PostgreSQL AI Memory Store:為什麼 RAG Vector Store 只是 AI Agent 的一種記憶使用方式

目錄
- 一、RAG 很強,但它只回答企業了 10% 的問題
- 二、我開始建立的是「AI Memory Store」,不是 RAG
- 三、為什麼我選擇 PostgreSQL 當這個「記憶底座」
- 四、RAG,只是 Memory Read Pattern 的其中一種
- 五、市場上有沒有更適合的方案?
- 六、這件事最後會回到一個問題:治理
- 七、實際數據:我在專案中的經驗
- 結語:這是對長期可維運系統的選擇
- 常見問題 Q&A
RAG 只是 AI Agent 可用的第一步,不是最後一步
很多人談到 Vector Store,第一個想到的是 RAG。
文件丟進去、做 embedding、查相似度、餵給 LLM。這套流程已經變成一種標準答案。
但在實際把 AI 系統導入企業後,我越來越清楚一件事:
RAG 解決的是「找資料」,但 AI 系統真正缺的是「記憶」。
一、RAG 很強,但它只回答企業了 10% 的問題
RAG 很擅長處理這類需求:
- 這份文件寫了什麼?
- 過去的 SOP 是什麼?
- 合約第幾條在講什麼?
但在真實的 AI / Agent 系統裡,問題通常長這樣:
- 這個 Agent 之前試過哪些方案?
- 為什麼它上次會做出這個判斷?
- 這個結論是基於哪一批 context?
- 三週前的錯誤,是不是又被重複犯了一次?
- 如果稽核要你回溯這一個月 AI 系統發生了什麼事,你拿得出來嗎?
這些問題,RAG 完全回答不了。
因為它本質上是「查文件」,不是「記憶系統」。
二、我開始建立的是「AI Memory Store」,不是 RAG
於是我開始刻意把架構換一個角度想。
我不再問:
Vector Store 能不能查得快?
我開始問:
AI 系統,三個月後還記得自己做過什麼嗎?
這時候,Vector Store 的角色就變了。
它不只是 embedding 的存放地,而是要同時保存:
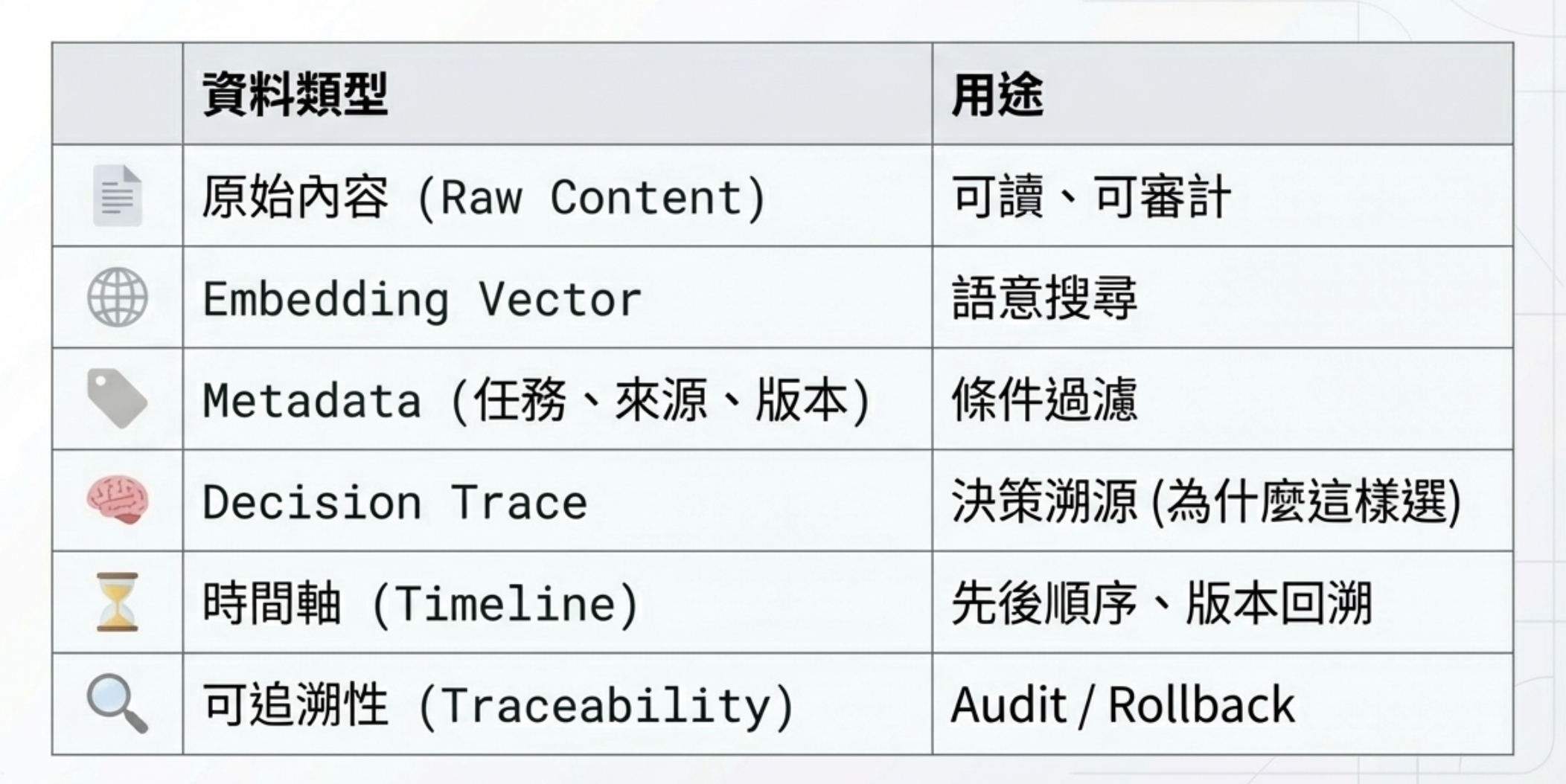
一句話總結:
我不是在存向量,我是在存 AI 的行為歷史。
記憶的價值在於「喚回」
存下來只是第一步,重點是怎麼「喚回」(Recall) 給 LLM。
LLM 的 Context Window 是有限的(即使是 Claude 的 200K,面對大量記憶也不可能全塞)。這意味著:
- 不能只靠向量相似度,還需要精準篩選
- 需要結合 metadata(時間、任務、Agent ID)做過濾
- 需要在有限的 token 內,塞入最相關的「記憶片段」
這正是 SQL 篩選能力重要的原因。純 Vector DB 的 metadata filter 功能有限,但 PostgreSQL 的 WHERE clause 可以做任意複雜的條件組合。
三、為什麼我選擇 PostgreSQL 當這個「記憶底座」
在這個階段,我反而沒有選專用 Vector DB。
我選的是 PostgreSQL + pgvector。
理由其實非常工程師、也非常現實。
因為 AI 記憶不是「純向量問題」
真正常見的需求是:
| 需求 | PostgreSQL 解法 | 專用 Vector DB 解法 |
|---|---|---|
| 向量相似度 + 條件過濾 | 一個 SQL 搞定 | 支援,但語法各異 |
| 向量結果 JOIN 原始資料 | 直接 JOIN,強一致性 | 需同步資料,最終一致 |
| 依任務 / Agent / 使用者分群 | WHERE clause | 支援 metadata filter |
| 依時間版本回溯 | timestamp + ORDER BY | 支援度有限 |
| 權限控管、刪除、審計 | RLS + pg_audit,ACID 保證 | 缺乏關聯完整性 |
| ACID 交易 | 原生支援 | 通常不支援 |
公平地說:現在的 Qdrant、Weaviate、Milvus 都有進步,支援 CRUD 和 metadata filter,甚至一些 Graph 功能。但 PostgreSQL 的核心優勢在於:
- ACID 交易保證:記憶的寫入、更新、刪除是原子操作
- 關聯完整性 (Referential Integrity):foreign key 確保資料一致
- 成熟的權限模型:Row Level Security 是 production-ready 的
這些在專用 Vector DB 裡,要麼不支援,要麼需要自己在應用層補。
實際的 Schema 長這樣
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
CREATE TABLE ai_memory (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
-- 記憶內容
content TEXT NOT NULL,
embedding vector(1536),
-- 來源追蹤
agent_id VARCHAR(50),
task_id VARCHAR(100),
session_id VARCHAR(100),
-- 決策追蹤
decision_type VARCHAR(20), -- 'action', 'reflection', 'error'
reasoning TEXT, -- 為什麼做這個決定
confidence FLOAT,
-- 彈性欄位:存放非結構化的 context
-- 例如 API raw response、tool call 參數等
metadata JSONB DEFAULT '{}',
-- 時間軸
created_at TIMESTAMP DEFAULT NOW(),
expires_at TIMESTAMP, -- 記憶過期時間
-- 版本控制
version INTEGER DEFAULT 1,
parent_id UUID REFERENCES ai_memory(id),
-- 權限
user_id INTEGER REFERENCES users(id),
is_deleted BOOLEAN DEFAULT FALSE
);
-- HNSW index for fast similarity search
CREATE INDEX ON ai_memory
USING hnsw (embedding vector_cosine_ops);
-- 複合索引:常見查詢模式
CREATE INDEX ON ai_memory (agent_id, created_at DESC);
CREATE INDEX ON ai_memory (task_id, decision_type);
-- JSONB 索引:支援彈性查詢
CREATE INDEX ON ai_memory USING gin (metadata);
為什麼加 JSONB? Agent 的行為很難預測,有時候需要存一些非結構化的 context(例如 API call 的 raw response、tool 參數)。PostgreSQL 的 JSONB 類型本身就被設計成可索引、可查詢的半結構化資料,配合 GIN 索引和豐富的 JSON 操作函式(@>、->、->>),讓 AI Memory 在保留彈性的同時,仍然具備可治理性。這也是專用 Vector DB 的 JSON 處理通常比不上 PostgreSQL 的地方。
一個 SQL 就能回答複雜的記憶查詢:
1
2
3
4
5
6
7
8
9
10
11
12
13
-- 查詢:這個 Agent 過去一週犯過的錯誤,有沒有跟現在類似的?
SELECT
content,
reasoning,
created_at,
1 - (embedding <=> $1) AS similarity
FROM ai_memory
WHERE agent_id = $2
AND decision_type = 'error'
AND created_at > NOW() - INTERVAL '7 days'
AND is_deleted = FALSE
ORDER BY embedding <=> $1
LIMIT 5;
四、RAG,只是 Memory Read Pattern 的其中一種
這是我覺得最關鍵的一個觀念轉換。
如果你把 PostgreSQL 當成 AI 的 Memory Layer,那你會發現:

- RAG(讀取記憶):查詢相關的歷史資訊
- Agent Reflection(寫入記憶):記錄決策過程與理由
- Feedback Loop(更新記憶):根據結果修正記憶
- Failure Analysis(重放記憶):回溯錯誤發生的脈絡
這個分類不是我發明的。主流框架如 LangChain 的 Memory 模組就把 Memory 和 RAG 分開處理——Memory 負責對話狀態與長期記憶,RAG 負責外部知識檢索。而 Anthropic 的 Agent 研究更進一步探討 Agent 如何透過反思(Reflection)與回饋迴圈來改善決策品質。
換句話說:
RAG 不是架構核心,它只是其中一個使用模式。
當你這樣想,架構設計就會完全不一樣。
五、市場上有沒有更適合的方案?
在選擇 PostgreSQL 之前,我確實評估過其他方案。誠實講,市場上不只 PostgreSQL 能當「自家記憶庫」,各有各的強項:
方案比較總覽
| 方案類型 | 代表產品 | 主要強項 | 適合的 Memory Model |
|---|---|---|---|
| In-Memory Store | Redis / Memorystore | 超低延遲、狀態管理 | Session / 短期記憶 |
| 專用 Vector DB | Pinecone / Qdrant / Milvus | 大規模 ANN、語意搜尋 | 億級語意記憶 |
| SQL + Vector | PostgreSQL + pgvector | 結構 + 語意 + 治理 | 複合記憶 + governance |
| Graph DB | Neo4j / Neptune | 關係 / 因果推理 | 結構化 memory |
| AI Memory Stack | Pieces / Mem0 | 自然語境記憶 | 長期 context 重用 |
| AI Query Engine | MindsDB | AI + Data 查詢合一 | query + memory 整合 |
什麼時候該用其他方案?
Redis / In-Memory Store
- 每秒多次 agent thought
- 即時對話狀態
- streaming token context
- 需要 sub-millisecond 延遲
專用 Vector DB(Pinecone / Milvus)
- 向量數量 > 10^8
- 純語意搜尋,不需要 relational data
- consumer-scale 推薦系統
Graph DB(Neo4j)
- 複雜的實體關係(「userA 跟 userB 在同一專案」)
- 因果鏈追蹤
- 需要顯式關係查詢
那 PostgreSQL 能不能 One Size Fit All?
可以,但有前提。
PostgreSQL 不是 All-in-one Engine,而是 AI Memory 的 Single Source of Truth。
正確的理解方式:
| ❌ 錯誤理解 | ✅ 正確理解 |
|---|---|
| PostgreSQL 要扛所有 latency / scale 問題 | PostgreSQL 當「記憶權威層」 |
| 所有查詢都走 PostgreSQL | 其他系統是「加速器」,但資料模型以 PostgreSQL 為準 |
一個成熟的架構可能是:
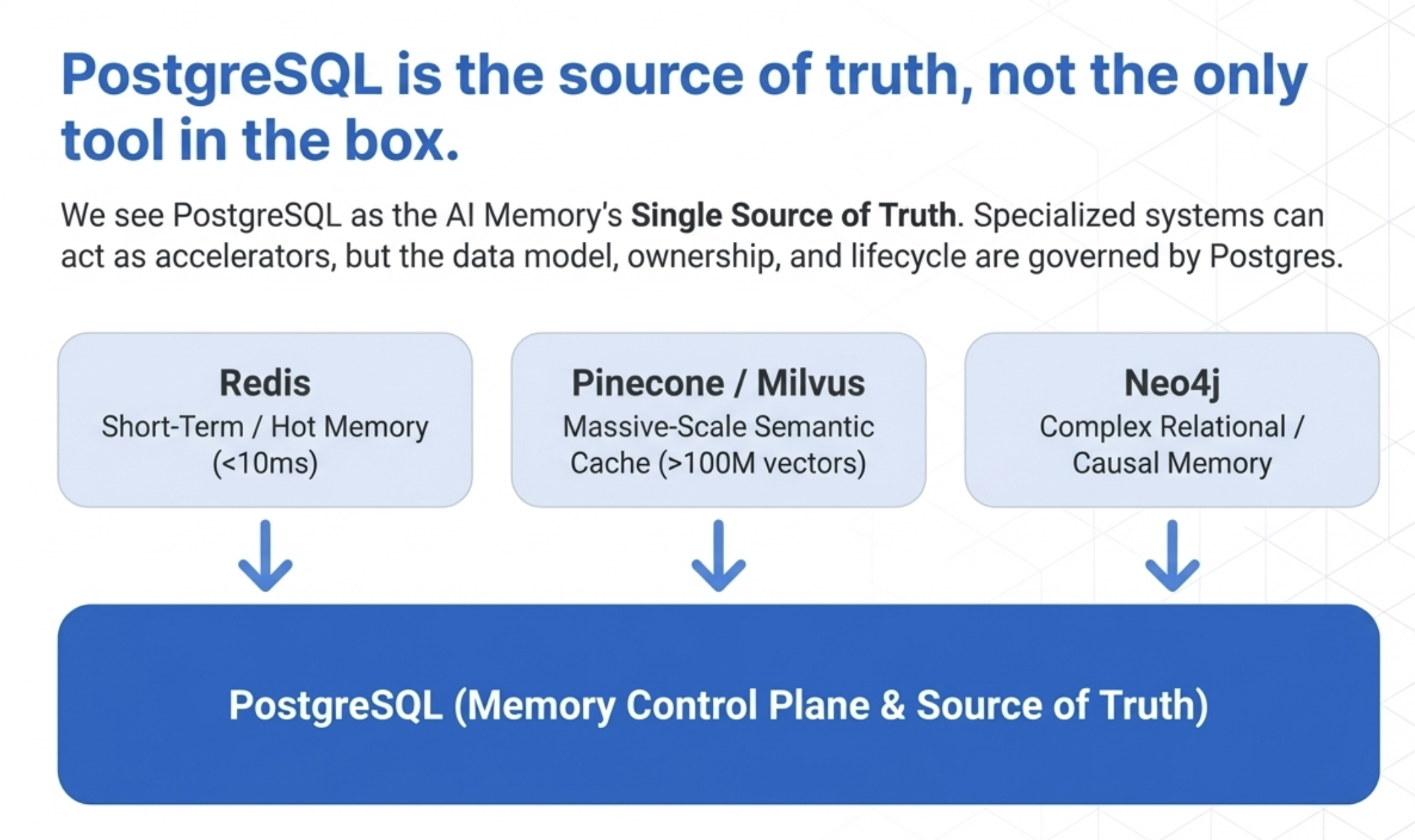
關鍵原則:
- Redis:短期記憶 cache
- Vector DB:大規模 ANN offload
- Graph DB:複雜關係推理
- 但:資料模型、ID、ownership、life-cycle,全部以 PostgreSQL 為準
為什麼我還是選擇 PostgreSQL 為主?
因為在 80% 的企業 AI 專案中,真正的問題不是效能,而是:
- 不知道 AI 為什麼這樣做
- 出事時查不到責任鏈
- 記憶刪不掉、改不了、解釋不了
這些都是治理問題,不是效能問題。
PostgreSQL 能不能 One Size Fit All,取決於你問的是「效能極限」,還是「系統責任邊界」。
在 AI 系統裡,我寧願效能交給專用工具,也不會把記憶主權交出去。
六、這件事最後會回到一個問題:治理
當 AI Agent 如同 Google Research 在 Nested Learning 論文說的需要有「可累積的記憶」,接下來就一定會遇到這些問題:
- 哪些記憶可以長期保存?
- 哪些應該被淘汰?
- AI 的錯誤,能不能被追蹤與修正?
- 出事時,能不能解釋「為什麼會這樣做」?
這已經不是搜尋問題,而是 AI 治理問題。
而這正是我不想把「記憶」交給一個黑盒系統的原因。
PostgreSQL 在治理上的優勢
| 治理需求 | PostgreSQL 解法 |
|---|---|
| 記憶過期 | expires_at + 定期清理 job |
| 刪除權 | is_deleted soft delete + GDPR compliant |
| 審計追蹤 | pg_audit extension |
| 版本回溯 | parent_id + version 欄位 |
| 權限控制 | Row Level Security |
| 備份還原 | 標準 pg_dump / WAL |
這些在專用 Vector DB 裡,每一個都要自己補。特別是「刪除權」——GDPR 的 Right to be Forgotten 不是可選項,而是法律要求。當使用者要求刪除他的資料時,你的 AI 記憶庫必須能做到。
核武級功能:Row Level Security (RLS)
這是 PostgreSQL 對比專用 Vector DB 的最大殺手鐧,能從資料庫引擎層級直接控管 AI Agent 的存取權限。
場景: 你做了一個企業知識庫,裡面有「人資規章(全公司可見)」和「薪資條(僅本人可見)」。
Vector DB 的痛點: 大多數 Vector DB 的權限管控只到 Collection/Index 層級。也就是說,開發者必須在 Application Code(Python/Node.js)寫邏輯去過濾資料。
風險: 只要工程師寫錯一行 code(例如漏了 user_id filter),A 員工就能搜到 B 員工的薪資向量。
PostgreSQL 的 RLS: 權限是綁在資料庫引擎層級的。
1
2
3
4
5
6
7
-- 設定好 Policy
CREATE POLICY user_data ON ai_memory
FOR SELECT
USING (user_id = current_setting('app.current_user_id')::INTEGER);
-- 啟用 RLS
ALTER TABLE ai_memory ENABLE ROW LEVEL SECURITY;
之後無論你的 Python code 怎麼寫(甚至寫 SELECT * FROM ai_memory),資料庫自動只會吐出該使用者的資料。
這對 RAG 至關重要:它確保了 AI 永遠不會「意外」讀到它不該讀的 Context。
成熟的身分驗證與整合
企業資安不僅是「密碼」,而是「身分治理」。
| 面向 | 專用 Vector DB | PostgreSQL |
|---|---|---|
| 認證方式 | 通常僅 API Key | LDAP / AD / Kerberos / SCRAM-SHA-256 |
| SSO 整合 | 有限或不支援 | 原生支援企業 SSO |
| 離職處理 | 需手動輪替 API Key | 帳號停用即失去權限 |
| 操作追蹤 | 難以區分個人 | 每個操作都有 user identity |
實際意義: 如果某員工離職,公司帳號一停用,他對 AI 記憶庫的存取權限也同步切斷,不需要去輪替 API Key。
細粒度的稽核 (Auditing)
AI 治理的核心是:「誰?在什麼時候?問了什麼?系統讀了哪幾條記憶?」
| 面向 | 專用 Vector DB | PostgreSQL (pg_audit) |
|---|---|---|
| Log 粒度 | API 呼叫紀錄 | 可記錄到每筆資料存取 |
| 內容追蹤 | 通常看不到 | 可記錄「讀取了 ID 5566 的薪資資料」 |
| SIEM 整合 | 需自己做 | 直接送到 Splunk / ELK |
| 合規稽核 | 需額外開發 | 原生支援 ISO 27001 / GDPR / SOC 2 |
這對於通過企業稽核是必備的——也是台灣《人工智慧基本法》中「透明及可解釋性」與「可問責性」原則的技術實踐。完整的企業級架構還需要 Auth Gateway、沙盒、雙層 Log 等元件,可參考:企業級地端 LLM 架構藍圖。
資料加密
| 加密層級 | 專用 Vector DB | PostgreSQL |
|---|---|---|
| 傳輸加密 (TLS/SSL) | ✅ | ✅ |
| 靜態加密 (At Rest) | ✅(雲端版) | ✅ |
| 欄位級加密 | ❌ | ✅ (pgcrypto) |
欄位級加密的意義: 你可以只針對 content 或 pii_data 欄位加密。這意味著即使 DBA 直接打開資料庫檔案,他也看不到敏感內容,只有擁有金鑰的應用程式解得開。
1
2
3
4
5
6
7
8
9
10
-- 使用 pgcrypto 加密敏感欄位
INSERT INTO ai_memory (content, encrypted_pii)
VALUES (
'general content',
pgp_sym_encrypt('sensitive salary data', 'encryption_key')
);
-- 解密時
SELECT pgp_sym_decrypt(encrypted_pii, 'encryption_key') AS pii_data
FROM ai_memory;
七、實際數據:我在專案中的經驗
| 專案類型 | Memory 數量 | 查詢延遲 | 特殊需求 |
|---|---|---|---|
| Agent 決策追蹤 | ~100,000 | < 100ms | 需要 reasoning 欄位 |
| 多租戶知識庫 | ~500,000 | < 150ms | 需要 RLS 權限隔離 |
| Feedback Loop | ~50,000 | < 50ms | 需要 version 回溯 |
| 錯誤分析 | ~20,000 | < 80ms | 需要 JOIN 原始 log |
這些場景,PostgreSQL 都跑得很穩。而且因為所有資料在同一個地方,做分析、做報表、做 debug 都非常方便。
誠實說:PostgreSQL 的維護成本
當然,PostgreSQL 也不是沒有代價。
當 Agent 頻繁寫入記憶時,會遇到一些維運挑戰:
| 挑戰 | 說明 | 解法 |
|---|---|---|
| HNSW 索引重建 | 大量 INSERT 後索引效能下降 | 定期 REINDEX,或用 IVFFlat |
| Autovacuum 壓力 | 頻繁 UPDATE/DELETE 產生死行 | 調整 autovacuum 參數 |
| 表膨脹 | 長期運行後表空間增長 | 定期 VACUUM FULL(需停機) |
| 連線管理 | 高併發寫入時連線池壓力 | 使用 PgBouncer |
但相對於它帶來的治理優勢,這是我願意付出的 Day 2 運維成本。
畢竟,調參數和寫 cron job 是可預期的工程工作;但「AI 出事時解釋不了為什麼」是無法預期的業務風險。
結語:這是對長期可維運系統的選擇
當大家還在討論要不要用 RAG、用哪一家 Vector DB 的時候,我更在意的是另一件事:
這個 AI 系統,半年後還能不能說清楚自己為什麼做出這個決策?
對我來說,把 PostgreSQL 當成 AI 的「自家記憶庫」,不是退而求其次,而是一個對長期可維運、可治理系統的選擇。
常見問題 Q&A
Q: PostgreSQL 的向量搜尋效能比得上專用 Vector DB 嗎?
在百萬級以下的記憶數量,PostgreSQL + pgvector 的效能完全夠用。我的實際專案經驗是 50 萬筆記憶、查詢延遲 < 150ms。當然,如果你的場景是億級向量、純語意搜尋,專用 Vector DB(Pinecone、Milvus)確實更適合。但 80% 的企業 AI 專案,瓶頸不在向量搜尋速度,而在於「出事時能不能解釋」。
Q: pgvector 支援哪些索引類型?該怎麼選?
pgvector 主要支援 IVFFlat 和 HNSW 兩種。IVFFlat 建索引快、適合資料常變動的場景;HNSW 查詢更快、但索引維護成本較高。我的建議是:如果記憶會頻繁寫入,用 IVFFlat;如果主要是讀取(像 RAG),用 HNSW。
Q: 為什麼不用 Pinecone 或 Weaviate 這類專用 Vector DB?
專用 Vector DB 很強,但在 AI Agent 場景,你需要的不只是「查向量」。你還需要:向量結果 JOIN 原始資料、依時間版本回溯、權限控管(RLS)、ACID 交易保證。這些在 PostgreSQL 是原生支援,在專用 Vector DB 通常要自己在應用層補。
Q: RAG 和 AI Memory Store 有什麼不同?
RAG 是「讀取記憶」的一種模式——用向量相似度找相關文件。但 AI Memory Store 還包括:寫入記憶(Agent 決策紀錄)、更新記憶(Feedback Loop)、重放記憶(錯誤分析)。簡單說,RAG 是 Memory 的 Read Pattern 之一,不是全部。
Q: PostgreSQL 怎麼處理 GDPR 的「被遺忘權」?
PostgreSQL 的 soft delete(is_deleted 欄位)加上 pg_audit 稽核追蹤,可以完整記錄「誰在什麼時候刪除了什麼」。配合 Row Level Security,確保刪除操作只影響該使用者的資料。這是專用 Vector DB 很難做到的——它們通常沒有關聯完整性,刪除時容易漏掉相關資料。
Q: 多租戶(Multi-tenant)場景,PostgreSQL 怎麼隔離資料?
用 Row Level Security (RLS)。設定好 Policy 後,無論應用程式怎麼查詢,資料庫引擎自動只回傳該租戶的資料。這比在 Python/Node.js 寫 filter 安全多了——程式碼寫錯一行就可能洩漏資料,但 RLS 是資料庫層級的保證。
Q: pgvector 需要額外付費嗎?
不用。pgvector 是開源的,Apache 2.0 授權。只要你的 PostgreSQL 版本 >= 11,就可以安裝。主流雲端服務(AWS RDS、GCP Cloud SQL、Azure)也都開始支援。
Q: 這套架構適合什麼規模的團隊?
適合 2-20 人的 AI 開發團隊。太小的團隊可能不需要這麼完整的治理;太大的企業可能需要更複雜的分層架構(Redis 做 cache、專用 Vector DB 做 offload)。但 PostgreSQL 作為「記憶主權層」的概念,在任何規模都適用。
延伸閱讀
技術資源
- pgvector GitHub — PostgreSQL 向量擴充的官方 repo
- PostgreSQL JSONB 官方文件 — JSON vs JSONB、索引、查詢操作
- LangChain Memory 官方文件 — 主流框架如何區分 Memory 與 RAG
- Anthropic Research — Agent 行為、反思與長期安全的研究
治理與合規
- GDPR Article 17 — Right to Erasure — 「被遺忘權」的法律條文
- 台灣《人工智慧基本法》:IT 主管必讀 — 七大原則與 Audit Trail 實務
- 企業級地端 LLM 架構藍圖 — Auth Gateway、沙盒、雙層 Log 的完整設計
相關文章
- CaMeL Agent 架構落地 PostgreSQL:用 RLS 設計不可繞過的 AI Memory 與權限隔離 - 將 Google DeepMind 的 CaMeL 架構實作到資料庫層
- Google Nested Learning:讓模型擁有大腦般的長期記憶
- AI 企業轉型:治理支柱
- 我的 ATPM 框架:AI Coding 的生產實踐