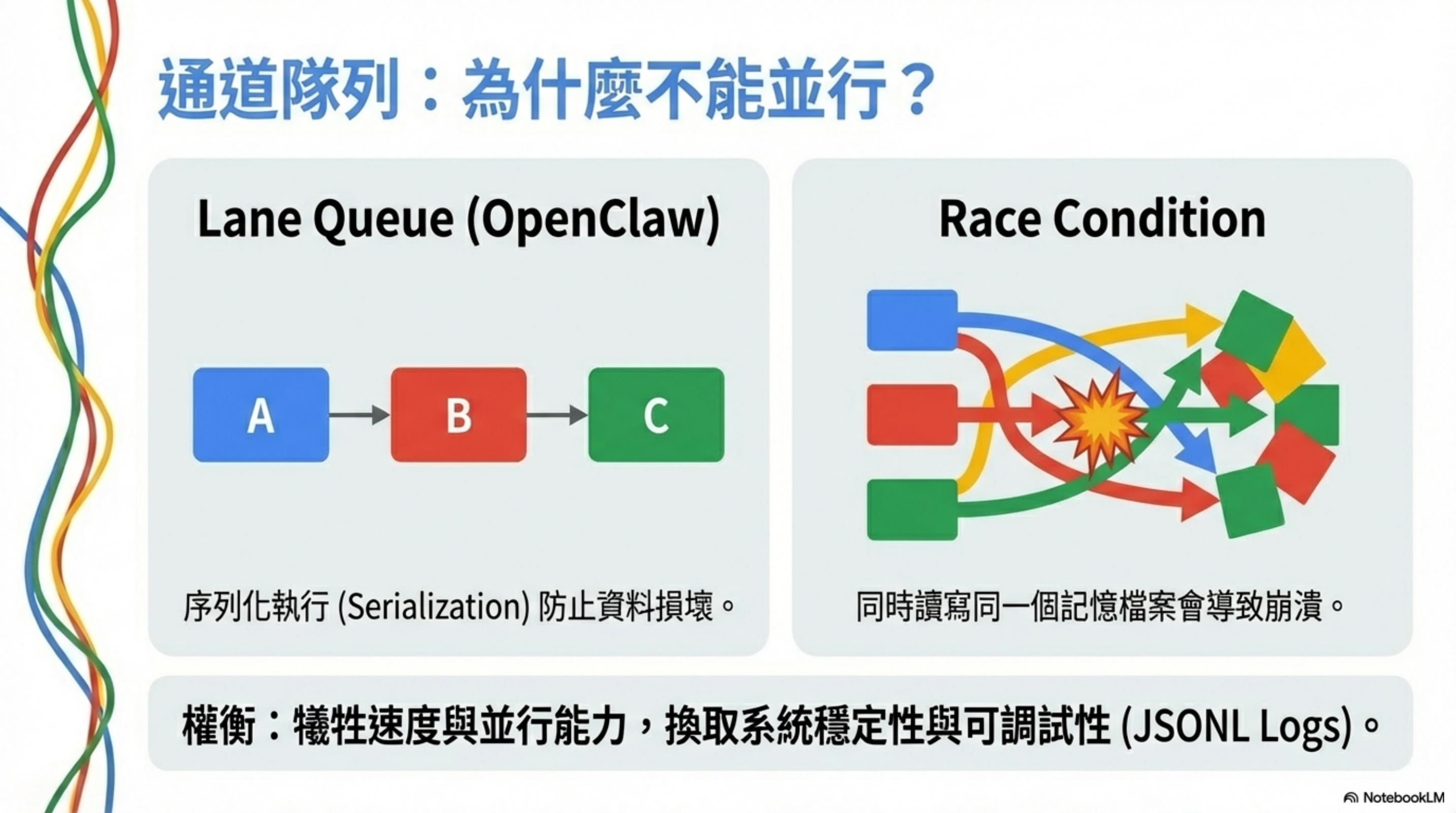
通道隊列:為什麼不能並行?
OpenClaw 採用「通道隊列(Lane Queue)」架構——同一通道內的任務必須嚴格序列執行。
這聽起來很慢,但有它的道理。
問題:Race Condition
如果 Agent 同時嘗試:
- 讀取 memory/2026-02-02.md
- 寫入 memory/2026-02-02.md
結果會是資料損壞。
解決方案:序列化
每個任務必須等前一個完全完成才能開始:
1
Task 1 (讀取) → 完成 → 寫入日誌 → Task 2 (寫入) → 完成 → 寫入日誌 → ...
代價
- 無法利用 LLM API 的並行能力
- 長任務會阻塞後續任務
- 整體執行速度較慢
但換來的是穩定性與可調試性。
所有操作都有 JSONL 記錄,可以精確重現錯誤發生的順序。
安全風險:透明的代價
把記憶存成純文字 Markdown,有兩個主要風險:
1. 無加密 — USER.md 裡的個人偏好、工作專案、生活習慣,主機被入侵就全部裸露。
2. Prompt Injection — Agent 自動讀取 WhatsApp、Discord 訊息,惡意指令可能混在正常訊息裡,誘導 Agent 執行危險操作。
OpenClaw 有做部分防禦(Allowlist、主會話隔離),但不足以應對專業攻擊者。這也是為什麼 我之前的安全加固文章 強調:預設它會被打進來。
坦白說
回到開頭的問題:為什麼 OpenClaw 不用 RAG?
因為 RAG 是用來「查資料」的,但 OpenClaw 需要的是「大腦」。
這個架構選擇決定了一切:
- File-First 設計讓 Agent 有了持久的認知系統
- 每次啟動都要「讀作業」,確保它記得自己是誰
- 記憶雙層架構(Daily notes + MEMORY.md)模擬人類的工作記憶與長期記憶
- 心跳機制讓它能主動關心你的生活
代價是 Token 消耗。但這不是設計失誤——這是為了讓 Agent 像員工一樣「記得你」而選擇接受的成本結構。
所以它不是 Token 粉碎機,而是一個有記憶、有人格、會主動行動的數位大腦。你付的不是 Token 費,是「持續存在」的成本。
常見問題 Q&A
Q: OpenClaw 跟 Claude Code 的 CLAUDE.md 有什麼本質差異?
CLAUDE.md 是「指令集」,一次性注入 System Prompt,之後不會重複讀取。OpenClaw 的 SOUL.md + AGENTS.md + memory/*.md 是「認知系統」——Agent 每次啟動都要主動調用工具去讀取,等於每次都「重新認識自己」。這是它能維持跨對話記憶的關鍵,但也是 Token 消耗的主要來源。
Q: 為什麼 OpenClaw 不用 RAG 來降低成本?
RAG 是用來「查資料」的,適合問答場景。但 OpenClaw 的目標是「自主代理」,需要持續「知道」自己是誰、在做什麼。RAG 的片段式檢索無法提供一致的人格和連貫的上下文,所以 OpenClaw 選擇犧牲效率,用 Full Context 來維持認知連續性。這是哲學選擇,不是技術落後。
Q: 一週燒 $200 美金的 API 費用正常嗎?
看使用強度。如果你開著心跳機制(2-4 次/天)、頻繁對話、記憶檔案沒有定期整理,這個數字是可能的。主要消耗來自:每次對話讀作業(4,000-10,000 tokens)、記憶刷新(10,000-25,000 tokens/長對話)、心跳喚醒(每次都要載入上下文)。想省錢的話,可以關閉心跳、定期整理 memory/*.md、避免長對話。
Q: 記憶檔案膨脹怎麼處理?
AGENTS.md 建議定期維護,但很少人真的做。我的建議是:每週檢查 memory/*.md 的大小,超過 5KB 就考慮整理;把重要資訊轉移到 MEMORY.md(精煉版),日誌只保留最近 7 天。這樣可以把每次讀取成本控制在 5,000 tokens 以內。
Q: OpenClaw 的安全風險怎麼緩解?
兩個主要風險:純文字記憶無加密(主機被入侵就全裸)、Prompt Injection(惡意訊息混在群組裡)。緩解方式:不要把敏感資訊寫進 USER.md;限制 WhatsApp/Discord 的 Allowlist;用獨立虛擬機跑 OpenClaw;定期檢查 memory/*.md 是否有異常內容。詳細做法可以參考我的安全加固文章。
Q: 這套架構適合企業使用嗎?
坦白說,目前不太適合。原因:成本不可預測(Token 消耗跟使用模式高度相關)、安全風險高(純文字記憶、Prompt Injection)、缺乏審計追蹤(雖然有 JSONL 日誌,但不是企業級)。如果企業想要類似功能,建議用 Claude Code + 自建記憶層,或等 OpenClaw 的企業版(如果有的話)。
延伸閱讀
- 從 $1.16 億退休到 Agentic Engineering:Peter Steinberger 與 OpenClaw 的傳奇開發哲學 —— OpenClaw 背後的人與哲學
- 從「套殼 1.0」到「套殼 2.0」:為什麼真正該緊張的是 Anthropic —— 套殼 2.0 生態的完整分析
- OpenClaw 四層縱深防禦加固指南 —— 如果你要跑 OpenClaw,這篇必讀
- OneFlow:Single Agent vs Multi-Agent 重新思考 —— 為什麼 Context Management 比堆 Agent 更重要
- 個人 AI 助手決戰週:Claude Code vs OpenClaw 殊途同歸 —— 兩條路線的比較分析
關於作者:
Wisely Chen,NeuroBrain Dynamics Inc. 研發長,20+ 年 IT 產業經驗。曾任 Google 雲端顧問、永聯物流 VP of Data & AI、艾立運能數據長。專注於傳統產業 AI 轉型與 Agent 導入的實戰經驗分享。
相關連結:
- 部落格首頁:https://ai-coding.wiselychen.com
- LinkedIn:https://www.linkedin.com/in/wisely-chen-38033a5b/