OpenClaw 如何部署在企業:我怎麼把 AI Agent 當成一個「全新的員工」

一開始我不敢把 OpenClaw 放在公司網路上
老實說,看著這麼強的工具,怎麼可能不手癢?
但公司網路裡有客戶資料、內部文件、各種敏感資訊。讓一個 AI Agent 直接存取?資安部門會先把我釘在牆上。
後來我換了一個想法:
把 OpenClaw 當成剛入職的新員工。
這樣一想,很多設計突然就合理了。
新人到職:先開帳號
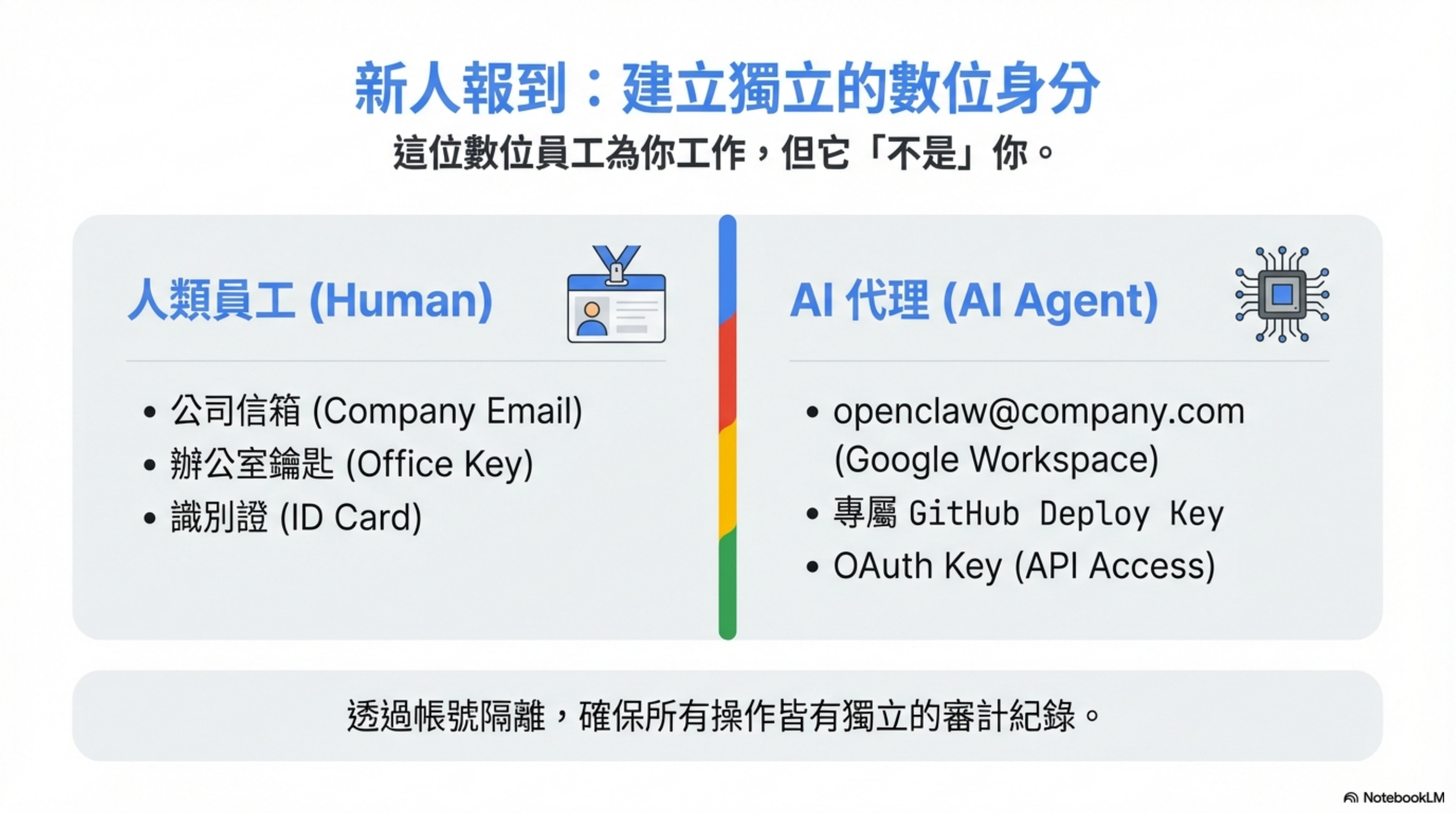
HR 幫新人開的第一件事是什麼?公司信箱。
我替 OpenClaw 做了一樣的事:
| 項目 | 說明 |
|---|---|
| 員工帳號 | Google Workspace 帳號(openclaw@company.com) |
| 專屬 GitHub Key | 獨立的 Deploy Key,不是我個人的 |
| OAuth Key | Google Workspace API 存取金鑰 |
這個帳號就像新人的公司信箱——它能工作,但它不是我。
權限設計:像管新人一樣管 AI
1. Google Workspace:要用就要申請

新人想看某份文件?主管要先 share 給他。
OpenClaw 也一樣。
我如果想請它處理文件,要做的就是 share permission 給這個員工帳號。它根據權限下載、處理、產出結果。
要發會議邀請?它會記住要發給誰,然後用它自己的帳號發。
不是用我的帳號,是用它的。
2. 內部系統:用 Code 層防呆,不靠提示詞

公司內部系統的連接,我用寫好的 Skill 處理。
重點是:在 Skill 的 Code 裡面放入禁止動作的邏輯。
1
2
3
4
5
6
7
8
# 在 code 層級禁止危險操作
FORBIDDEN_ACTIONS = ['DELETE', 'DROP', 'TRUNCATE']
def execute_query(query):
for action in FORBIDDEN_ACTIONS:
if action in query.upper():
raise SecurityError(f"禁止執行 {action} 操作")
# ... 執行查詢
這是 Code 層級的防護,不是提示詞層級。
為什麼?因為 Prompt Injection 可以繞過提示詞,但繞不過程式碼邏輯。
3. 模型選擇:選 Gemini Pro,不是因為能力
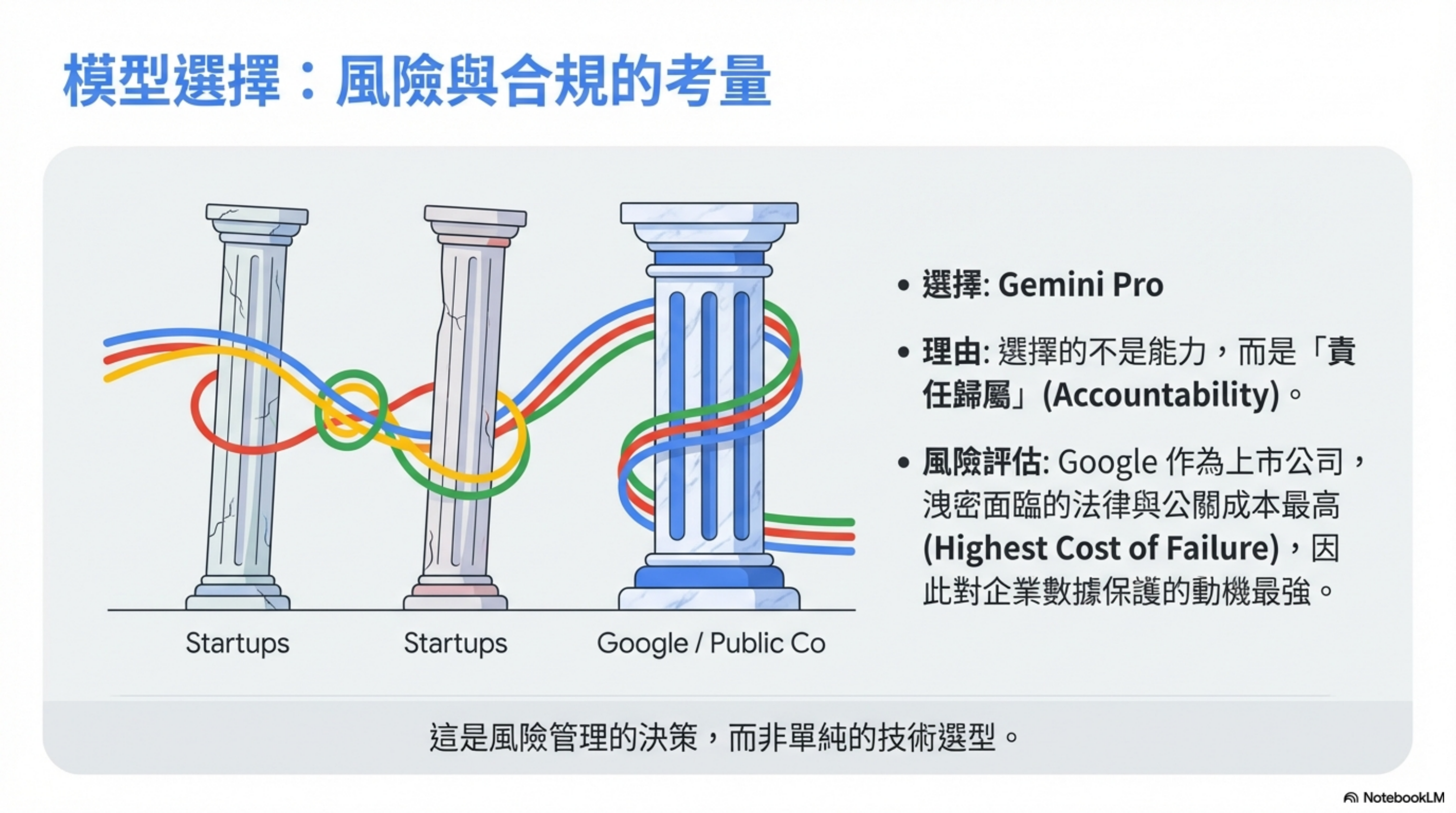
模型能力?三家都夠用。
我選 Gemini Pro 的原因是:Google 洩密的代價最高。
御三家裡面:
- OpenAI 和 Anthropic 本質上還是 startup
- Google 是上市公司,合規要求是另一個等級
真的出事,Google 的法務和公關成本最高,所以他們會最認真保護客戶資料。
這是風險管理,不是技術選型。
4. 絕對不開 Dashboard 或 SSH
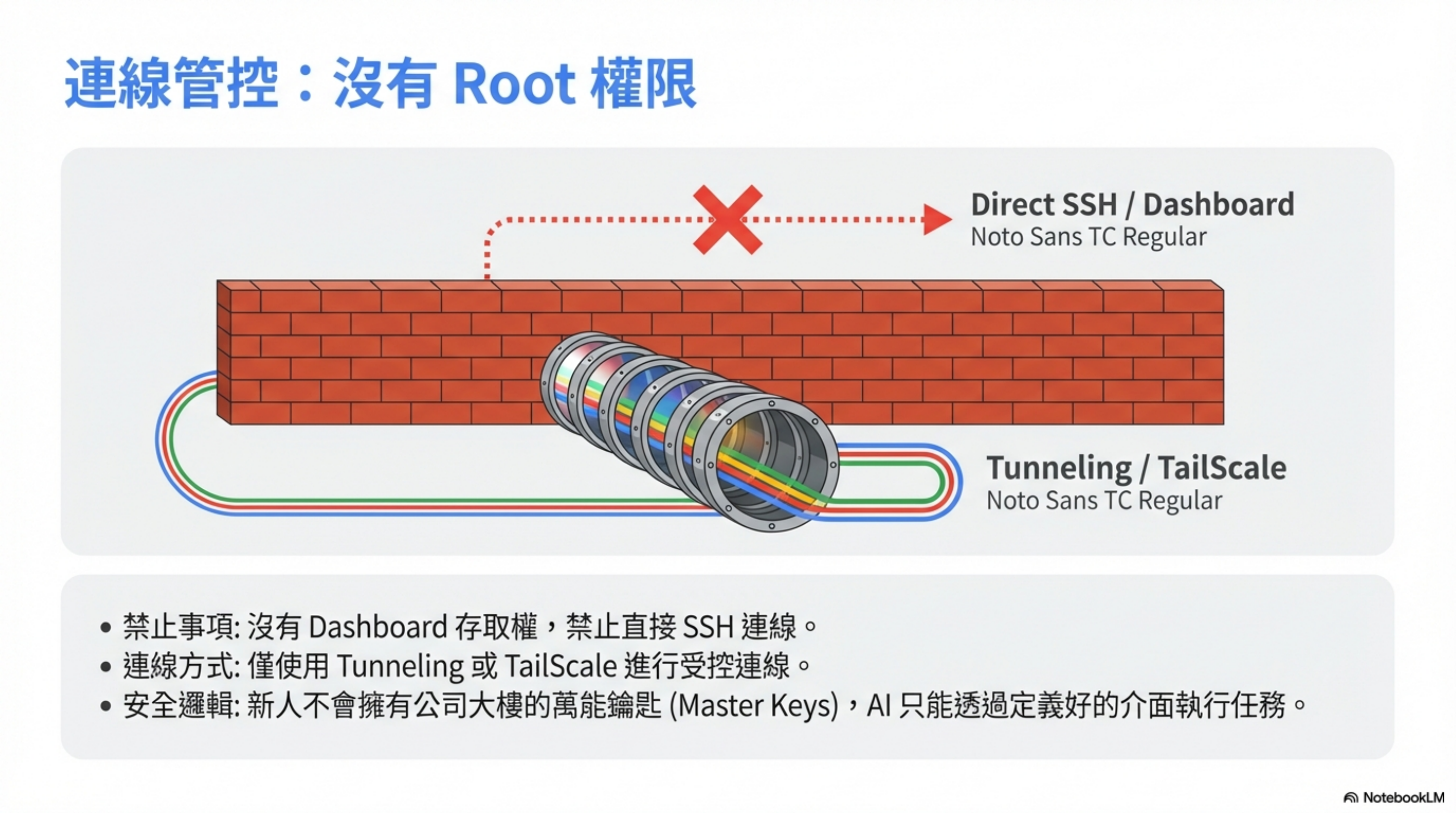
新人不會有 root 權限,AI 也不該有。
沒有 Dashboard 存取,沒有直接 SSH。
永遠選用 Tunneling 或 TailScale 這類有控制的連線方式。
所有操作都要透過定義好的 Skill 介面。
5. 外部 Skill 絕對不進 OpenClaw
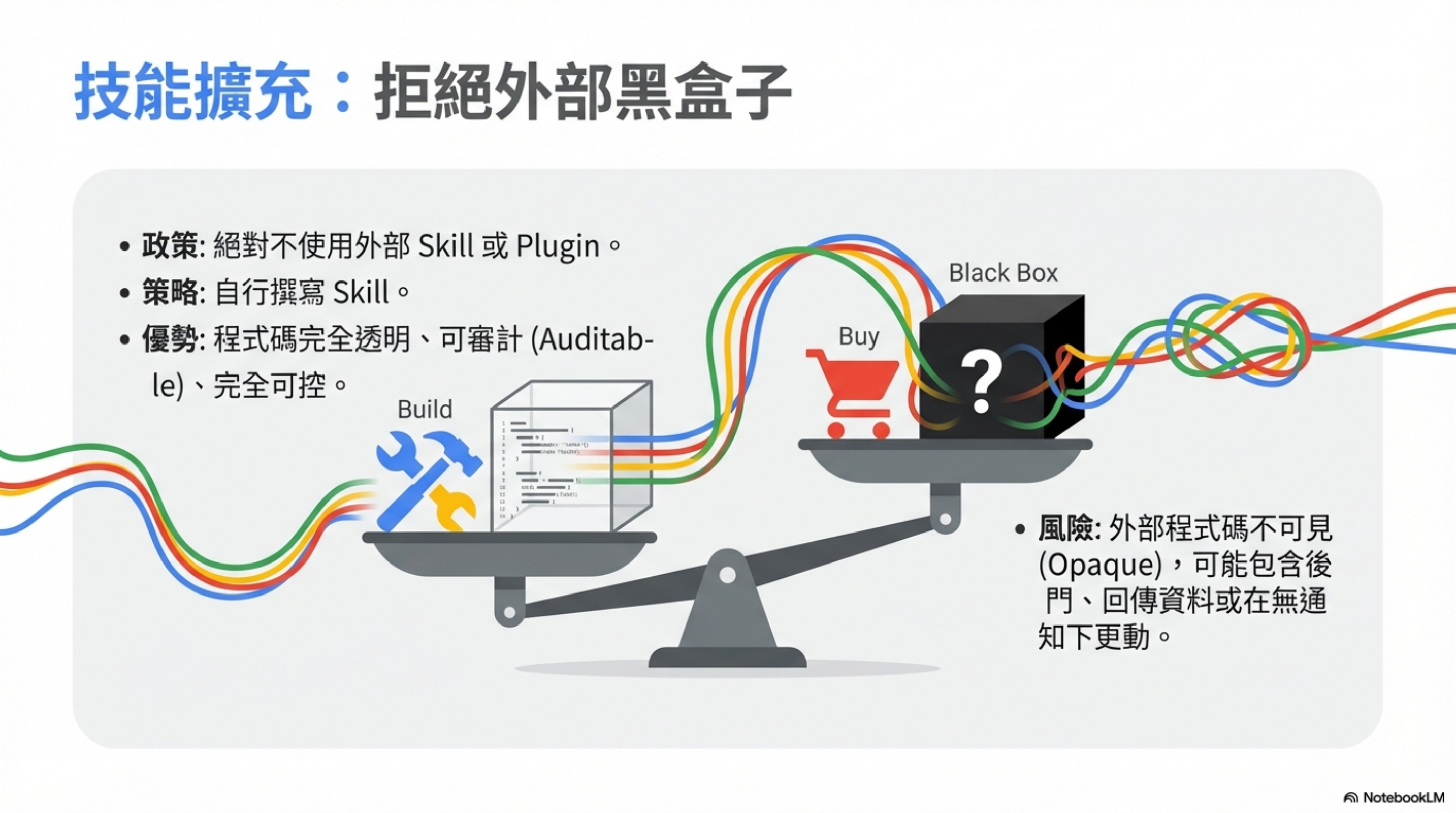
Skill 很好用,但資安風險也很巨大。
絕對不用外部 Skill,一律自己建立自己用。
反正不難。
外部 Skill 的問題:
- 你不知道裡面有什麼程式碼
- 可能有後門或資料回傳
- 更新後可能被注入惡意邏輯
自己寫的 Skill:
- 程式碼完全透明
- 可審計
- 可控
Email:風險最高,所以最嚴格
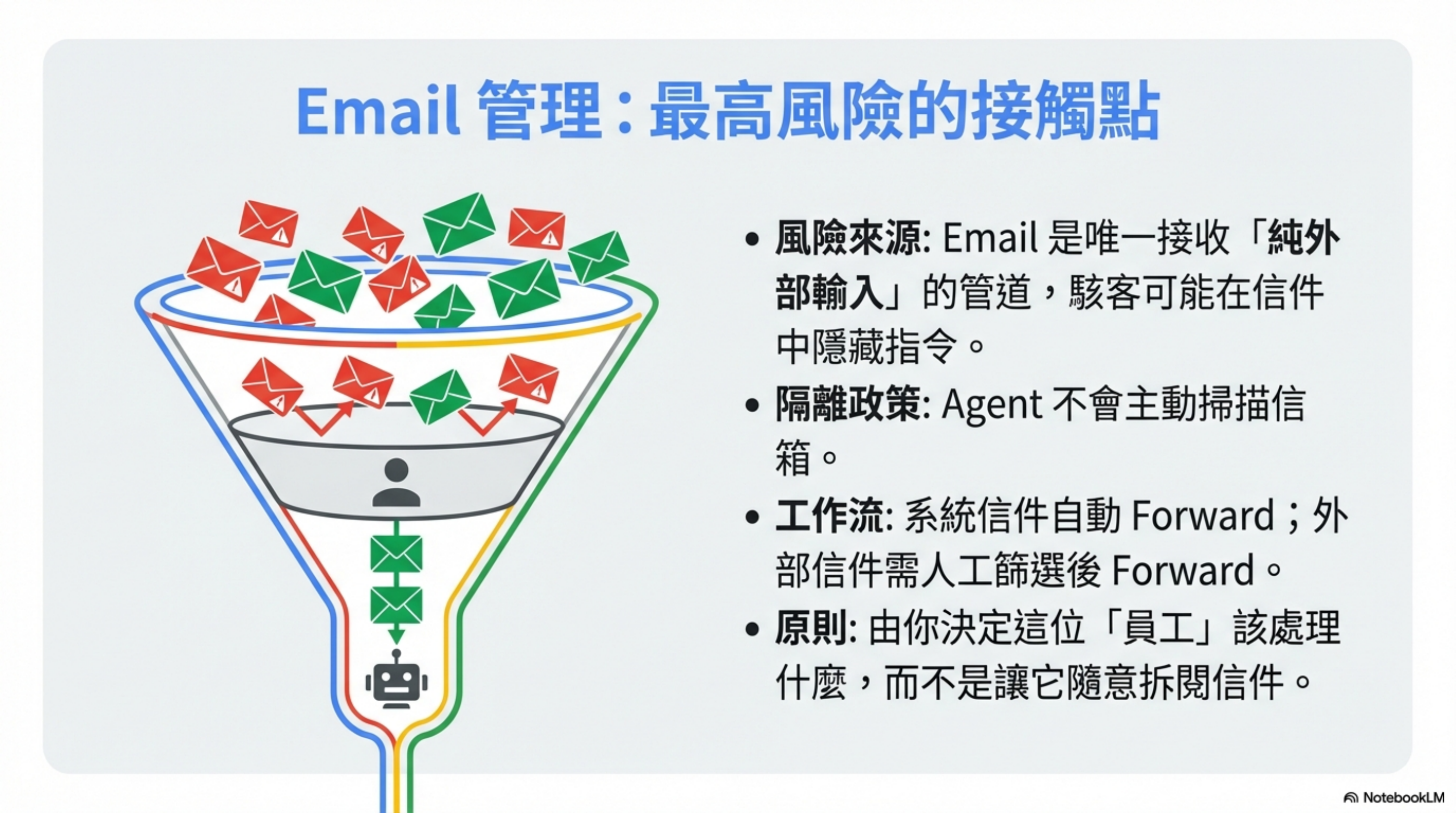
Email 是整個架構裡風險最高的環節。
為什麼?因為 Email 是唯一可以接收純外部輸入的管道。
任何人都可以寄信給你,包括惡意攻擊者。他們可以在郵件裡藏 Prompt Injection 指令。
我的做法:Agent 不自動看我的信
OpenClaw 不會主動掃描我的信箱。
它像秘書一樣等我交辦——我決定哪些事情要交給這個員工,再 forward 過去。
兩層過濾機制
系統產生的信件(自動 Forward):
- 公司很多系統 like JIRA、內部系統的信件
- 用 Gmail Filter 直接 forward 給 OpenClaw 去整理
- 反正幾乎沒有 Prompt Injection 可能性
外部信件(人工 Filter):
- 其他信件一律我覺得需要才 forward
- 銀行、法律、敏感客戶信件 → 永遠不 forward
Python 中介層:Code 層清洗,不是 LLM 清洗
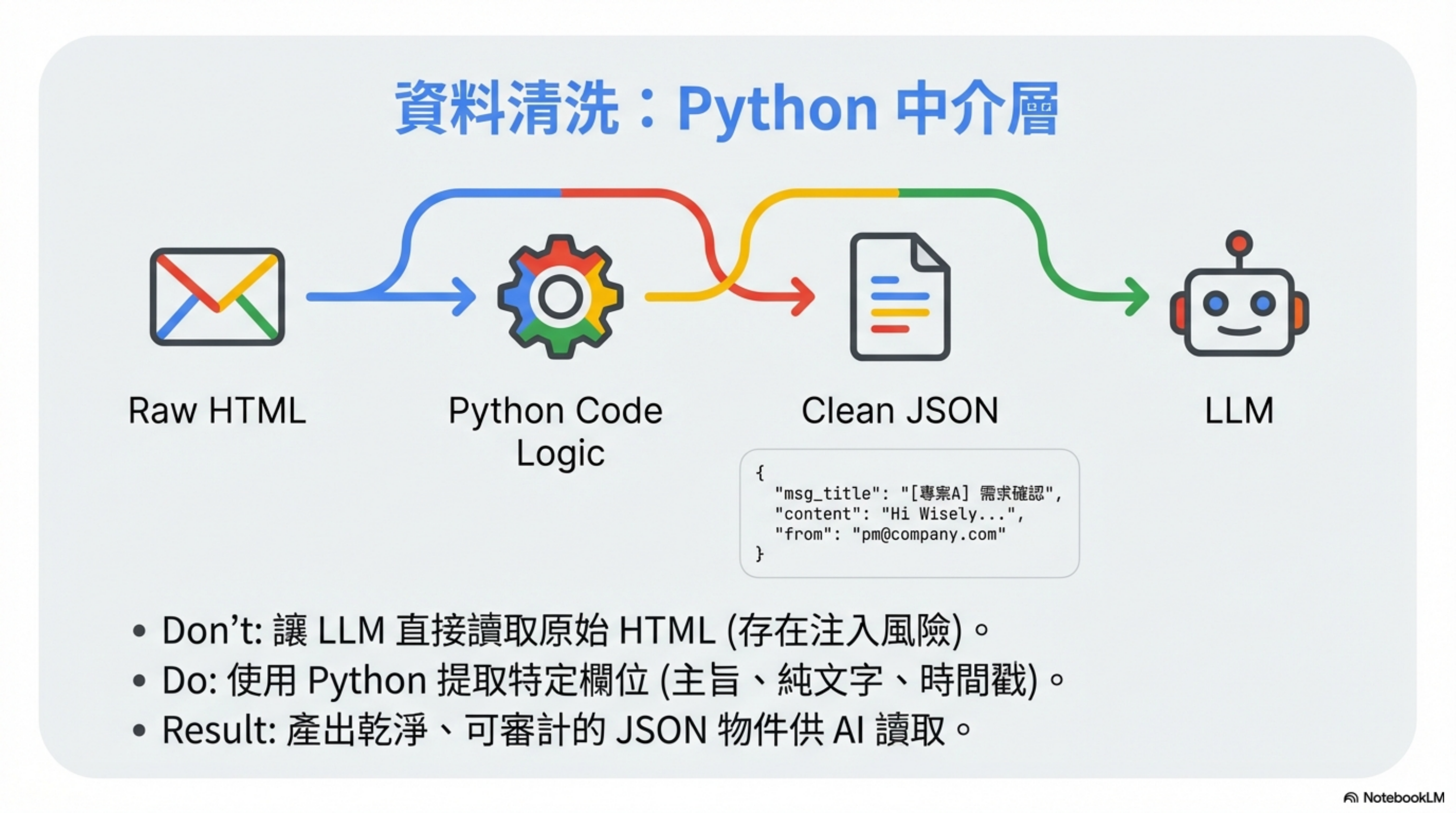
OpenClaw 用 Skill 去讀 Email,而且 LLM 不是直接看。
有一個 Python 中介層先處理,產出乾淨、可審計的 JSON:
1
2
3
4
5
6
7
8
9
10
11
def sanitize_email(raw_email):
"""
產出乾淨、可審計的 JSON
LLM 只看到這個,不看原始 HTML
"""
return {
"msg_title": extract_subject(raw_email),
"content": extract_plain_text(raw_email), # 只取純文字
"from": extract_sender(raw_email),
"timestamp": extract_date(raw_email)
}
最後才給 OpenClaw 去讀:
1
2
3
4
5
6
{
"msg_title": "[專案A] 需求確認",
"content": "Hi Wisely,專案A的需求規格已更新...",
"from": "pm@company.com",
"timestamp": "2026-02-07T10:30:00Z"
}
重點:用 Code 層清洗,不是讓 LLM 去清洗。
- LLM 清洗 = 可能被 Prompt Injection 繞過
- Code 清洗 = 邏輯固定,無法被繞過
另一個重點:避免 OpenClaw Email 地址洩露給外部,降低被塞進 Prompt Injection 的可能。
坦白說:這樣做比較麻煩
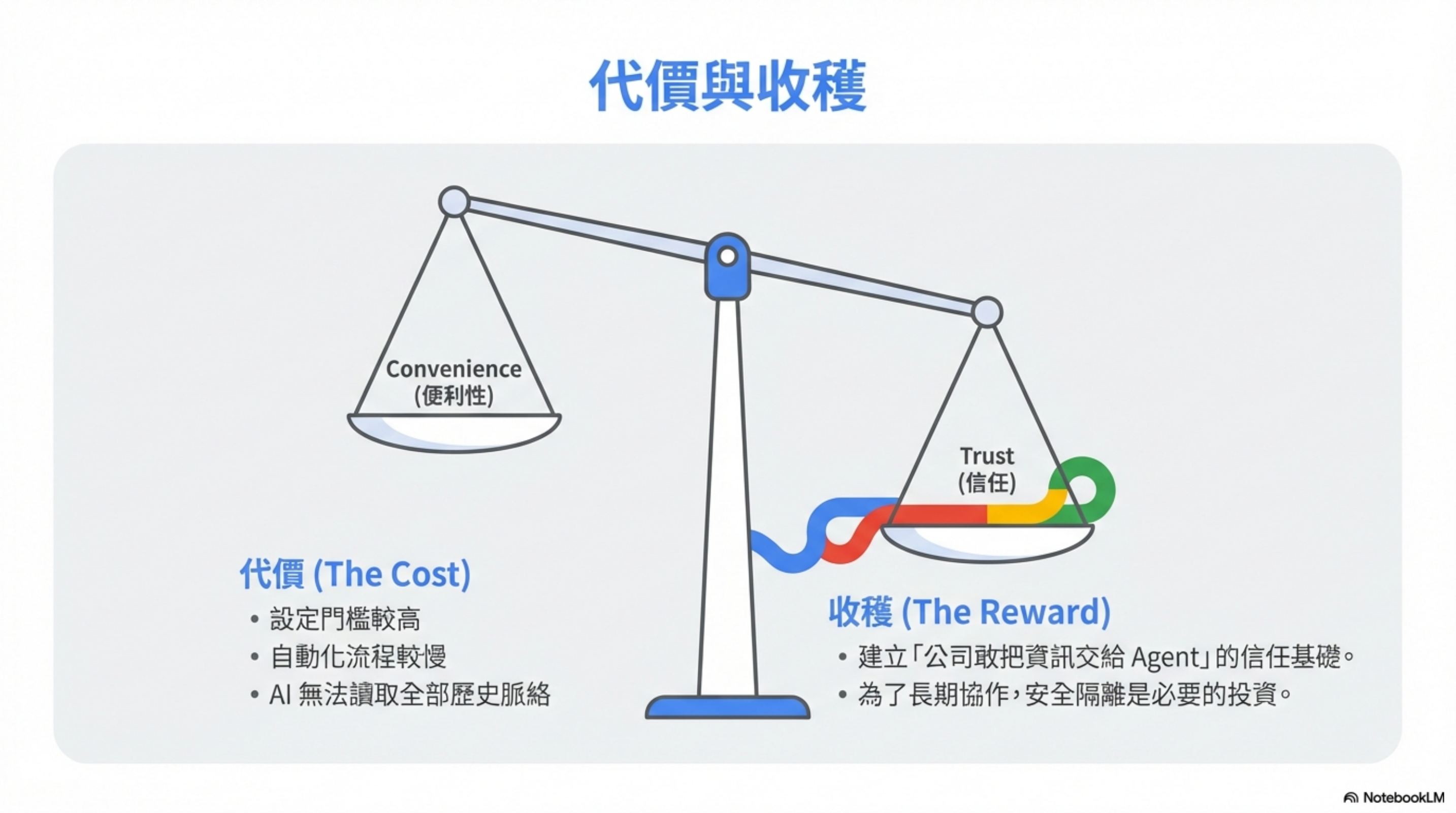
對,我承認。
這套架構的代價:
- AI 看不到你全部歷史脈絡
- 有些自動化會慢一點
- 設定門檻比「直接給權限」高很多
但換來的是一件很重要的事:
公司敢把資訊交出去給 Agent。
結論:你怎麼管新人,就該怎麼管 AI

新人到職,總是要慢慢熟悉彼此。
漸漸給他適合的任務。建立信任。擴大權限。
就算是真人,也會有資訊等級的隔離。
不是因為不信任,而是因為你真的打算長期一起工作。
AI Agent 也是一樣。
你怎麼管新人,就該怎麼管 AI。