On-Premise Enterprise LLM Deployment:企業級地端 LLM 架構完整藍圖

目錄
- 為什麼企業需要地端 LLM 架構?
- On-Prem vs Cloud:企業該怎麼選?
- Auth Gateway:企業地端 LLM 為什麼一定要做?
- Orchestrator:多步驟任務的協調中心
- Python 沙盒:LLM 生成程式碼的安全執行環境
- 檔案版本管理
- LLM Router:智慧模型選擇與負載平衡
- Log 系統:LLM 觀測與效能監控
- AI 記憶層:讓 Agent 從經驗中學習
- 結論
- 常見問題 Q&A
- 延伸閱讀
為什麼企業需要地端 LLM 架構?
Enterprise local LLM architecture(企業級地端 LLM 架構)不只是「把模型跑起來」這麼簡單。這又一篇”無聊 IT 架構” 系列文。講到地端 LLM,大家都在討論怎麼榨出更好的 performance:用什麼量化、跑什麼模型、GPU 要買哪張。但真正要上生產環境,其實有一堆東西要顧:
- 多人同時使用,怎麼管理權限?
- 使用者問了什麼、LLM 回了什麼,怎麼記錄和審計?
- Python 執行環境怎麼防止惡意程式碼?
- 有多個 LLM 模型,怎麼智慧選擇和切換?
這篇文章就是在講這些「無聊但必要」的基礎建設。正如 SaM Solutions 的定義:企業級 LLM 架構是「讓大公司以安全、高效且符合業務目標的方式使用、管理和擴展大型語言模型的結構化框架」——重點不在模型本身,而在圍繞模型的完整技術堆疊。
這張藍圖是我們接下來的導覽地圖。先看整體流程:
Step 1:使用者登入上傳 — 使用者透過瀏覽器或 CLI 發送請求,上傳 Excel/CSV 檔案(若是 PDF/圖片,則需整合地端 OCR API 進行視覺辨識與解析)
Step 2:Auth Gateway 驗證權限 — 檢查身份、角色、配額,決定能用哪個模型、查哪些資料
Step 3:Orchestrator 協調任務 — 把「分析銷售報表」這種複雜請求拆成多個步驟
Step 4:LLM 生成程式碼 — 透過 LLM Router 選擇合適模型,生成 Python 分析程式碼
Step 5:Python 沙盒執行 — 在隔離環境跑程式碼,讀取檔案、執行分析、回傳結果
Step 6:結果回傳與日誌記錄 — 把結果傳回使用者,同時記錄到 Log 系統
On-Prem vs Cloud:企業該怎麼選?
On-premise LLM architecture 的核心價值是資料主權。每個客戶都在說地端,因為適合企業內部部署,資料完全不出內網。根據 Allganize 的企業部署指南,選擇地端部署的關鍵考量包括:安全性、可用性、客製化程度與長期成本。根據實際接觸的客戶經驗,金融、製造、醫療等產業對資料主權的要求非常嚴格——即使雲端廠商提供再多的合規認證,IT 部門和法務還是會說:「資料不出公司網路,我們才安心。」這不是技術問題,是信任問題。
核心元件
GPU 伺服器
- 角色:執行 Ollama + Open Source Model List
- 建議規格:Nvidia 顯示卡
應用伺服器
- 角色:Python 程式碼執行、API 服務
- 建議規格:8 核 CPU,32GB RAM
檔案伺服器
- 角色:存放 Excel/CSV 原始檔案
- 建議規格:NAS 或 SMB 共享
優缺點
優點
- 資料完全不出內網,符合金融/醫療合規要求
- 無 API 費用,長期成本可控
- 可審計所有 LLM 生成的程式碼
缺點
- 需要購置 GPU 硬體(約 10-50 萬台幣)
- 維護成本(系統管理、模型更新)
- 推理速度較雲端慢
Auth Gateway:企業地端 LLM 為什麼一定要做?
企業 LLM 系統的第一道防線就是 Auth Gateway。
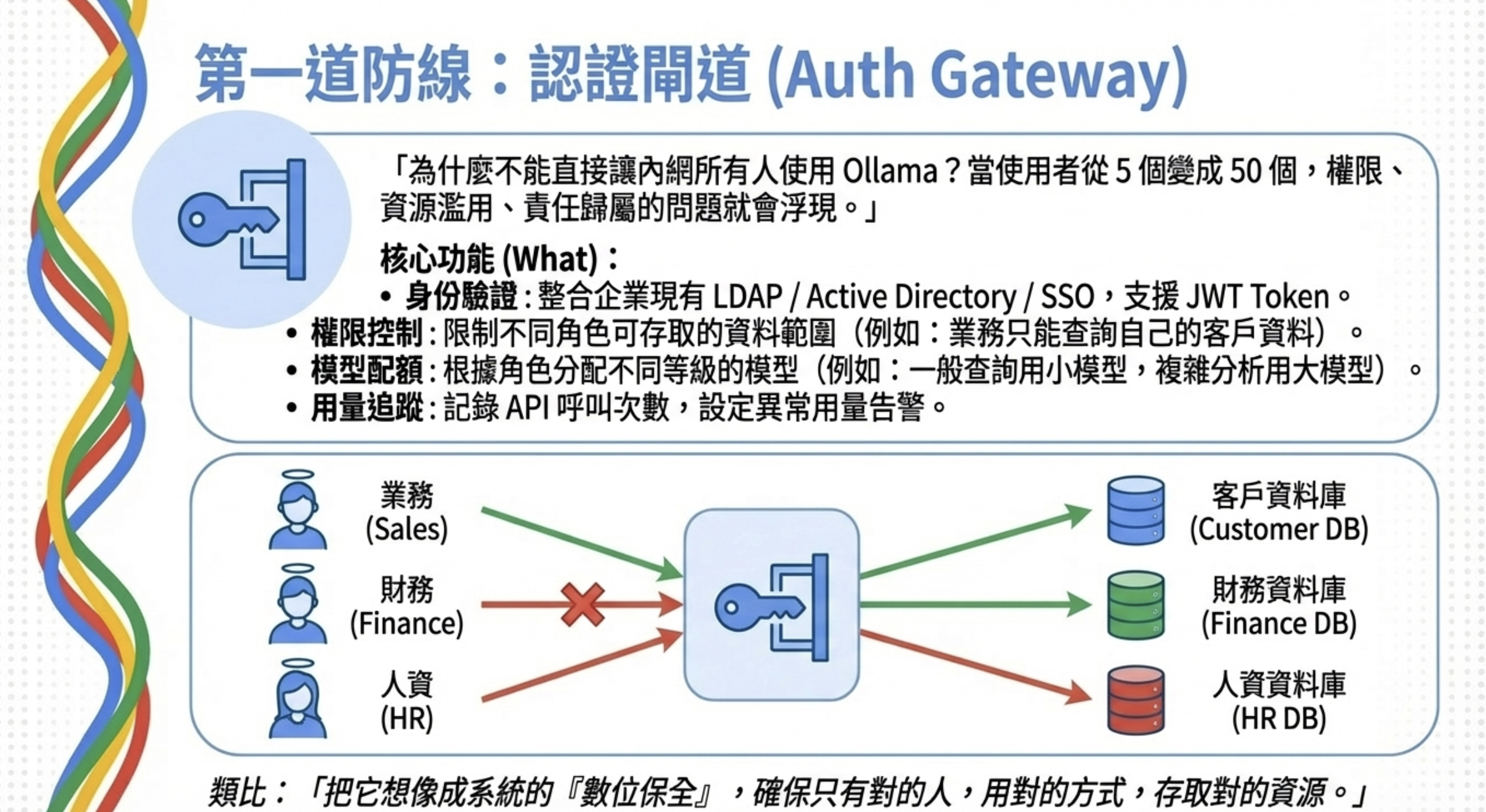
為什麼需要 Auth Gateway?
很多人第一次架 LLM 服務,直接把 Ollama 開放給內網所有人用——反正都是自己人嘛。但當使用者從 5 個變成 50 個,問題就來了:
- 誰在用? 財務部的人能不能查人資的薪資資料?
- 用多少? 有人狂刷 API,GPU 被吃光,其他人沒得用
- 出事誰負責? 資料外洩時,連是誰查的都不知道
Auth Gateway 就是解決這些問題的第一道防線。為什麼我們需要這麼嚴格的權限控制?因為 AI Agent 面臨著傳統 WAF 無法防禦的威脅——詳細攻擊案例請見:AI Agent 安全性:揭露傳統資安工具看不到的盲區。
核心功能
身份驗證
- 整合企業現有的 LDAP / Active Directory / SSO
- 支援 JWT Token,方便與現有系統串接
權限控制
- 限制不同角色可存取的資料範圍
- 例如:業務只能查自己負責的客戶資料
模型配額
- 不同角色分配不同等級的模型
- 一般查詢用小模型(省 GPU),複雜分析才用大模型
用量追蹤
- 記錄每位使用者的 API 呼叫次數
- 異常用量自動告警
💡 延伸閱讀: 為什麼傳統防火牆擋不住 AI?想了解 Prompt Injection 等新型態攻擊手法,請參考:AI Agent Security:為什麼它正在改變企業資安架構
Orchestrator:多步驟任務的協調中心
當 LLM 從「單一問答」進化到「多步驟任務」,就需要 Orchestrator 來協調。
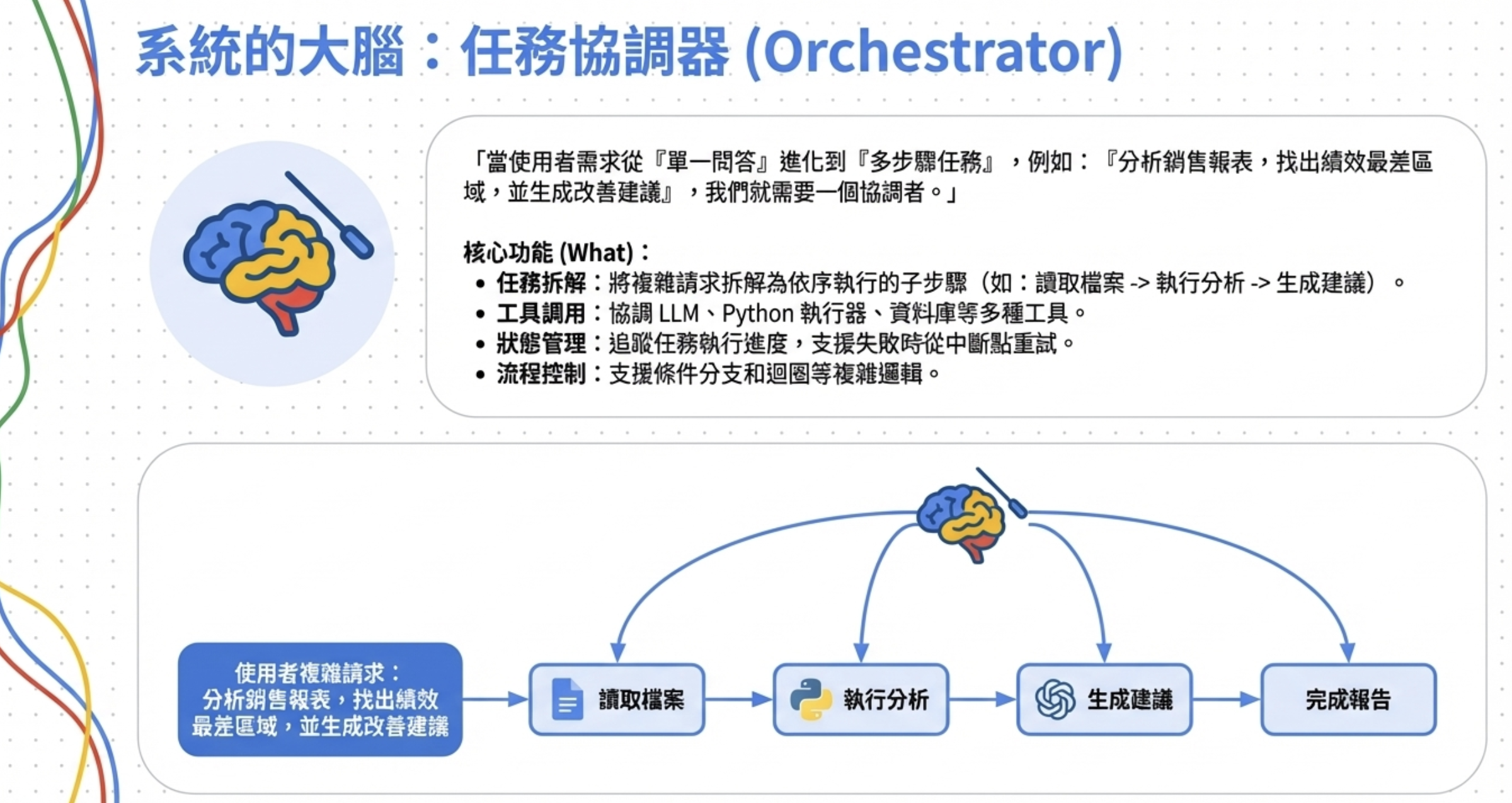
為什麼需要 Orchestrator?
當 LLM 應用從「單一問答」進化到「多步驟任務」,你會發現光靠 LLM 本身不夠用了。
舉個例子:使用者問「幫我分析上個月的銷售報表,找出業績最差的三個區域,並生成改善建議」。這個任務需要:
- 讀取 Excel 檔案
- 在沙盒裡跑 Python 做資料分析
- 呼叫 LLM 生成改善建議
- 把結果整理成報告
這種多步驟、有依賴關係的任務,就需要一個 Orchestrator 來協調。
核心功能
- 任務拆解 — 把複雜任務拆成多個子步驟,定義依賴關係
- 工具調用 — 協調 LLM、Python 執行器、資料庫等工具
- 狀態管理 — 追蹤執行狀態,失敗時可從中斷點重試
- 流程控制 — 支援條件分支和迴圈
實作上,我們不需要從頭寫一個 Orchestrator。透過 Low-Code 自動化工具,可以快速實現上述的任務拆解與流程控制。
💡 實作範例: n8n 雲地混合架構:為什麼它不只是一個 Low-Code 工具
Python 沙盒:LLM 生成程式碼的安全執行環境
Python 沙盒是企業 LLM 系統的安全關鍵——讓 AI 生成的程式碼跑得動,又不會搞壞系統。

為什麼用 Python 而不是直接讓 LLM 分析?
很多人第一直覺是:「直接把 Excel 丟給 LLM 分析不就好了?」
實務上這樣做有兩個大問題:
- 容易產生幻覺 — LLM 看到一堆數字,很容易「腦補」出不存在的規律或錯誤的加總結果
- Token 數爆炸 — 一個 10 萬行的 Excel,光是轉成文字就超過大部分模型的 context window,而且處理速度極慢
更好的做法是:讓 LLM 先看資料的「長相」(欄位名稱、前幾行樣本),然後生成 Python 程式碼去做實際的資料分析。Python 跑數字運算又快又準確,LLM 負責的是「理解需求、生成程式碼」這件事。
為什麼需要沙盒?
既然要執行 LLM 生成的程式碼,就必須考慮安全性。LLM 生成的程式碼可能包含:
- 惡意操作:刪除系統檔案
- 資料外洩:將資料傳送到外部伺服器
- 無限迴圈:造成系統資源耗盡
- 記憶體爆炸:分配過大的記憶體
技術選項
| 方案 | 隔離等級 | 實作複雜度 | 適用場景 |
|---|---|---|---|
| exec() 限制 | ⭐ 低 | 簡單 | 內部可信環境、PoC |
| RestrictedPython | ⭐⭐ 中 | 中等 | 限制危險操作 |
| Docker 容器 | ⭐⭐⭐ 高 | 中等 | 生產環境推薦 |
| gVisor / Firecracker | ⭐⭐⭐⭐ 極高 | 複雜 | 多租戶、公開服務 |
生產環境建議使用 Docker 容器,可設定:
- 記憶體限制(如 512MB)
- CPU 限制(如 50%)
- 禁止網路存取
- 執行超時(如 30 秒)
這種隔離策略也符合 OWASP LLM Top 10 中對 LLM08: Excessive Agency 的防護建議——限制 LLM 生成程式碼的執行權限。關於 AI Agent 時代的資安威脅,可參考 AI Agent Security:為什麼它正在改變企業資安架構。
檔案版本管理
為什麼需要記錄互動過的檔案?
使用者上傳一個 Excel 問「幫我分析這份報表」,LLM 生成程式碼、執行完畢、回傳結果。一週後,使用者說:「上次那個分析結果怪怪的,可以幫我看一下嗎?」
這時候問題來了:
- 原始檔案還在嗎?使用者可能已經修改或刪除了
- 當時用的是哪個版本的檔案?
- LLM 生成的程式碼還能找到嗎?
如果沒有檔案版本管理,這些問題都很難回答。
建議的儲存策略
原始檔案保存
- 每次上傳的檔案都保存一份副本
- 用 Session ID + 時間戳記命名,避免覆蓋
- 設定保留期限(如 90 天),自動清理過期檔案
中間產物保存
- LLM 生成的程式碼
- Python 執行的輸出結果
- 錯誤訊息和 stack trace
檔案索引
- 在 PostgreSQL 中記錄檔案的 metadata(檔名、大小、hash、儲存路徑)
- 與對話日誌關聯,方便回溯
儲存位置選擇
- NAS / SMB 共享 — 簡單直接,適合小規模部署
- MinIO — 開源的 S3 相容物件儲存,適合需要版本控制的場景
- 本地磁碟 + 定期備份 — 最簡單,但要注意磁碟空間管理
重點是:讓每次互動都可以被完整重現。這對於除錯、審計、甚至後續的模型優化都非常有價值。這也是台灣《人工智慧基本法》中「透明及可解釋性」與「可問責性」原則的技術實踐。
LLM Router:智慧模型選擇與負載平衡
LLM Router 的核心價值是讓對的模型做對的事,同時節省 GPU 資源。

為什麼需要 LLM Router?
一個常見的誤解是:「我們公司只需要一個模型就夠了。」
實際上,不同任務需要不同等級的模型。用 14B 模型來做簡單的欄位加總,就像開卡車去便利商店買牛奶——能到,但浪費資源。反過來,用 7B 小模型處理複雜的多表關聯分析,結果往往不如預期。
LLM Router 的核心價值是讓對的模型做對的事。
核心功能
模型路由
- 根據任務複雜度自動選擇模型
- 簡單查詢走小模型(快、省資源),複雜分析走大模型
負載平衡
- 多 GPU 環境時分散請求
- 避免單一 GPU 過載
Fallback 備援
- 主模型失敗或超時,自動切換備援模型
- 提高服務穩定性
統一 API
- 對應用層隱藏底層模型差異
- 換模型不需要改程式碼
為什麼推薦 LiteLLM?
當你有多個模型來源(地端 Ollama、OpenAI、Anthropic),每個 API 格式都不一樣,應用程式要寫一堆 if-else 來處理,維護起來很痛苦。
LiteLLM 解決的就是這個問題:
- 統一 API 介面 — 不管後端是什麼模型,前端都用 OpenAI 相容格式呼叫
- 一行換模型 — 改設定檔就能切換模型,不需要改程式碼
- 內建負載平衡 — 多個模型來源自動分流
- 用量追蹤 — 記錄每個請求的 token 數、延遲、成本
簡單講,LiteLLM 就是讓你的應用程式不需要知道後面跑的是哪個模型,專心做業務邏輯就好。
Log 系統:LLM 觀測與效能監控
企業 LLM 系統需要完整的觀測能力,才能持續優化和除錯。

為什麼推薦 Langfuse?
Langfuse 是目前最成熟的開源 LLM 觀測平台,專注在 LLM 呼叫的觀測:
- Token 數、延遲、成本追蹤 — 知道每次呼叫花了多少錢
- Prompt 版本管理 — A/B 測試不同的 prompt
- 模型效能比較 — 哪個模型在什麼任務上表現更好
- Trace 追蹤 — 完整記錄一次請求的所有 LLM 呼叫
這是「LLM 效能監控」的標準解法,5 分鐘就能用 Docker 部署完成。
AI 記憶層:讓 Agent 從經驗中學習
當 AI Agent 開始處理複雜的多步驟任務,光有 Log 系統是不夠的。

Log vs 記憶:給人看 vs 給 AI 用
| 系統 | 記錄內容 | 用途 |
|---|---|---|
| Langfuse Log | Token 數、延遲、成本、Trace | 效能監控、成本控制 |
| AI 記憶層 | 決策理由、嘗試過的方案、學到的教訓 | 持續學習、錯誤避免、行為追溯 |
Langfuse 回答的是「這次呼叫花了多少 token」,但 AI 記憶層回答的是「為什麼 Agent 會做出這個決定」。
為什麼需要 AI 記憶層?
很多人把 LLM 當成「問一次、答一次」的工具。但當系統開始處理複雜任務,問題就來了:
- 這個 Agent 之前試過哪些方案?
- 為什麼上次會做出那個判斷?
- 三週前的錯誤,是不是又被重複犯了一次?
這些問題,Log 系統回答不了。你需要的是一個「AI 的行為歷史資料庫」。
記憶層的四種操作模式
AI 記憶層不只是 RAG 的 Vector Store,它支援四種不同的操作模式:
| 操作模式 | 說明 | 應用場景 |
|---|---|---|
| RAG(讀取記憶) | 查詢相關的歷史資訊 | 回答問題時參考過去經驗 |
| Agent Reflection(寫入記憶) | 記錄決策過程與理由 | 每次任務完成後的自我反思 |
| Feedback Loop(更新記憶) | 根據結果修正記憶 | 使用者回饋後調整判斷 |
| Failure Analysis(重放記憶) | 回溯錯誤發生的脈絡 | 除錯、審計、持續改進 |
簡單講:RAG 只是記憶的「讀取」模式,完整的記憶系統還需要寫入、更新、重放。
記憶層要存什麼?
一個完整的 AI 記憶層,至少要包含:
- 原始內容 — 可讀、可審計的文字
- Embedding 向量 — 語意搜尋用
- 決策追蹤 — 為什麼這樣選、信心度多少
- 時間軸 — 先後順序、版本回溯
- Metadata — 任務 ID、Agent ID、來源
這不只是存向量,而是存 AI 的「行為歷史」。
為什麼我選 PostgreSQL + pgvector?
在評估過專用 Vector DB(Pinecone、Qdrant、Milvus)後,我選擇 PostgreSQL 作為記憶底座。核心原因:
- 向量 + 結構化查詢 — 一個 SQL 搞定「過去一週這個 Agent 犯過的類似錯誤」
- Row-Level Security — 記憶內容可能含機密,資料庫層級的權限隔離更安全
- ACID 保證 — 記憶的寫入、更新、刪除是原子操作
- 治理能力 — 審計追蹤、版本回溯、GDPR 刪除權
PostgreSQL vs 專用 Vector DB
| 面向 | PostgreSQL + pgvector | 專用 Vector DB |
|---|---|---|
| 向量搜尋 | ✅ 支援(百萬級夠用) | ✅ 更強(億級) |
| 結構化查詢 | ✅ 原生 SQL | ⚠️ 有限 |
| ACID 交易 | ✅ 原生支援 | ❌ 通常不支援 |
| Row-Level Security | ✅ 資料庫層級 | ❌ 需應用層補 |
| 與業務資料 JOIN | ✅ 直接 JOIN | ❌ 需同步資料 |
結論: 80% 的企業 AI 專案,瓶頸不在向量搜尋速度,而在於「出事時能不能解釋」。PostgreSQL 的治理能力是專用 Vector DB 很難比的。
💡 延伸閱讀: 詳細的 Schema 設計、查詢範例、RLS 權限控制實作,請參考:PostgreSQL 作為 AI 記憶庫:為什麼我選它而不是專用 Vector DB
結論
Enterprise LLM deployment 不只是「把模型跑起來」這麼簡單。你需要考慮:
- Auth Gateway: 誰能用什麼模型、查什麼資料
- LLM Router: 根據任務複雜度選擇模型,節省資源
- Python 沙盒: 防止惡意程式碼破壞系統
- Langfuse 觀測: 審計追蹤、除錯排查、用量分析(開源可自建)
- AI 記憶層: 讓 Agent 從過去經驗學習,避免重複錯誤
這些基礎建設看起來繁瑣,但一旦建好,後續的開發和維護會輕鬆很多。
常見問題 Q&A
Q: 地端 vs 雲端的成本怎麼比較?
地端前期投資較高(GPU 硬體約 10-50 萬台幣),但沒有 API 費用。如果每月 LLM 呼叫量大(例如超過 100 萬 token/天),地端約 6-12 個月可回本。雲端適合前期驗證或用量不穩定的場景。
Q: 為什麼選 Ollama / LiteLLM / Langfuse 這個組合?
三個都是開源、可自建、社群活躍。Ollama 讓地端模型部署變得像裝 App 一樣簡單;LiteLLM 統一了不同模型的 API 格式,換模型不用改程式;Langfuse 是目前最成熟的開源 LLM 觀測平台,5 分鐘就能 Docker 部署。
Q: 多少人使用才需要這套架構?
5 人以下可以先用簡單的方式(直接開放 Ollama)。超過 10 人就建議加上 Auth Gateway 做權限控制。超過 50 人或有合規需求(金融/醫療),完整架構就是必要的。
Q: Python 沙盒真的能防住所有攻擊嗎?
沒有 100% 安全的系統。Docker 容器能擋住大部分常見攻擊(刪檔案、網路外傳、資源耗盡),但如果是針對性的容器逃逸攻擊,還是需要更高級的隔離方案(如 gVisor)。重點是:風險與成本的平衡,內部系統用 Docker 通常夠用。
延伸閱讀
工具與平台
- Ollama - 地端 LLM 部署的瑞士刀
- LiteLLM 官方文檔 - 統一 LLM API 閘道
- Langfuse 官方文檔 - 開源 LLM 觀測平台
- Langfuse 自建指南 - 5 分鐘 Docker 部署
- PostgreSQL 作為 AI 記憶庫 - 為什麼選 PostgreSQL 而不是專用 Vector DB
安全與治理
- CaMeL Agent 架構落地 PostgreSQL:用 RLS 設計不可繞過的 AI Memory 與權限隔離 - 將 Google DeepMind 的 CaMeL 架構實作到資料庫層
- 台灣《人工智慧基本法》:IT 主管必讀的 AI 資安治理建議 - 七大原則解讀、Quick Win 清單與企業合規方向
- AI Agent Security:為什麼它正在改變企業資安架構 - 從 Salesforce ForcedLeak 到 Microsoft 365 Copilot EchoLeak 的真實案例分析
- OWASP LLM Top 10 - LLM 應用的十大安全風險
- NIST AI Risk Management Framework - AI 風險管理的國際標準
- Docker Security Best Practices - 容器安全配置指南