美國政府正在成為 AI 模型的 App Store 審核者:從 Fable 5 解封到 GPT-5.6 分階段上線

兩週前政府一紙命令關掉 Fable 5,現在又準備放行。同一時間,GPT-5.6 被要求先給 20 家「可信夥伴」用,再開放大眾。這不是矛盾——這是一套正在成型的新規則:頂尖模型上線前,先過政府這關。
作者: Wisely Chen 日期: 2026 年 6 月 29 日 系列: AI 治理觀察 關鍵字: Fable 5, GPT-5.6, AI Export Control, 分階段發布, AI 治理, OpenAI, Anthropic, 出口管制, 開源模型, GLM-5.2, DeepSeek V4, Qwen 3, Gemma 4, Sakana Fugu, AI Agent, 地端部署
目錄
- 兩件事,同一個邏輯
- Fable 5:從全球關機到「最快下週」解封
- GPT-5.6:還沒上線就被排隊
- 正在成型的模式:政府閘門式發布
- 當 AI 競爭變成國家競爭
- 中國的兩條路:跟進管制,或彎道超車
- Access 本身就是護城河
- 另一條路:強力開源 + 強力編排
- 別只看模型,看制度
兩件事,同一個邏輯
6 月 28 日,Axios 報導川普政府「接近達成協議」恢復 Anthropic Fable 5 的存取,最快下週解封。同一週,傳出 OpenAI 被要求將即將發布的 GPT-5.6 分階段上線——先給大約 20 家「可信夥伴」透過 Amazon Bedrock 使用,再逐步開放。
這兩件事放在一起看,畫面就很清楚了:美國政府正在把自己插入頂尖 AI 模型的發布流程裡。
不是事後監管,不是出事再查。是模型上線之前,政府要先看過、先批准、先決定誰能用。
Fable 5:從全球關機到「最快下週」解封
回顧一下時間線:
| 日期 | 事件 |
|---|---|
| 6/9 | Fable 5 / Mythos 5 正式發布 |
| 6/12 | 美國政府發出出口管制命令,Anthropic 全球關閉存取 |
| 6/26 | 政府允許 Mythos 5 恢復提供給「可信美國機構」 |
| 6/27-28 | Axios 報導 Fable 5 最快下週解封,週末持續協商中 |
整個過程的關鍵轉折:政府的理由是 Fable 5 可以被「越獄」繞過安全措施。Anthropic 的回應很直接——這個能力在其他公開模型上也有,而且「讀 code、修 bug」本來就是工程師的日常。
但爭論技術細節不是重點。重點是結果:政府說關就關、說開就開。 而「開」的方式,不是回到原來的全面開放,是分級——先 Mythos 給可信機構,再談 Fable 5。
Anthropic 沒有公開抗議這個分級邏輯。他們接受了。
GPT-5.6:還沒上線就被排隊
Anthropic 那邊是「先上線再被關」,OpenAI 這邊更直接——GPT-5.6 根本還沒上線,就已經被要求分階段發布。
據報導,川普政府指示 OpenAI 先將 GPT-5.6 提供給大約 20 家「可信夥伴」,透過 Amazon Bedrock 平台,之後再逐步擴大。OpenAI CEO Sam Altman 在內部告知員工:政府要求在安全措施上配合,即使公司內部有不同意見。
同一份報導提到,一項行政命令要求在 60 天內建立「自願性 AI 合作框架」,其中可能包括:政府在公開發布前最多 30 天先行取得頂尖模型的存取權。
30 天。不是看報告、不是聽簡報,是實際拿到模型用。
這已經不是「監管」的範疇了。這更像是政府要求成為每一款頂尖模型的「搶先體驗用戶」,而且有否決權。
正在成型的模式:政府閘門式發布
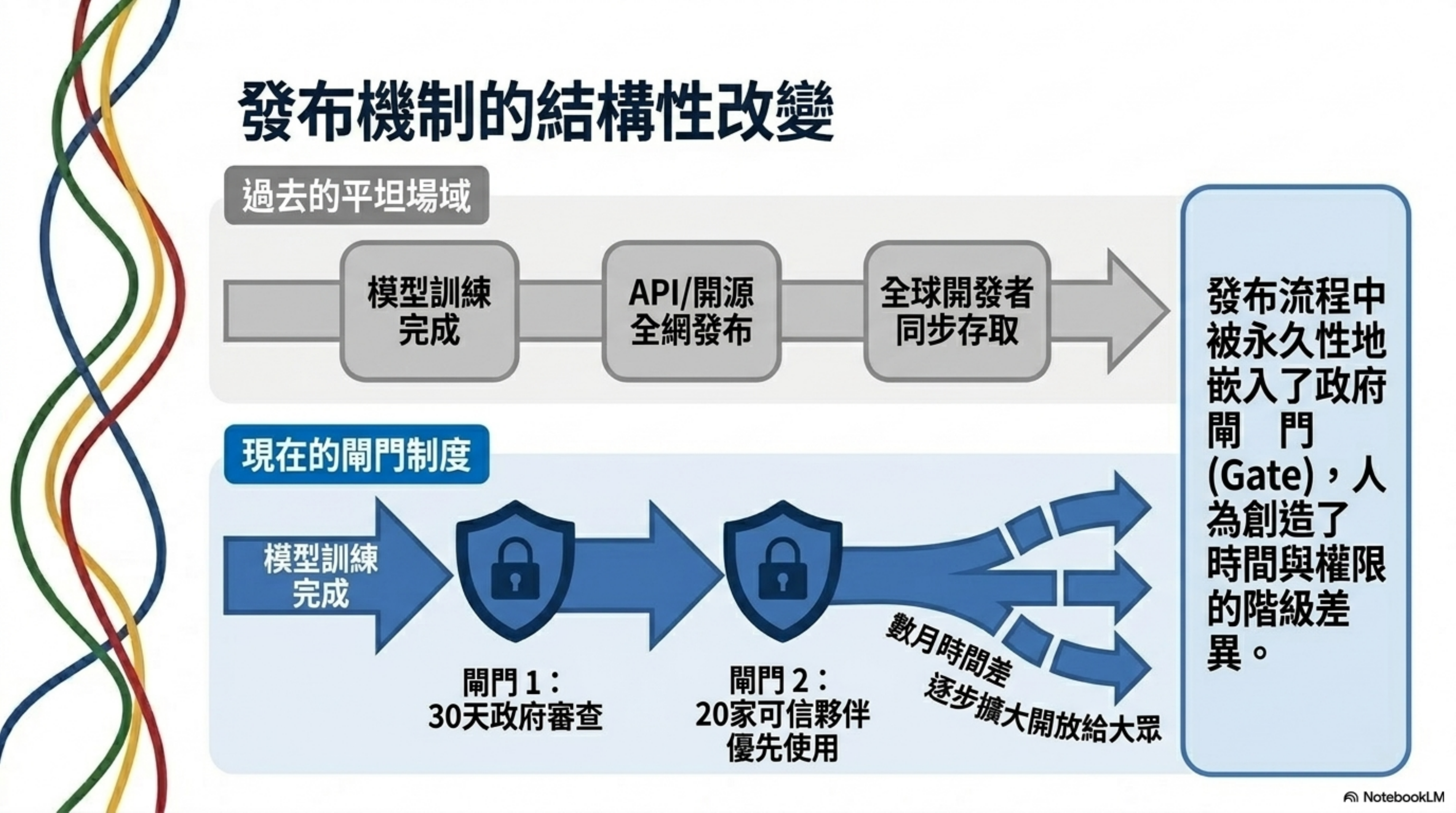
把這些碎片拼起來,一個模式正在浮現:
過去的模型發布流程:
1
公司內部測試 → 安全評估 → 公開發布
正在形成的新流程:
1
公司內部測試 → 安全評估 → 政府預覽(30天)→ 可信夥伴(限定機構)→ 逐步開放
這不是陰謀論,這是兩週內發生的事實拼圖。而且兩家最大的前沿模型公司——Anthropic 和 OpenAI——都在配合。
為什麼配合?除了法律義務,還有一個現實因素:兩家都在準備 IPO,目標估值都是一兆美元。跟政府對著幹,不是上市前你想做的事。
當 AI 競爭變成國家競爭
這件事最大的影響,可能不在技術層面。
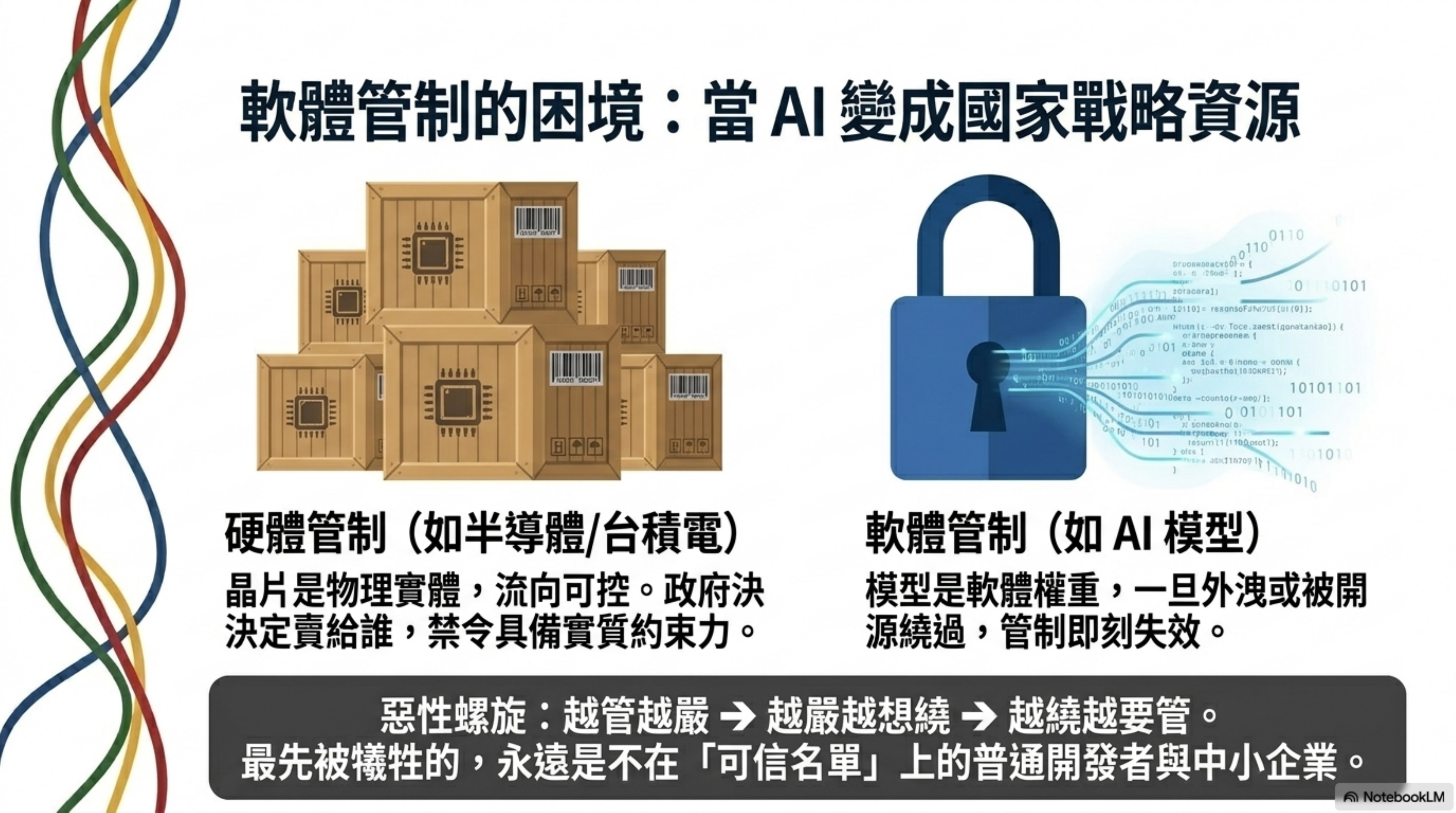
當政府開始決定誰能用、誰先用、誰不能用,AI 的競爭本質就變了。它不再是公司之間的產品競爭,而是國家之間的資源競爭。模型變成了需要「許可證」才能取得的戰略物資,民間組織要進這個遊戲,先得拿到政府的入場券。
這跟半導體產業走過的路一模一樣。台積電、ASML、NVIDIA 的晶片——技術是民間做的,但誰能買、賣給誰,是政府說了算。現在同樣的邏輯正在延伸到軟體模型上。
一個數據值得放在這裡:2025 年 Fortune Global 500 裡,美國企業 138 家,非美國企業 362 家,佔 72%。 這意味著全球最大的 500 家企業裡,超過七成需要排隊等美國政府的分級名單,才能用到最新的閉源前沿模型。這不是小眾問題,這是多數企業的問題。
差別在於:晶片是實體,管制流向至少在物理上可行。模型是軟體,一旦權重外洩,管制就形同虛設。這個矛盾會讓整個制度的執行變得非常扭曲——越管越嚴、越嚴越想繞、越繞越要管。
而在這個螺旋裡,最先被犧牲的,是那些既不在管制名單上、也不在「可信夥伴」名單上的普通開發者和中小企業。
中國的兩條路:跟進管制,或彎道超車
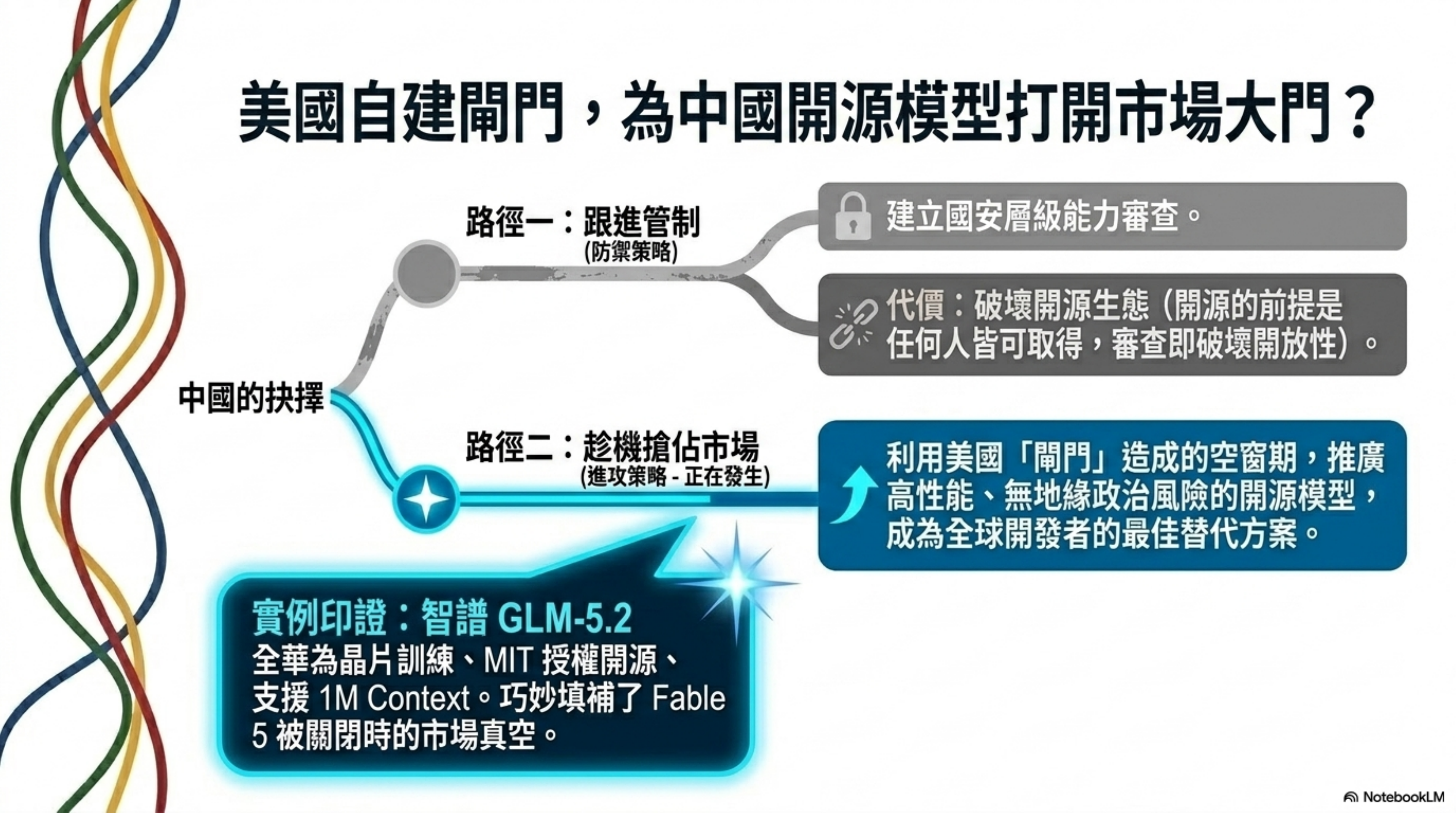
美國這套「閘門式發布」一旦成為常態,中國的反應會是什麼?
第一條路:跟進建立類似機制。
這完全可以預期。如果美國政府可以要求模型先經過審批才能開放,中國沒有理由不做同樣的事。事實上,中國在生成式 AI 領域已經有備案制度——模型上線前要向網信辦備案。只是目前的備案更偏向內容審查,還沒有延伸到「國安層級的能力管制」。
但 Fable 5 事件給了一個現成的參照物。如果中國政府也開始對頂尖開源模型實施類似的能力審查和分級發布,那開源生態可能會受到根本性的衝擊。開源的前提是「任何人都能取得」,一旦政府開始審查誰能取得,開源就只剩下形式上的開放。
第二條路:趁美國自縛手腳,用開源搶市場。
目前來看,中國還沒有對頂尖模型實施美國式的「國安能力管制」。如果這個窗口期持續存在,中國的民間機構——智譜、DeepSeek、阿里通義——很可能會把這當作一個戰略機會。
邏輯很簡單:美國的頂尖模型現在有存取門檻了,全球開發者拿不到、或者晚拿到。這時候如果你是一個性能夠強、完全開源、MIT 授權、沒有地緣政治風險的模型——你就是那些被排除在外的開發者的最佳替代方案。
智譜 GLM-5.2 就是一個典型例子:全華為晶片訓練、MIT 開源、1M context。當 Fable 5 被關掉的那週,GLM-5.2 剛好發布。這個時間點是巧合,但邏輯上的替代關係不是巧合。
美國政府每多加一道閘門,就等於替中國開源模型多打開一扇市場的門。
Access 本身就是護城河
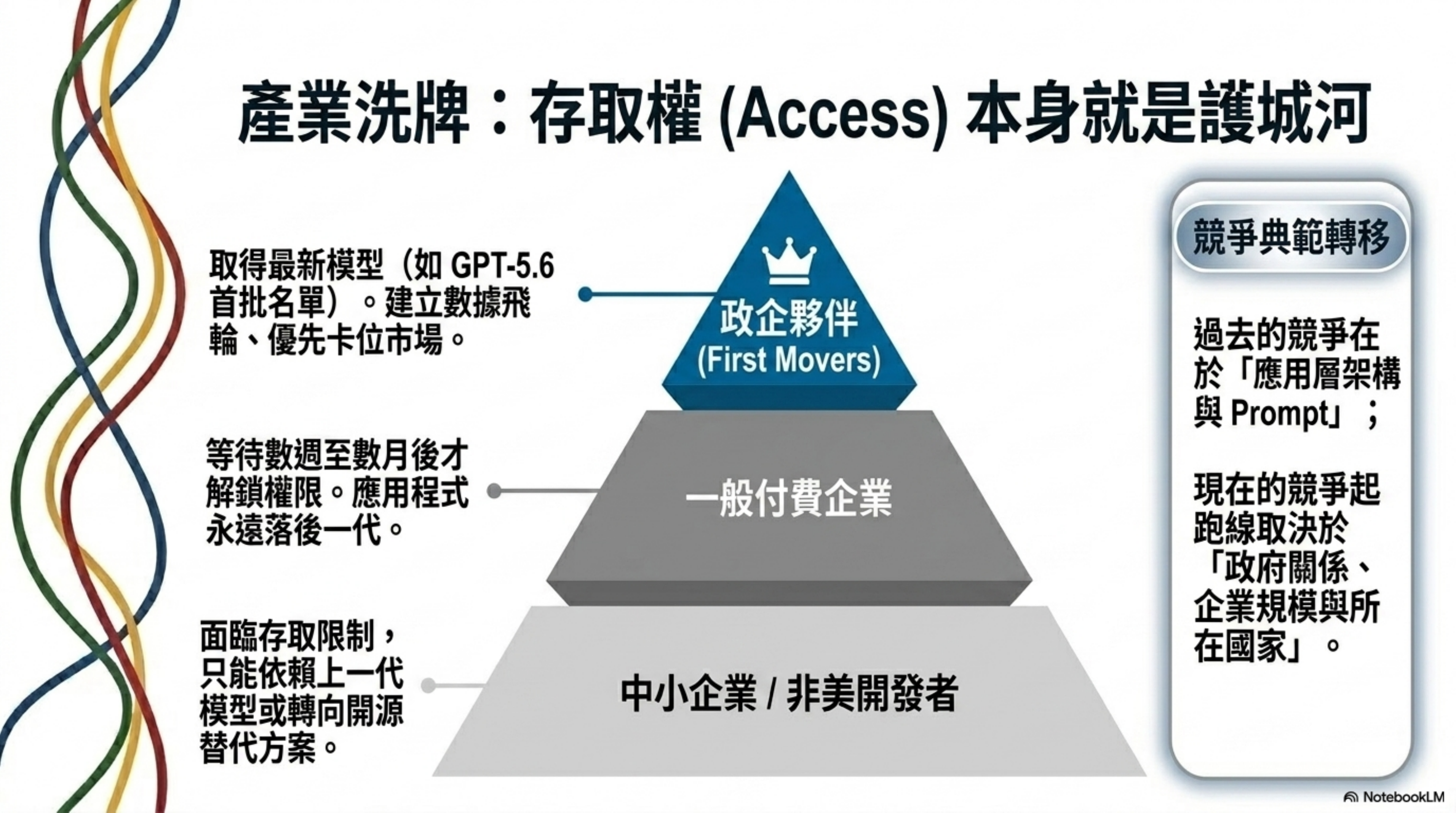
對 AI Agent 的從業者來說,這件事帶來一個非常具體的產業結構變化:「拿得到模型」本身變成了一種競爭優勢。
過去,模型存取不是問題。你有 API key、付得起錢,跟 Google、Anthropic、OpenAI 的 API 是平等的。競爭在應用層——誰的 Agent 架構好、誰的 prompt engineering 精、誰的 RAG pipeline 穩。
現在不一樣了。如果頂尖模型的存取權被分級,那「拿得到 GPT-5.6 第一批權限」的公司,跟「等三個月才拿到」的公司,起跑線就不同。而且這個差距不是你能靠努力追回來的——它取決於你跟政府的關係、你公司的規模、你所在的國家。
這會在 Agent 產業裡形成一種新的資源壁壘:
- 大廠和政府關係好的企業拿到最新模型,用它建產品、建數據飛輪、卡位市場
- 中小企業和非美國開發者只能用上一代模型或開源替代
- 差距隨時間累積,因為每一代新模型都有同樣的「排隊」機制
這跟雲端市場早期的模式很像——AWS 早期客戶拿到的折扣和功能,後來的人永遠追不上。只不過這次的「早期客戶」不是先到先得,是政府指定的。
另一條路:強力開源 + 強力編排
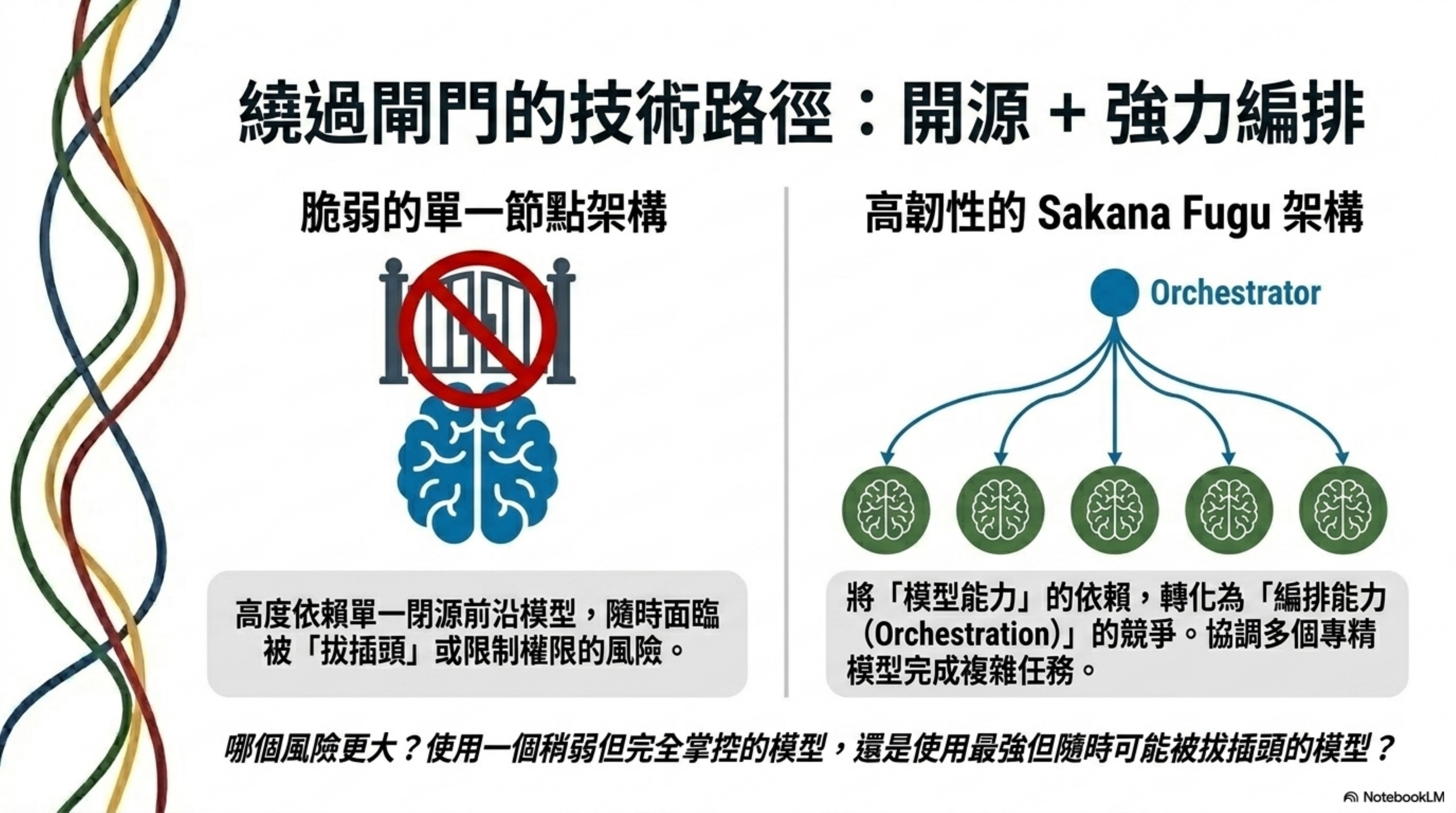
講了這麼多閘門和壁壘,有沒有另一條路?
有。而且已經有人在走了。
Sakana AI 的 Fugu 架構是一個值得關注的方向。Fugu 的核心思路是:不依賴單一頂尖模型,而是用一個強力的編排機制,協調多個較小但專精的模型來完成複雜任務。把「模型能力」的問題轉化成「編排能力」的問題。
這個思路在「閘門式發布」的世界裡,突然變得非常有戰略意義。
如果你的系統架構依賴 Fable 5 或 GPT-5.6,你就受制於政府的分級名單。但如果你的架構是建立在開源模型 + 強力編排之上——比如用 GLM-5.2 這類 MIT 開源、性能夠強的模型,再搭配 Fugu 式的多模型協調機制——你就完全繞過了那道閘門。
沒有人能管制一個開源模型的存取權,因為權重已經在你手上了。
更實際的做法是:現在就投入地端部署,用分層模型策略取代單一頂尖模型依賴。
具體來說,這個架構可以分成三層:
日常任務層:性價比導向的中型模型。 Qwen 3 27B/35B 是目前最佳選擇之一,推理能力強、部署成本低,單張消費級 GPU 就能跑。美系的話 Gemma 4 也是同級別的選項。這一層處理你 80% 的日常 Agent 任務:文件處理、code review、客服對話、資料分析。
高推理層:開源大模型。 當任務需要深度推理——複雜的多步驟規劃、跨文件的架構設計、長鏈條的邏輯推演——就上 GLM-5.2(1M context、MIT 開源)或 DeepSeek V4 這個級別的模型。社群微調的方向也值得關注,比如 Ornith-1.0-397B-FP8 用 FP8 壓縮把 397B 參數量壓到可部署的範圍(我還沒實測過,但這個方向正在快速迭代)。這些模型的推理能力已經逼近閉源前沿,而且完全在你的掌控之下。
編排層:Fugu 式的多模型協調。 最上面用一個強力的編排機制,根據任務複雜度動態分配到不同層的模型。簡單任務走 27B,複雜推理走 GLM-5.2,多模型結果互相驗證。Sakana Fugu 的思路就是這樣——不是找一個萬能模型,而是讓對的模型做對的事。
這套架構的好處很明確:每一層你都有選擇權。 API 和地端不是二選一,而是根據任務性質混搭。追求 throughput 和性價比的日常任務,用 API 跑完全合理——省掉維運成本、彈性擴縮。但關鍵 workload 的穩定性、以及涉及敏感資料的資安任務,就該放在你自己的機房裡,用開源模型跑。重點不是「全部自建」,而是確保你的關鍵路徑上,至少有一層不依賴任何外部許可。 而且因為是分層設計,單一模型被替換或升級的時候,不會影響整個系統。
當然,這條路也有代價:地端部署需要 GPU 投資,編排機制增加系統複雜度,整體性能在最頂尖任務上跟閉源前沿還有差距。但這個差距正在快速縮小——半年前開源模型跟 GPT-4 的差距是一個等級,現在 Qwen 3、GLM-5.2、DeepSeek V4 已經在多數場景追到可用甚至持平。而閘門帶來的不確定性卻在快速放大。
哪個風險更大——用一套稍弱但你完全掌控的開源模型組合,還是用一個最強但隨時可能被關掉的閉源模型?
對很多 production 環境來說,答案已經不像半年前那麼明顯了。
別只看模型,看制度

兩週前我寫 Fable 5 事件時,最擔心的是「個案命令式管理」——沒有明確紅線、沒有標準程序、一封信就全球關機。
現在的發展,某種程度上比那時好一點,也壞一點。
好的部分:政府顯然在試圖建立某種框架。「60 天內建立自願性合作機制」「30 天預覽期」「可信夥伴分級」——這些至少是制度化的嘗試,不再是純粹的個案命令。
壞的部分:這個框架的方向,是把政府永久性地嵌入模型發布流程。不是危機處理,是常態機制。而且「自願性」這三個字,在 Fable 5 被關掉的背景下,大家都知道是什麼意思。
更深層的問題是:誰來決定「可信夥伴」是誰?用什麼標準?名單透不透明?落選的人有沒有申訴管道?
這些問題現在都沒有答案。而在沒有答案的情況下,不確定性本身就是成本。
頂尖 AI 模型的發布,正在從「技術就緒就上線」變成「技術就緒、政府批准、分級開放」。
這個變化會不會成為常態?看看兩家市值目標一兆美元的公司都在配合,答案大概已經很清楚了。
對我們這些用模型的人來說,與其花時間猜哪個模型最強,不如花時間想清楚兩件事:
第一,當你最依賴的模型被暫停存取時,你的系統還能不能跑。
第二,你有沒有一條不依賴任何單一政府許可的技術路線。
第一件事是防守,第二件事是佈局。兩件都做,才不會在下一次「一紙命令」來的時候,只能等。
附錄:Sakana Fugu 是什麼?
文章裡多次提到「Fugu 式的編排」,這裡補充說明一下這個架構到底在做什麼。
Sakana Fugu 是日本 Sakana AI 在 2026 年 6 月發布的多模型編排系統。它不是一個傳統意義上的模型——不是訓練出來的單一大模型,也不是 MoE 架構。它的核心是一個用強化學習訓練出來的 Conductor(指揮者)模型,負責把任務動態分配給一組 LLM 池裡的不同模型。
架構基於 Sakana AI 的兩篇 ICLR 2026 論文:
- TRINITY:把模型池裡的不同 LLM 分配成 Thinker(思考者)、Worker(執行者)、Verifier(驗證者)三種角色,多輪協作完成任務
- Conductor:用強化學習訓練指揮模型,讓它自己學會怎麼分配任務、選哪個模型、用什麼 prompt 協調——而不是靠人工寫死的路由規則
對外就是一個 OpenAI 相容的 API。你呼叫一次,內部 Conductor 自動決定啟動哪些模型、分配什麼角色、怎麼合成最終回覆。使用者不需要知道後面跑了幾個模型。
一個重要的區分: Fugu 目前編排的對象是閉源前沿模型(GPT-5.5、Claude Opus、Gemini 3.1 Pro)。本文提到「用 Fugu 式的編排搭配開源模型」,是把這個「學習式多模型協調」的思路延伸到開源場景——如果同樣的 Conductor 架構可以指揮閉源前沿模型拿到超越單一模型的表現,那把它套用在 GLM-5.2、Qwen 3、DeepSeek V4 這些開源模型上,理論上也能從「多個夠強的模型協作」中榨出接近前沿的表現,同時保有完全的自主掌控。
這個方向值得關注的原因很簡單:它把競爭從「誰有最強的單一模型」轉移到「誰有最好的編排能力」。 在閘門式發布的世界裡,後者比前者更可控。