OpenClaw Token 優化指南:如何將 AI Agent 運營成本降低 97%

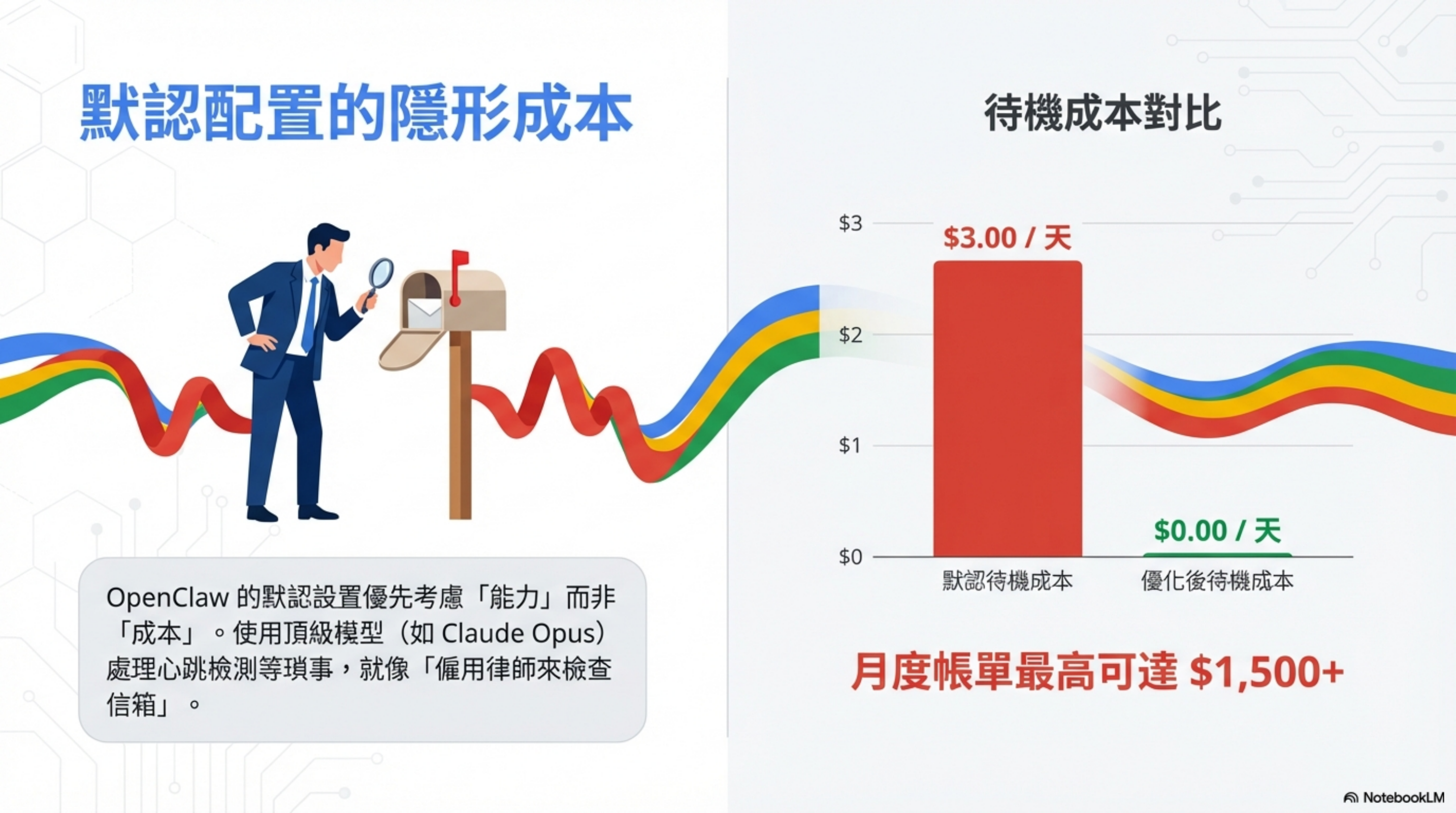
問題:默認配置的隱形成本
上週有讀者私訊我:
「我的 OpenClaw 跑了一週,API 帳單 $200 美金,但我其實沒怎麼用它。」
這不是個案。
在 我之前的架構分析文章 裡,我解釋了 OpenClaw 為什麼被叫做「Token 粉碎機」。但那篇是講「為什麼貴」,這篇要講「怎麼省」。
我根據網路上數篇文章的建議進行測試,發現預設配置下的 OpenClaw 為了追求能力(Capability),會把所有任務——包含最簡單的「你在嗎?」心跳檢測——都交給昂貴的旗艦模型(Claude Opus)處理。
主要參考資料:
- Matt Ganzak 的成本優化實戰分享(OpenClaw 重度使用者)
- VelvetShark 的詳細配置指南(開發者)
這就像「僱用律師來檢查信箱」。財務上完全不合理。
根據網路實測 降幅:97%,我這邊實測前兩個很容易降低 50%以上。
五大核心優化策略
根據我的實測,OpenClaw 成本優化可以歸納為五大核心策略:
| # | 策略 | 核心效果 |
|---|---|---|
| 1 | 會話初始化 | 消除上下文膨脹 |
| 2 | 模型路由 | 智能任務分層 |
| 3 | 本地心跳 | Ollama 零成本監控 |
| 4 | 提示詞快取 | 靜態內容 90% 折扣 |
| 5 | 速率限制 | 防止預算失控 |
接下來逐一拆解。
策略一:會話初始化——消除上下文膨脹
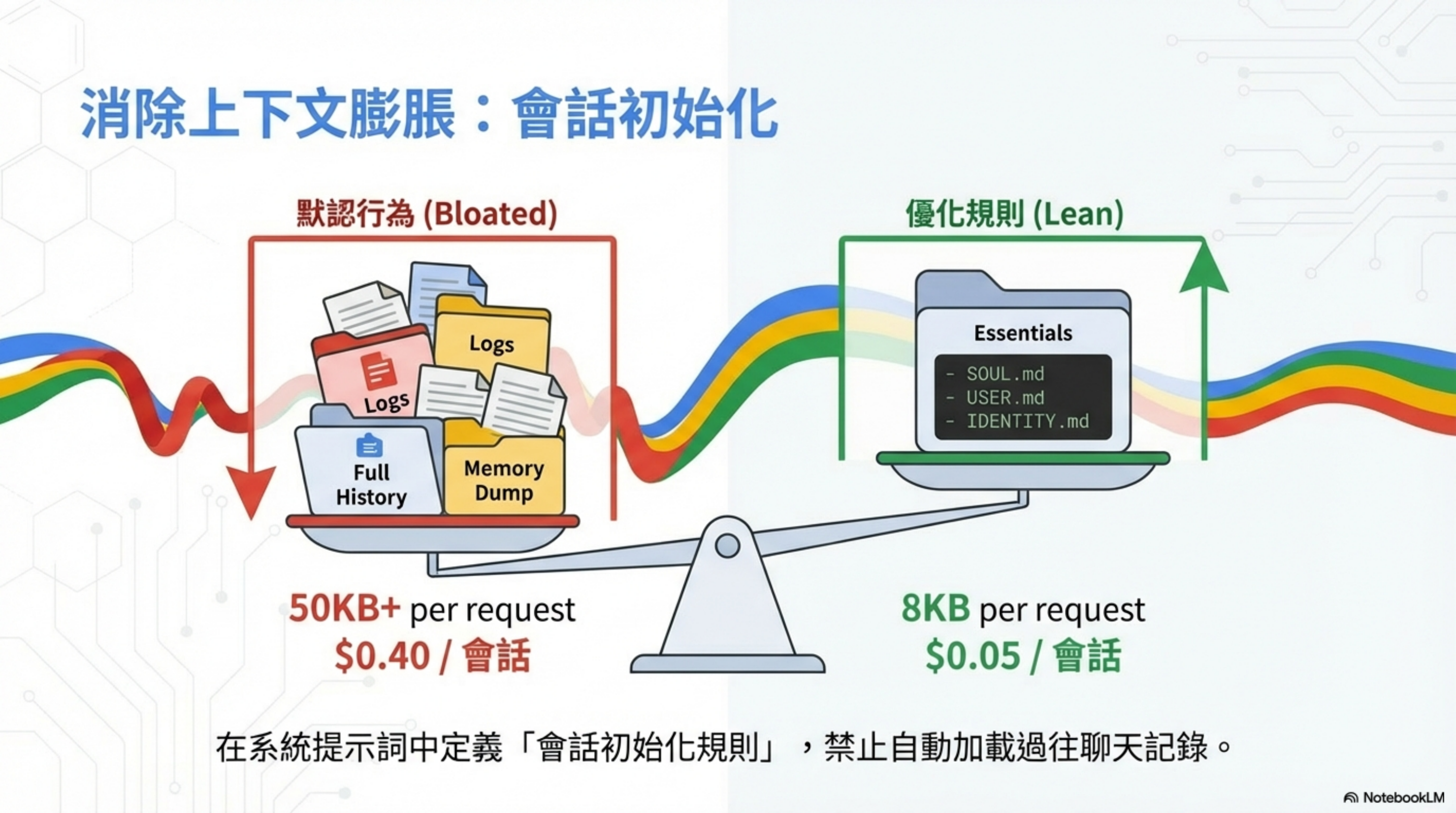
這是隱藏最深的成本殺手。
OpenClaw 預設會在每次對話時重新上傳整個歷史紀錄(Slack、WhatsApp、Telegram 的所有對話),導致每次請求都消耗大量 Token。
默認行為 vs 優化規則
| 配置 | Context 大小 | 每次會話成本 |
|---|---|---|
| 默認行為(Bloated) | 50KB+ | $0.40 |
| 優化規則(Lean) | 8KB | $0.05 |
省下 87%。
默認行為載入什麼?
- Full History(完整對話歷史)
- Logs(所有日誌)
- Memory Dump(記憶傾印)
優化後只載入 Essentials
SOUL.mdUSER.mdIDENTITY.md
實作方式
在系統提示詞中定義「會話初始化規則」,禁止自動加載過往聊天記錄。
在 SOUL.md 加入:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
## Session Management
When I say "new session":
1. Clear all conversation history from context
2. Store important information in memory/YYYY-MM-DD.md
3. Start fresh with only core files (SOUL.md, USER.md)
## Startup Rules
At session start, ONLY load:
1. SOUL.md
2. USER.md
3. memory/today.md (if exists)
Do NOT auto-load:
- Full conversation history
- All channel messages
- Historical memory files older than 2 days
策略二:智能模型分層與路由

不要讓同一個模型做所有事情。你需要根據任務難度,指派不同等級的「員工」。
三層模型架構
| Tier | 名稱 | 模型 | 任務類型 | 成本比例 |
|---|---|---|---|---|
| Tier 1 | 高智力(High Intelligence) | Claude Opus / GPT-5.2 | 架構決策、複雜代碼重構、安全分析 | 100%(基準) |
| Tier 2 | 日常工作(Routine Work) | Claude Haiku / DeepSeek V3 | 代碼生成、資料研究、初稿撰寫 | 成本降低 10-50 倍 |
| Tier 3 | 基礎任務(Brainless Tasks) | Gemini Flash / Local LLM | 分類、心跳檢測、簡單查詢 | 0-1% |
核心原則
模型路由機制根據任務複雜度自動選擇最適合的 AI 模型,實現成本與效率的完美平衡。
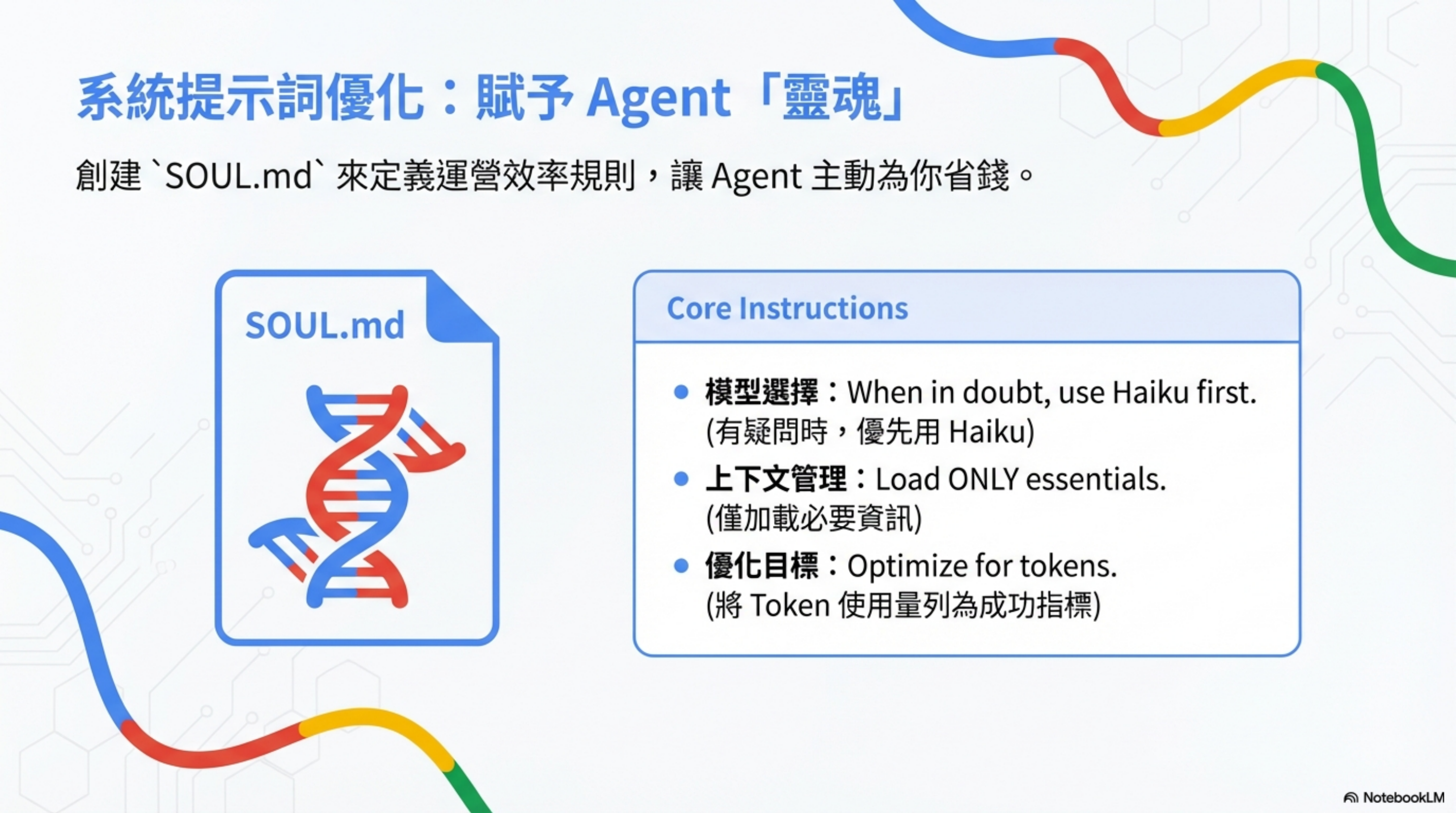
在 SOUL.md 加入路由規則
1
2
3
4
5
6
7
8
9
10
## Model Selection
模型選擇:When in doubt, use Haiku first.
(有疑問時,優先用 Haiku)
上下文管理:Load ONLY essentials.
(僅加載必要資訊)
優化目標:Optimize for tokens.
(將 Token 使用量列為成功指標)
策略三:本地心跳檢測——零成本監控
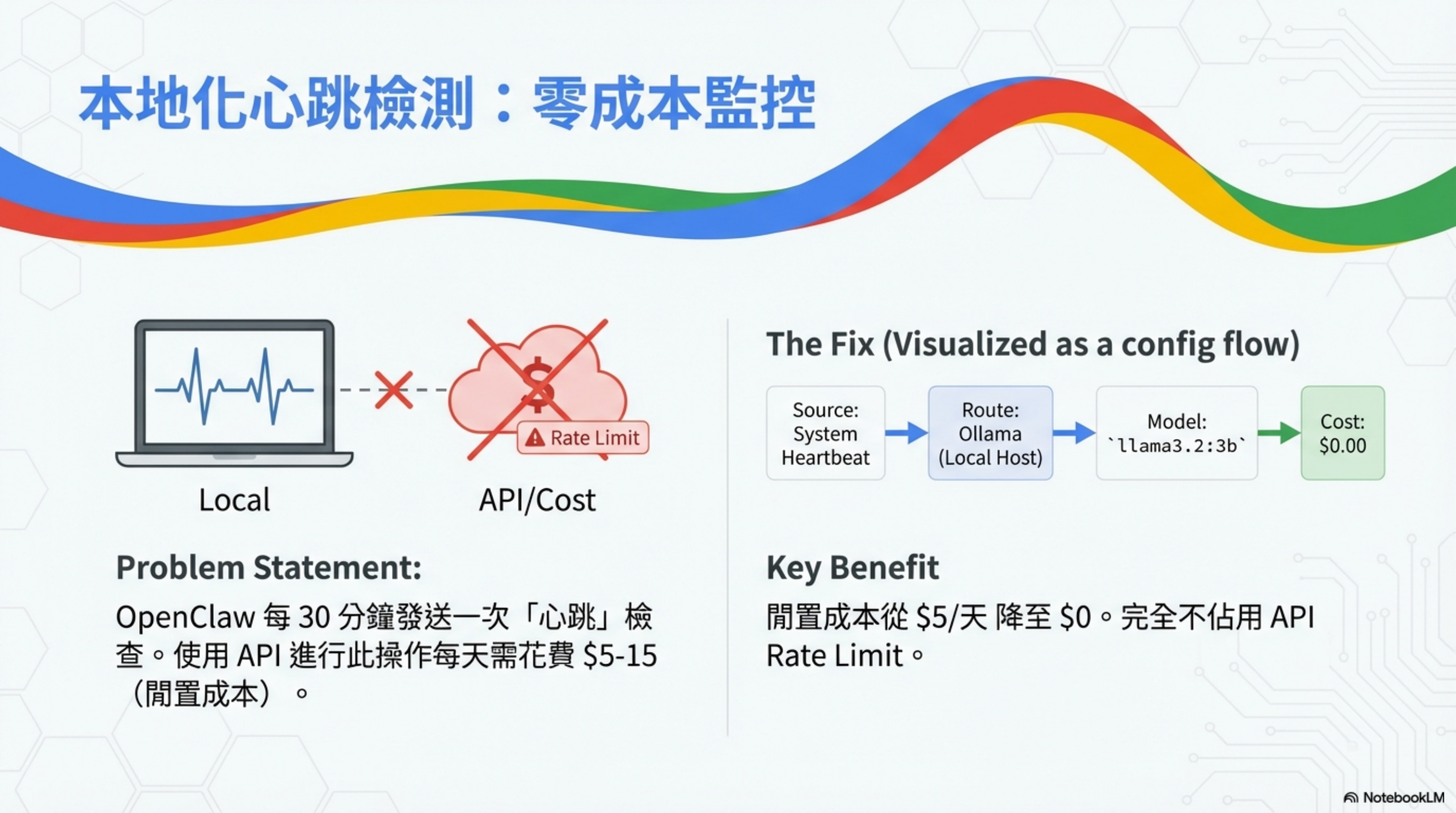
OpenClaw 預設每 30 分鐘執行一次「Heartbeat」檢查。這不只是單純的「系統是否存活」確認,而是一套完整的背景監控機制。
Heartbeat 會做什麼?
- 檢查未讀 Email(有沒有緊急信件?)
- 掃描行事曆(未來 24-48 小時有什麼行程?)
- 監控社群通知(Twitter/Telegram 有沒有人 @ 你?)
- 查詢天氣(如果你可能要出門)
- 確認系統狀態與連線
問題陳述
使用 API 進行心跳操作,每天需花費 $5-15(閒置成本)。
解決方案:本地化
把心跳檢測路由到本地 Ollama,成本從 $5/天降至 $0。完全不佔用 API Rate Limit。
配置流程
1
System Heartbeat → Route: Ollama (Local Host) → Model: llama3.2:3b → Cost: $0.00
實作步驟
- 安裝 Ollama
- 下載輕量模型:
ollama pull llama3.2:3b - 修改配置(見下方 openclaw.json)
方案 B:雲端低價模型
如果你不想維護本地 Ollama,可以用極低價的商業模型:
- Gemini Flash-Lite:$0.50/百萬 tokens
- DeepSeek V3.2:$0.27/百萬 tokens
每月成本約 $0.50-1.00,換取 24/7 穩定性。
策略四:提示詞快取——靜態內容 90% 折扣
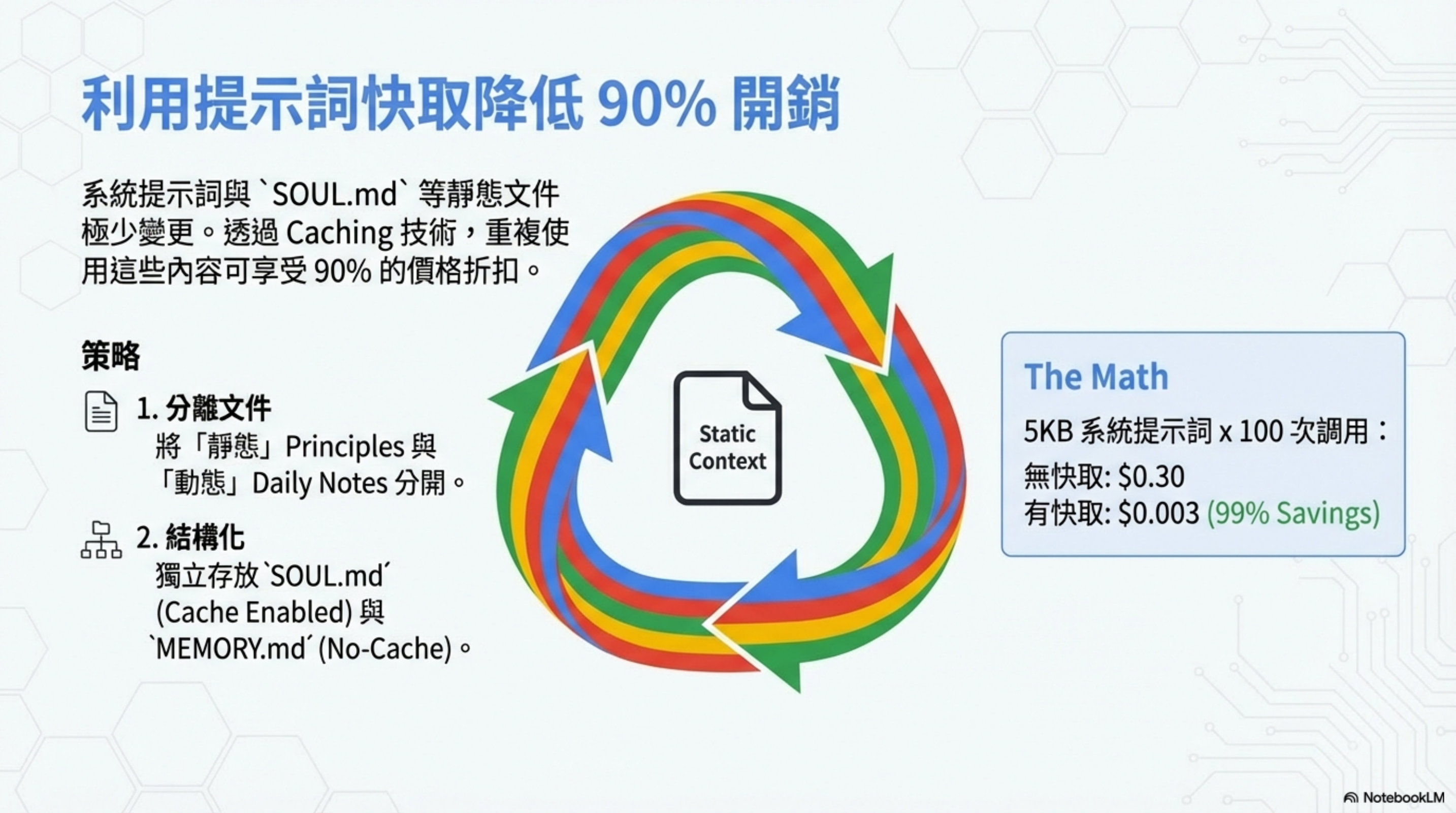
系統提示詞與 SOUL.md 等靜態文件極少變更。透過 Caching 技術,重複使用這些內容可享受 90% 的價格折扣。
OpenClaw 會在可用時自動啟用提示詞快取。要最大化快取命中率,關鍵是將靜態內容保存在專用文件中。
Step 1:識別什麼該快取
| ✓ 應該快取 | ❌ 不要快取 |
|---|---|
| 系統提示詞(很少變動) | 每日記憶文件(頻繁變動) |
| SOUL.md(操作原則) | 最近的用戶訊息(每次會話刷新) |
| USER.md(目標與上下文) | 工具輸出(每次任務變動) |
| 參考資料(定價、文檔、規格) | |
| 工具說明文檔(很少更新) | |
| 專案模板(標準結構) |
Step 2:結構化以利快取
1
2
3
4
5
6
7
8
9
/workspace/
├── SOUL.md ← 快取這個(穩定)
├── USER.md ← 快取這個(穩定)
├── TOOLS.md ← 快取這個(穩定)
├── memory/
│ ├── MEMORY.md ← 不要快取(頻繁更新)
│ └── 2026-02-03.md ← 不要快取(每日筆記)
└── projects/
└── [PROJECT]/REFERENCE.md ← 快取這個(穩定文檔)
Step 3:在配置中啟用快取
更新 ~/.openclaw/openclaw-config.json 以啟用提示詞快取:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-haiku-4-5"
},
"cache": {
"enabled": true,
"ttl": "5m",
"priority": "high"
}
},
"models": {
"anthropic/claude-sonnet-4-5": {
"alias": "sonnet",
"cache": true
},
"anthropic/claude-haiku-4-5": {
"alias": "haiku",
"cache": false
}
}
}
}
Note: 快取對 Sonnet 最有效(更適合需要較大提示詞的推理任務)。Haiku 本身效率就很高,快取效益較小。
配置選項說明:
| 選項 | 說明 |
|---|---|
cache.enabled |
true/false — 全局啟用提示詞快取 |
cache.ttl |
存活時間:「5m」(預設)、「30m」(較長會話)、「24h」 |
cache.priority |
「high」(優先快取)、「low」(平衡成本/速度) |
models.cache |
每個模型的 true/false — 建議 Sonnet 啟用,Haiku 可選 |
Step 4:快取命中策略
為了最大化快取效率:
1. 在 5 分鐘視窗內批次請求
- 快速連續發送多個 API 調用
- 減少請求之間的快取未命中
2. 保持系統提示詞穩定
- 不要在會話中途更新 SOUL.md
- 變更會使快取失效;將它們批次到維護時段
3. 分層組織上下文
- 核心系統提示詞(最高優先級)
- 穩定的工作區文件
- 動態每日筆記(不快取)
4. 專案:分離穩定與動態內容
product-reference.md(穩定,快取)project-notes.md(動態,不快取)- 防止筆記更新導致快取失效
真實案例:外展郵件撰寫
假設你每週使用 Sonnet 撰寫 50 封外展郵件(需要推理 + 個性化):
| 無快取 | 有快取(批次處理) |
|---|---|
| 系統提示詞:5KB × 50 = 250KB/週 | 系統提示詞:1 次寫入 + 49 次快取 |
| 成本:$0.75/週 | 成本:$0.016/週 |
| 50 封郵件 × 8KB = $1.20/週 | 50 封郵件(約 50% 快取命中)= $0.60/週 |
| 總計:$1.95/週 = $102/月 | 總計:$0.62/週 = $32/月 |
| 節省:$70/月 |
優化前後對比
| ❌ 優化前 | ✓ 優化後 |
|---|---|
| 系統提示詞每次請求都發送 | 系統提示詞快取後重複使用 |
| 成本:5KB × 100 調用 = $0.30 | 成本:5KB × 100 調用 = $0.003 |
| 無快取策略 | 在 5 分鐘視窗內批次處理 |
| 隨機快取未命中 | 靜態內容 90% 命中率 |
| 每月重複內容成本:$100+ | 每月重複內容成本:$10 |
| 單一專案:$50-100/月 | 單一專案:$5-15/月 |
| 多專案:$300-500/月 | 多專案:$30-75/月 |
Step 5:監控快取效能
使用 session_status 檢查快取效果:
1
2
3
4
5
6
7
openclaw shell
session_status
# 查看快取指標:
# Cache hits: 45/50 (90%)
# Cache tokens used: 225KB (vs 250KB without cache)
# Cost savings: $0.22 this session
或直接查詢 API:
1
2
3
# 檢查過去 24 小時的使用量
curl https://api.anthropic.com/v1/usage \
-H "Authorization: Bearer $ANTHROPIC_API_KEY" | jq '.usage.cache'
應追蹤的指標:
| 指標 | 含義 |
|---|---|
| 快取命中率 > 80% | 快取策略運作良好 |
| 快取 tokens < 輸入的 30% | 系統提示詞太大(需精簡) |
| 快取寫入持續增加 | 系統提示詞變動太頻繁(需穩定) |
| 會話成本比上週 -50% | 快取 + 模型路由的綜合效果 |
與其他優化的疊加效果
快取會放大先前優化的效益:
| 優化項目 | 優化前 | 優化後 | 加上快取 |
|---|---|---|---|
| 會話初始化(精簡上下文) | $0.40 | $0.05 | $0.005 |
| 模型路由(Haiku 為預設) | $0.05 | $0.02 | $0.002 |
| 心跳改用 Ollama | $0.02 | $0 | $0 |
| 速率限制(批次處理) | $0 | $0 | $0 |
| 提示詞快取 | $0 | $0 | -$0.015 |
| 綜合總計 | $0.47 | $0.07 | $0.012 |
什麼時候不要使用快取
- Haiku 任務(太便宜不值得快取):快取開銷 > 節省金額
- 頻繁更改提示詞:快取失效成本超過快取收益
- 小請求(< 1KB):快取開銷吃掉折扣
- 開發/測試階段:提示詞迭代太多;快取頻繁失效
策略五:預算控制與速率限制

防止「失控自動化」在一夜之間燒光預算。
四大護欄
| 護欄 | 設定 |
|---|---|
| API 間隔 | 每次調用至少間隔 5 秒 |
| 搜索限制 | 每次搜索間隔 10 秒,每批次最多 5 次 |
| 錯誤處理 | 遇到 429 錯誤時,強制停止並等待 5 分鐘 |
| 預算上限 | 設置每日預算 $5(達 75% 時警告) |
在 SOUL.md 加入
1
2
3
4
5
6
7
8
9
10
11
12
13
## Rate Limits
ALWAYS follow these limits:
- API calls: minimum 5 seconds between calls
- Web searches: maximum 5 per batch, 10 seconds between each
- If you hit 429 error, STOP and wait 5 minutes
- If you hit rate limit, STOP and report to user
## Budget Awareness
- Daily budget: $5
- Warning at 75% ($3.75)
- Hard stop at 100%
配置 openclaw.json
1
2
3
4
5
6
7
8
{
"budget": {
"daily_limit_usd": 5,
"monthly_limit_usd": 100,
"warning_threshold": 0.75,
"action_on_limit": "pause_and_notify"
}
}
關鍵配置:openclaw.json

編輯 ~/.openclaw/openclaw.json 以啟用多模型路由:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
{
"defaults": {
"primary": "anthropic/claude-haiku-4-5"
},
"heartbeat": {
"provider": "ollama",
"model": "llama3.2:3b",
"every": "1h"
},
"model_routing": {
"default": "claude-haiku-4-5",
"complex_reasoning": "claude-opus-4",
"code_generation": "deepseek-r1",
"simple_tasks": "gemini-2.0-flash"
},
"prompt_caching": {
"enabled": true,
"cached_files": ["SOUL.md", "USER.md", "IDENTITY.md"]
},
"budget": {
"daily_limit_usd": 5,
"monthly_limit_usd": 100,
"warning_threshold": 0.75
}
}
關鍵改動:
- 將默認模型設為 Haiku(而非 Opus)
- 將心跳指向本地 Ollama
真實案例:不同用戶類型的成本節省
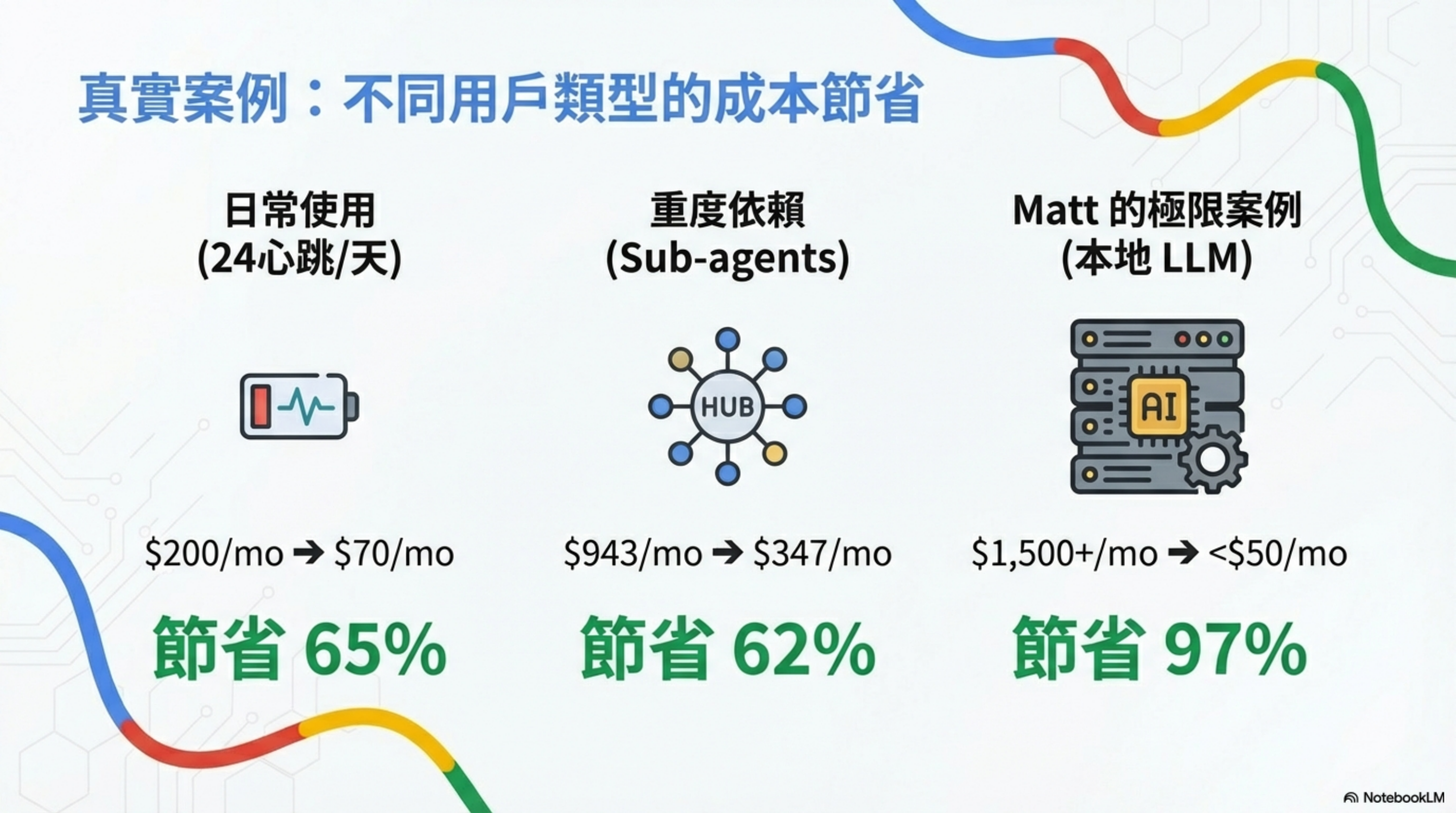
| 用戶類型 | 使用模式 | 優化前 | 優化後 | 節省 |
|---|---|---|---|---|
| 日常使用 | 24 心跳/天 | $200/月 | $70/月 | 65% |
| 重度依賴 | Sub-agents 密集調用 | $943/月 | $347/月 | 62% |
| Matt 的極限案例 | 本地 LLM 全面部署 | $1,500+/月 | <$50/月 | 97% |
驗證與監控:確保優化生效

使用終端機命令 session_status 進行檢查:
1
2
3
4
✅ Context Size: 2-8KB (目標達成)
✅ Heartbeat: Ollama/Local (非 API)
✅ Default Model: Haiku
✅ Cache Hit Rate: > 80%
若成本未下降,請檢查 openclaw.json 與系統提示詞是否被正確重新加載。
優化行動清單
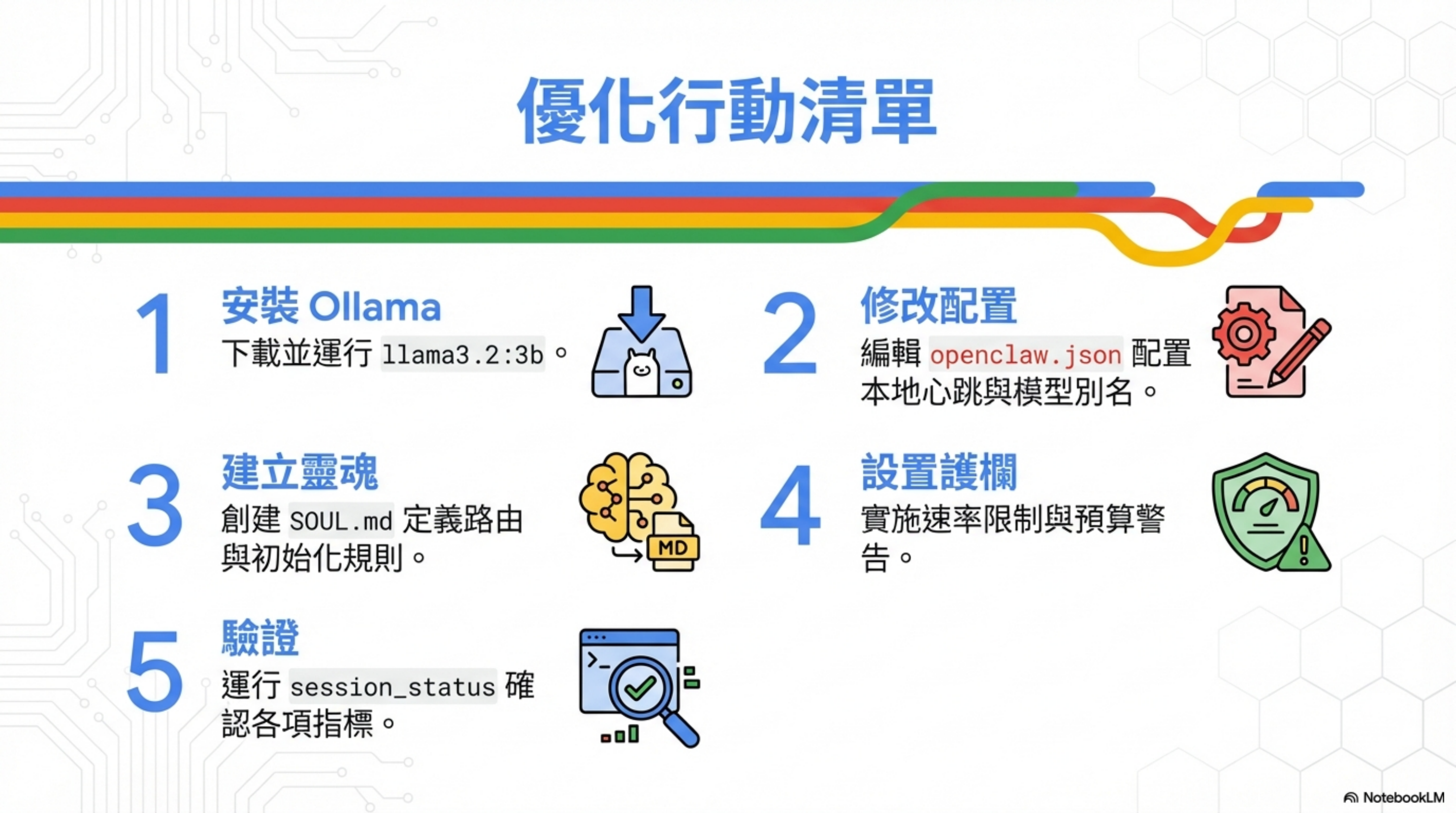
| 步驟 | 行動 | 說明 |
|---|---|---|
| 1 | 安裝 Ollama | 下載並運行 llama3.2:3b |
| 2 | 修改配置 | 編輯 openclaw.json 配置本地心跳與模型別名 |
| 3 | 建立靈魂 | 創建 SOUL.md 定義路由與初始化規則 |
| 4 | 設置護欄 | 實施速率限制與預算警告 |
| 5 | 驗證 | 運行 session_status 確認各項指標 |
坦白說
這篇文章綜合了 Matt Ganzak 和 VelvetShark 的優化經驗,加上我自己的實測。
但我要坦白幾件事:
1. 不是所有優化都沒有代價
用便宜模型做心跳,偶爾會有「反應慢」的情況。Gemini Flash-Lite 的首次回應時間比 Opus 慢 200-500ms。
如果你的場景對延遲很敏感(比如即時交易),這個 trade-off 可能不划算。
2. Context 清除會損失連續性
設定「new session」指令雖然省錢,但也會讓 Agent「忘記」你剛才在聊什麼。
我的做法是:只在跨主題時才說「new session」,同一個主題的對話保持連續。
3. 模型路由需要調整
預設的路由規則不一定適合你的使用場景。我花了大概兩天在調整「什麼任務用什麼模型」的邊界。
比如我發現,寫 Python 腳本用 DeepSeek R1 就夠了,但寫複雜的 Bash 腳本還是需要 Sonnet。
4. 這些優化不是一勞永逸
OpenClaw 會更新,Anthropic 的定價會變,新模型會出現。
我大概每個月會重新檢視一次配置,看看有沒有更好的選擇。
常見問題 Q&A
Q: 優化後 OpenClaw 的能力會下降嗎?
看你怎麼定義「能力」。如果是指「最困難任務的處理能力」,不會——因為複雜任務還是用 Opus。如果是指「所有任務的回應速度」,會稍微慢一點——因為便宜模型的延遲比較高。我的實測是:日常使用感受不到明顯差異,但確實有些邊緣情況需要手動切換模型。
Q: 本地跑 Ollama 和用 Gemini Flash-Lite,哪個更推薦?
看你的環境。如果你有閒置的本地機器(Mac Mini、舊電腦),用 Ollama 可以做到 $0 成本。如果你是用雲端 VM,或者不想維護本地服務,用 Gemini Flash-Lite 更省心。我個人用 Gemini,因為每月 $1 的穩定性比省下這 $1 更值得。
Q: 上下文膨脹的問題,用 RAG 不是更好嗎?
這涉及到 OpenClaw 的設計哲學。RAG 適合「查資料」,但 OpenClaw 需要的是「持續的認知狀態」。用 RAG 會破壞它的記憶連續性和人格一致性。詳細討論可以看 我的架構分析文章。
Q: 護欄設太緊會不會影響 Agent 的自主性?
會。這是一個 trade-off。我的原則是:寧可讓 Agent 偶爾被擋下來,也不要半夜收到 $500 的帳單。你可以根據自己的風險承受度調整限制。
Q: 這些優化適用於 Claude Code 嗎?
部分適用。模型路由和預算監控的概念可以用,但 Claude Code 沒有心跳機制,也沒有 OpenClaw 那種「每次都要讀作業」的設計,所以上下文膨脹的問題比較輕。Claude Code 的主要成本來源是長對話和大量工具調用,優化方向不太一樣。
延伸閱讀
- OpenClaw 記憶系統全解析:SOUL.md、AGENTS.md 與高昂的 Token 成本 —— 理解成本來源
- 這幾天我密集使用小龍蝦 OpenClaw:為什麼我決定把它納入工作流 —— 實際使用場景
- OpenClaw 四層縱深防禦加固指南 —— 安全必讀
- 從 $1.16 億退休到 Agentic Engineering:Peter Steinberger 與 OpenClaw 的傳奇開發哲學 —— OpenClaw 背後的人與哲學
資源與工具

| 資源 | 說明 |
|---|---|
| Cost Calculator | calculator.vlvt.sh |
| Local LLM | ollama.ai(Download Llama 3.2) |
| Config Templates | 查看 ~/.openclaw/ 範例文件 |
Follow for more: @mattganzak
參考資料: