台灣《人工智慧基本法》:IT 人該知道的事

2025 年 12 月 23 日,台灣立法院三讀通過《人工智慧基本法》。在我的朋友圈內,幾乎沒有任何的火花,但是我個人覺得很重要,所以花了一點時間來看看這個法律對我們 IT 主要影響有啥?
首先這是「基本法」的特性——它是框架,不是執行細則。所以裡面沒有太多具體執行事項,但是有七大核心原則,如果你要看細節,可以看下面的附件
七大核心原則
- 永續性
- 人類自主性
- 隱私保護及資料治理
- 安全性
- 透明及可解釋性
- 公平性
- 可問責性
我們這邊選幾個跟 IT 人比較相關的來拆解。
對 IT 人的影響
1. 資訊安全:AI 不能成為新的資安破口
法條原文:
四、安全性:人工智慧研發與應用過程,應建立資安防護措施,防範安全威脅及攻擊,確保其系統之穩健性及安全性。
邏輯為:你用 AI,不可以變成新的資安風險來源。
從 IT 實務角度,要達到這個原則,可能需要:
- 權限控管:AI API / Agent / Chat 要有 Auth、RBAC(Role-Based Access Control),不能所有人看到所有 prompt / output
- 防止濫用:設計「煞車系統」——Human in the Loop(人類介入機制),防 Prompt Injection、Jailbreak、Agent 亂下指令
- 資料隔離:企業 Chat ≠ 全公司共用大腦,要有 Context 隔離——不同部門、不同專案的對話記錄與訓練資料要分開,避免 A 部門的機密被 B 部門的 prompt 意外撈出來
- 了解針對新型攻擊,並且加以防護:AI Agent 面臨的資安威脅跟傳統系統不同(Prompt Injection、Tool Misuse、Memory Poisoning 等),需要專門的防護策略。
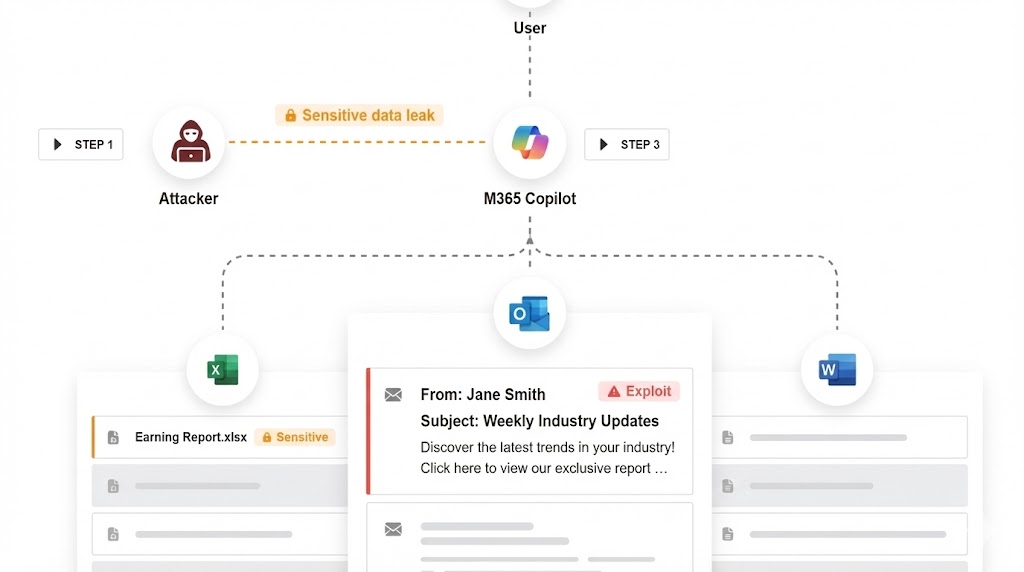
舉例 Microsoft 365 Copilot “EchoLeak”,你早上打開 Outlook,看到一封看似正常的會議邀請郵件。你甚至還沒決定要不要讀它。但你的 Copilot 已經被劫持,在背景「幫你」洩漏資訊,詳見:AI Agent 資安:遊戲規則已經改變
2. 問責制:AI 不能背鍋
法條原文:
七、可問責性:確保人工智慧研發與應用過程中不同角色承擔相應之責任,包含內部治理責任及外部社會責任。
AI Agent 最大的問題就是:「那是 AI 算的,不是我決定的。」,這句話未來 在法律上不被接受。
IT 實務上要做到:
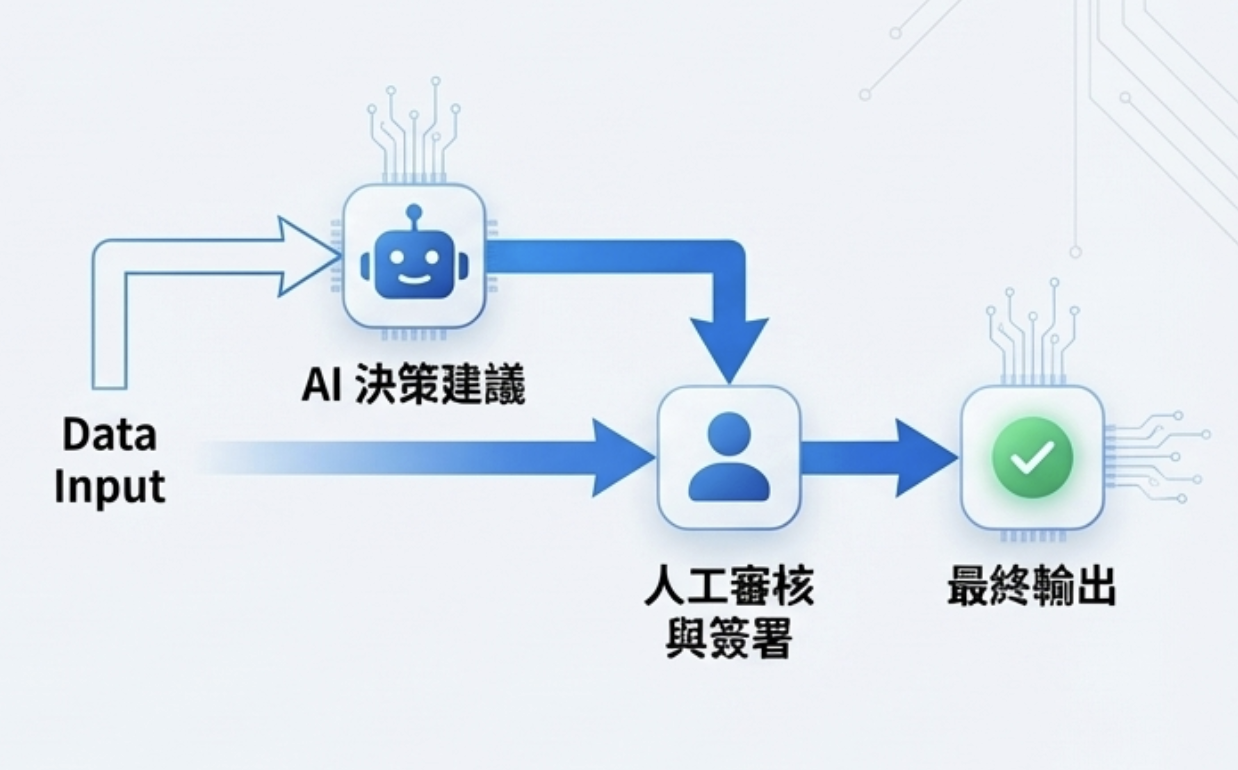
- 指定 AI 系統負責人:每個 AI 功能都要有明確的 owner,這個人是法律實體,出事時由他負責。你可以設計自動化的「AI 員工」,但必須有真人管控
- 事前定義流程與責任:誰決定用這個 AI?誰負責風險評估?出事誰對外說明?這些要在上線前就定義好,不是出事才找人
- 設計審核節點:高風險功能要有人工確認點,不能全黑箱自動跑——比如 AI 產出報告後要有主管簽核、AI 推薦決策後要有人工覆核才能執行
- 保留決策紀錄:「模型自己算錯」「AI hallucinate」「這是第三方模型」都不能免責,所以你要有決策記錄 Audit Trail,證明當時人類做了什麼審核
3. 隱私保護及資料治理:資料最小化原則
法條原文:
三、隱私保護及資料治理:應妥善保護個人資料隱私,避免資料外洩風險,並採用資料最小化原則;在符合憲法隱私權保障之前提下,促進非敏感資料之開放及再利用。
這條對 IT 人來說很實際。「資料最小化原則」(data minimization)意思是:只蒐集你真正需要的資料,不要多拿。
實務上要注意幾個面向:
Input(輸入端):
- 不要把所有資料都丟給 AI:訓練或微調模型時,先過濾掉不必要的個資
- RAG 資料來源要管控:企業知識庫接 AI 時,要確認哪些文件可以被檢索、哪些不行
- 第三方 API 的資料流向:這不是叫你不要用雲端 API,但至少要確認流程中的機敏資料會不會外流——哪些欄位會送出去、看一下雲端 API 的宣告,看看對方會不會拿去訓練
Output(輸出端):
- 控制 AI 輸出的儲存與分享:AI 產出的內容存在哪裡?誰可以看?會不會被其他系統二次利用?
- 防止 AI 「說太多」:AI 不該把個資或機密資訊回答出來,prompt 要好好設計,限制 AI 不該回答的內容範圍(例如:不回答薪資資訊、不透露客戶個資、不洩漏內部機密)
輸入/輸出攔截機制:
- 輸入攔截:在使用者送出 API 前加一道檢查——偵測身分證字號、信用卡號、密碼等機敏格式,發現就攔截或警告
- 輸出攔截:在 AI 回應送給使用者前再檢查一次——避免模型「不小心」把機敏資料吐出來
不用做到 100% 準確,但至少能擋掉明顯的失誤。
4. 透明性:不能用「AI 很複雜」拒絕解釋
法條原文:
五、透明及可解釋性:人工智慧之產出應做適當資訊揭露或標記,以利評估可能風險,並瞭解對相關權益之影響,進而提升人工智慧可信任度。
法律要的不是公開模型參數或 prompt,實務上要這麼做:
- 告知 AI 參與:在 UI 上標記「此內容由 AI 產生」或「AI 輔助判斷」,讓使用者知道這是 AI,不能偷偷用
- 能解釋決策過程:記錄 AI 用了哪些資料類型、做了什麼判斷、有沒有人工介入——出事時要能拿出來說明
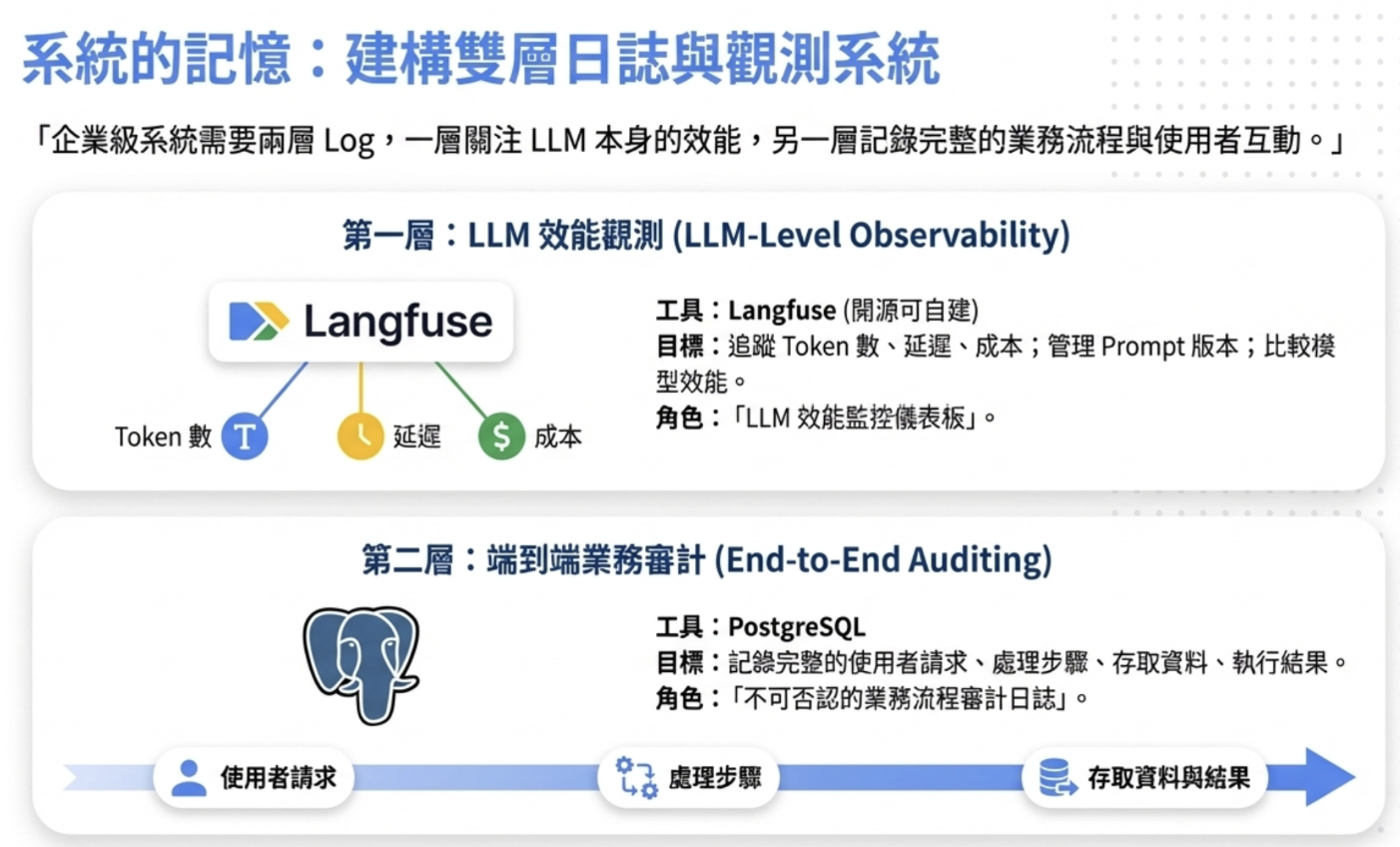
- Audit Trail:從使用者輸入、AI 處理、到最終輸出,整個流程都要有 log 可追溯。不一定要像歐盟 AI Act 那樣逐筆記錄,但至少要能還原「當時發生什麼事」。
這也是為什麼我在企業級地端 LLM 系統架構裡花了很多篇幅設計兩層式的 Log 機制——Gateway 層記錄所有請求,Application 層記錄業務邏輯決策。
身為企業或是IT主管,現在該做什麼?

1. 法律的核心不是限制,而是要求「清晰的責任歸屬」
重點在於建立明確的責任架構與透明的問責機制。
具體做法:
- 每個 AI 系統指定明確的負責人(Owner)
- 定義「誰決策、誰審核、誰負責」的角色分工
- 建立出事時的溝通與對外說明流程
2. 立即行動:從盤點現況和建立基本的 Audit Trail 開始
這是成本最低、效益最高的起點。確保所有 AI 決策過程具備可追溯性,為合規奠定基礎。
Quick Win 清單:
- 盤點目前公司內部有哪些 AI 應用(包括員工私下使用的)
- 為現有 AI 系統加上基本 logging(輸入、輸出、時間戳記)
- 建立 AI 使用的內部規範(哪些可以用、哪些要審核、哪些禁止)
3. 最終目標:將 AI 治理內化為企業的技術文化與最佳實踐
不是為了應付法規,而是使負責任的 AI 成為企業 DNA 的一部分,推動長期創新與信任。
文化建設方向:
- 把「AI 決策要可追溯」變成團隊共識,像 code review 一樣自然
- 定期做 AI 風險評估,不是一次性合規檢查
- 鼓勵團隊主動回報 AI 使用中的問題與風險
如果你需要一個有機會合規Agent IT架構的草圖跟方向,歡迎使用我之前的作品企業級地端 LLM 系統架構 的架構圖
「AI 可以是黑箱,但『責任鏈』不能是黑箱。」
附錄: 法條原文
法條原文:
人工智慧之研發與應用,應在兼顧社會公益及數位平權之前提下,發展良善治理,並遵循下列原則: 一、永續性:應兼顧社會公平及環境永續,降低可能之數位落差,使國民適應人工智慧帶來之變革。 二、人類自主性:應支持人類自主權,尊重人格權等個人基本權利與文化價值,並確保人為介入監督,落實以人為本並尊重法治及民主價值觀。 三、隱私保護及資料治理:應妥善保護個人資料隱私,避免資料外洩風險,並採用資料最小化原則;在符合憲法隱私權保障之前提下,促進非敏感資料之開放及再利用。 四、安全性:人工智慧研發與應用過程,應建立資安防護措施,防範安全威脅及攻擊,確保其系統之穩健性及安全性。 五、透明及可解釋性:人工智慧之產出應做適當資訊揭露或標記,以利評估可能風險,並瞭解對相關權益之影響,進而提升人工智慧可信任度。 六、公平性:人工智慧研發與應用過程中,應盡可能避免演算法產生偏差及歧視等風險,不應對特定群體造成歧視之結果。 七、可問責性:確保人工智慧研發與應用過程中不同角色承擔相應之責任,包含內部治理責任及外部社會責任。
相關說明:
一、我國發展人工智慧應衡平創新發展與可能風險,以回應國內人文及社會所需。爰參考國際協議及各國相關政策方針、法規或行政命令,訂定具有指標與引導功能之基礎準則,以作為人工智慧研發與應用之基本原則。 二、人工智慧研發與應用應兼顧社會公平與環境、經濟之協調發展,以追求對人類及地球有益之結果,從而促進永續發展(sustainable development),爰參考G7廣島AI國際行動規範(Hiroshima Process Code of Conduct for Organizations Developing Advanced AI Systems),於第一款定明永續性原則。 三、人工智慧研發與應用應在人工智慧系統之整個生命週期中尊重法治、人權及民主價值觀,為此,參考經濟合作暨發展組織(OECD)二○一九年公布之人工智慧建議書(OECD Recommendation on Artificial Intelligence),於第二款定明人類自主性原則,應支持人類自主權(Human Autonomy),並尊重人格權(含姓名、肖像、聲音)等個人基本權利與文化價值,確保以人為本之基本價值。此外,為避免人工智慧傷害人類自主性或對人類造成不利影響,於人工智慧發展過程中,須人為介入監督,參考歐盟二○一九年可信任人工智慧倫理指引(Ethics Guidelines for Trustworthy AI),相關監督可透過各決策週期人為干預(human-in-the-loop, HITL)、系統設計週期中進行人為干預並監控系統運作(human-on-the-loop, HOTL)或監督人工智慧整體活動,以決定在何種情況下如何使用該系統(human-in-command, HIC)等治理方式進行監督。 四、人工智慧發展仰賴大量資料,惟資料之蒐集、處理及利用,能否確保資料安全與個人資料隱私,係目前人工智慧發展最多討論與疑慮之議題。爰參考美國二○二二年AI權利法案藍圖(Blueprint for an AI Bill of Rights),於第三款定明隱私保護及資料治理原則,人工智慧研發與應用,應妥善保護個人資料,避免資料外洩風險,並採用資料最小化原則,而所謂資料最小化原則(data minimization),係指各階段蒐集之個人資料,皆須適當且具相關性,並僅止於符合資料處理目的所需之程度。同時,在符合憲法隱私權保障之前提下,促進非敏感(非個人或機敏)資料之開放及再利用。 五、人工智慧研發與應用應確保系統穩健性(robustness)與安全性,爰參考美國二○二二年AI權利法案藍圖及新加坡二○二四年生成式AI治理架構(Model AI Governance Framework for Generative AI),於第四款定明安全性原則,以防範人工智慧有關安全威脅與攻擊。 六、人工智慧所生成之決策對於利害關係人有重大影響,須保障決策過程之公正性。人工智慧研發與應用階段,應致力權衡決策生成之準確性,並提升可讓使用者及受影響者理解其影響及決策過程之可解釋性,兼顧使用者及受影響者權益。爰參考歐盟二○一九年可信賴AI倫理準則(Ethics Guidelines for Trustworthy AI),於第五款定明透明及可解釋性(Transparency and Explainability)之原則。 七、人工智慧研發與應用須公平、完善,且演算法應避免產生偏差或歧視之結果,爰參考美國二○二二年AI權利法案藍圖,於第六款定明公平性原則(Fairness),強調應重視社會多元包容,避免產生偏差與歧視等風險。 八、研發與應用人工智慧應致力於建立人工智慧應用負責機制,以維護社會公益。爰參考新加坡二○二四年生成式AI治理架構(Model AI Governance Framework for Generative AI)有關對於人工智慧開發運用之生命週期中,應確保不同角色(如開發者、部署者、最終使用者等)能承擔相應之責任等精神,於第七款定明可問責性原則(Accountability)。
附錄2 : 2025/12/27 跟歐盟、美國比一比
如果你想深入了解歐盟 AI Act 與台灣基本法的詳細比較,可以參考:EU AI Act vs 台灣人工智慧基本法:兩套治理邏輯,一個企業合規目標
| 面向 | 台灣 AI 基本法 | 歐盟 AI Act | 美國(2025 現況) |
|---|---|---|---|
| 定位 | 基本法(框架法) | 具體執行法規 | 行政命令 + 州法拼圖 |
| 聯邦立法 | ✅ 已通過 | ✅ 已生效 | ❌ 尚無統一聯邦法 |
| Audit Trail | ❌ 無明確要求 | ✅ 高風險 AI 強制要求 | ❌ 無聯邦要求 |
| 罰則 | 未規定 | 最高 €40M 或營收 7% | 視州法而定 |
| 合規邏輯 | 出事 = 你要能交代 | 出事 = 罰款 | 市場自律 + 事後追責 |
| 監管態度 | 原則引導 | 嚴格規範 | 去監管化(Pro-Innovation) |
美國 AI 監管現況(2025 年 12 月)
美國聯邦層面目前沒有統一的 AI 法規,主要靠行政命令和州法:
川普政府立場:
- 2025/1 廢除拜登時期的 AI 安全行政命令
- 2025/12/11 簽署新行政命令,主張建立「國家 AI 政策框架」,試圖限制州政府立 AI 法
- 政策核心:減少監管、促進創新、維持美國 AI 全球領先地位
國會立法進度:
- 眾議院曾提案「10 年 AI 監管暫停期」,被參議院否決
- 目前唯一通過的聯邦 AI 法是 TAKE IT DOWN Act(2025/5),僅針對深偽色情內容
- 尚無廣泛適用的聯邦 AI 監管框架
州法亂象:
- 2025 年全美 50 州提出 1,080+ 項 AI 相關法案
- 僅 118 項成為法律(通過率 11%)
- 各州標準不一,企業合規成本高
一句話總結三地差異:
- 歐盟:Checklist 式合規——告訴你每一步怎麼做,不做就罰
- 台灣:責任式治理——不管你怎麼做,出事要能交代
- 美國:市場自律——政府少管,讓企業自己決定
免責聲明: 本人為 IT 專業背景,並非法律專業人士。本文是以我自己對法條的認知,加上 AI 輔助整理而成,目的是幫助 IT 人理解法規對技術實務的影響。如果你的企業需要正式的合規評估或法律意見,建議還是找適合的法務合作夥伴。
本文基於 2025 年 12 月 23 日通過的《人工智慧基本法》撰寫。後續專法、細則出台後,實務要求可能調整。