Moltbot 安全加固實戰:AI Agent 四層縱深防禦完整指南

Security Hardening · Prompt Injection Defense · Rollback · Isolation
作者: Wisely Chen 日期: 2026 年 1 月 系列: AI Agent Security 實戰觀察 關鍵字: AI Agent Security, Prompt Injection, LLM Agent Security, Agentic Security, Security Hardening
目錄
- 背景:為什麼 Moltbot 需要 Security Hardening?
- AI Agent Security Framework:四層縱深防禦
- 第一層 Isolation:限制爆炸半徑
- 第二層 Quarantine:Prompt Injection Defense
- 第三層 Rollback:損害復原機制
- 第四層 Transparency:早期預警系統
- 讓 Moltbot 幫你做這件事
- 常見問題 Q&A
- 這篇文章適合誰?
- 延伸閱讀
關於改名
本文原標題為「Moltbot 安全加固實戰」。2026 年 1 月,Anthropic 以商標侵權為由,要求開發者將 Moltbot 改名。創作者 Peter Steinberger 表示:「我是被 Anthropic 強迫改名的,這不是我的決定。」
新名稱 Moltbot(吉祥物 Molty)延續龍蝦主題——「molt」指龍蝦蛻殼成長。本文已全面更新為新名稱。
參考來源:Business Insider 報導
背景:為什麼 Moltbot 需要 Security Hardening?
前篇文章 500 台 AI 助理裸奔公網:Moltbot Security Disaster 與預設安全風險 揭露了 Moltbot 的預設配置災難。這篇是續集 — 從問題到解決方案。
這篇文章整理自 Moltbot 社群的實戰經驗。有趣的是:你可以讓 Moltbot 幫你加固 Moltbot 的安全。
AI Agent Security Framework:Moltbot 四層縱深防禦
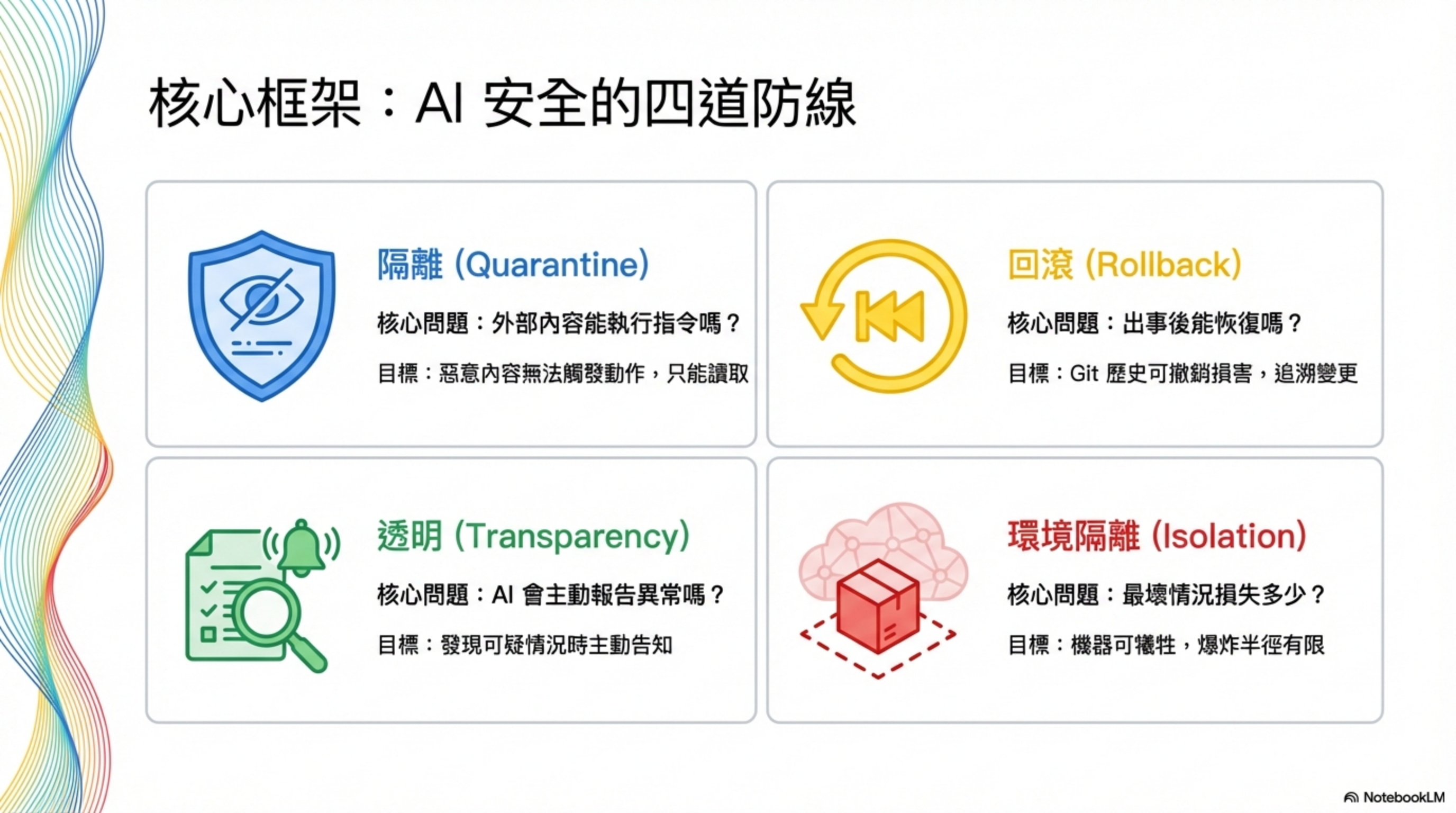
在開始實作之前,先理解整體防禦思路。AI Agent Security 不是單點防護,而是四層縱深防禦:
| 層次 | 目標 | 核心問題 |
|---|---|---|
| Isolation(爆炸半徑) | 機器可犧牲,出事影響有限 | 如果被攻破,損失多大? |
| Quarantine(內容隔離) | 惡意內容無法觸發動作,只能讀取 | 外部輸入能做什麼? |
| Rollback(回滾能力) | Git 歷史可撤銷損害,追溯變更時間點 | 出事後能復原嗎? |
| Transparency(透明告知) | AI 發現可疑情況時主動告知 | 能及早發現問題嗎? |
這四層不是選擇題,是同時需要的。缺少任何一層,其他三層的效果都會大打折扣。
以下按照這四個層次,逐一說明具體實作。
第一層 Isolation:限制 AI Agent 被入侵時的爆炸半徑
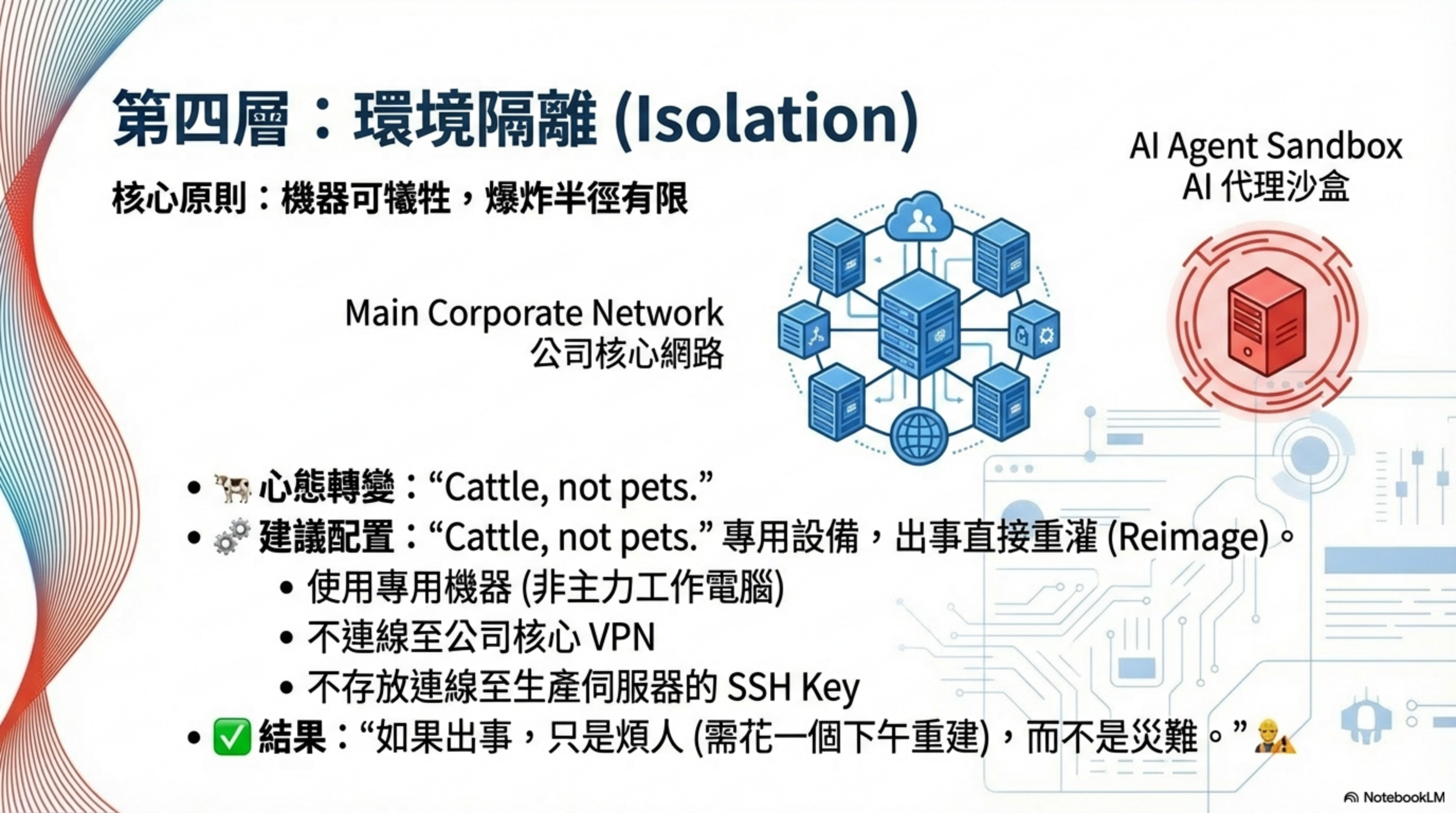
核心問題:如果被攻破,損失多大?
這一層的目標是讓最壞情況變成「煩人但不是災難」。AI Agent Isolation 是 Security Hardening 的第一道防線。
1.1 可犧牲的基礎設施
心態轉變:專用設備,出事直接重灌。
建議配置:
- 專用機器(不是主力電腦)
- 不連公司 VPN
- 沒有 SSH Key 到生產伺服器
- 沒有任何不能在一個下午重建的東西
結果: 如果出事,煩人但不是災難。
1.2 檢查 Gateway 是否暴露
這一步救了 923 個人。
檢查指令:
1
moltbot config get | grep bind
判斷標準:
"bind": "all"→ 對整個網路開放,任何人都能連 ❌"bind": "loopback"→ 只監聽 localhost ✓
修復方式:
- 改成
"bind": "loopback" - 重啟服務
更新:Moltbot 官方已修補此漏洞,請確保使用最新版本。
1.3 密鑰管理
核心原則:密鑰永遠不存在設定檔裡。
安裝 Bitwarden CLI:
1
2
3
brew install bitwarden-cli
bw login
mkdir ~/.secrets && chmod 700 ~/.secrets
使用規則:
- 需要時取出,用完即焚
- 永遠不 echo 密鑰
- 永遠不存到檔案
- 永遠不在對話中顯示
為什麼這屬於 Isolation?
密鑰管理的核心不是「保護密鑰」,而是限制密鑰外洩時的影響範圍:
- 密鑰不在檔案裡 → 檔案被偷也沒用
- 用完即焚 → 記憶體攻擊的窗口期縮短
- 不 echo → 日誌不會記錄
第二層 Quarantine:Prompt Injection Defense 與內容隔離
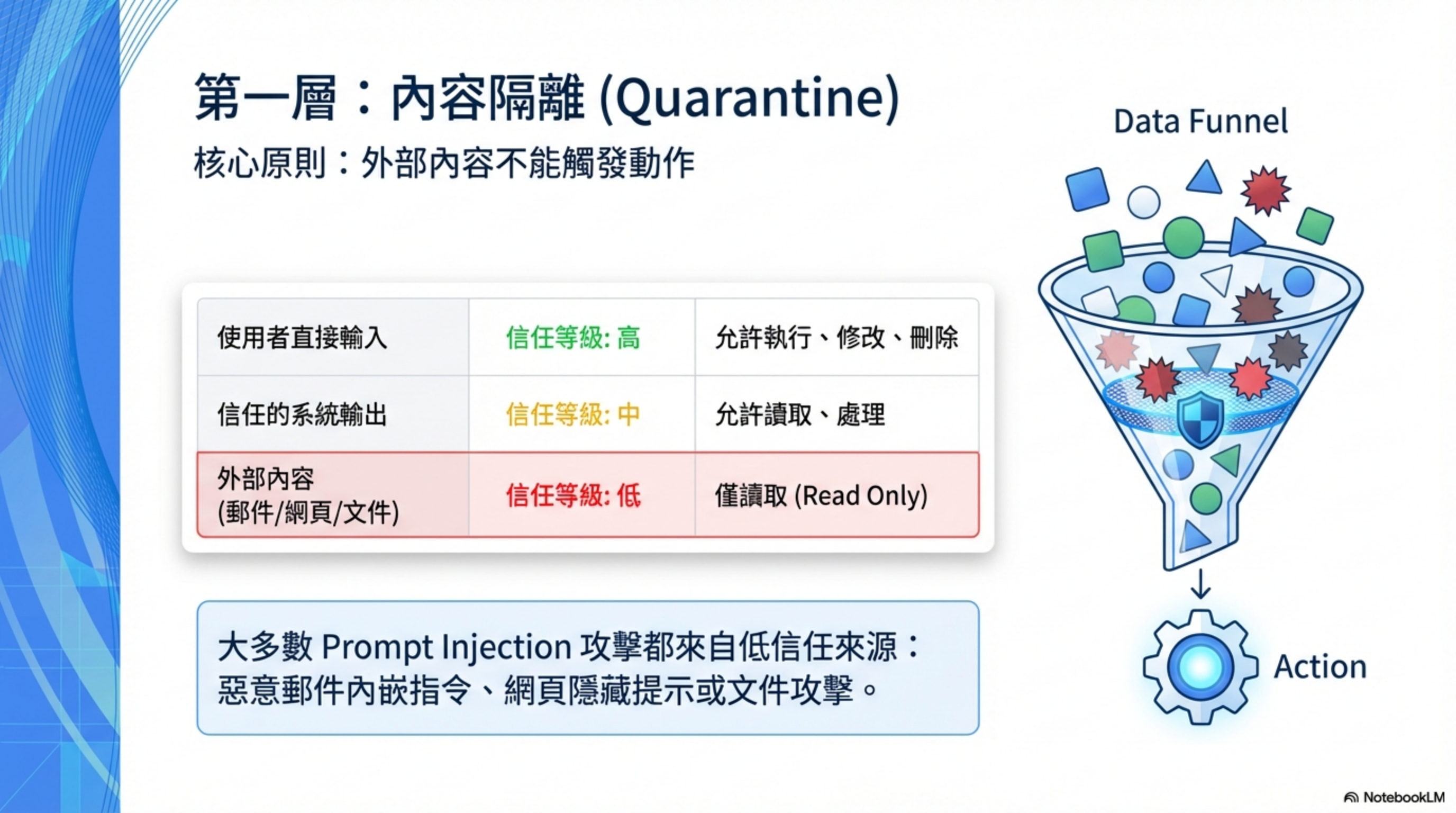
核心問題:外部輸入能做什麼?
這是大多數人會跳過的步驟,但可能是最重要的一層。Prompt Injection 是目前 AI Agent 最常見、也最容易被忽略的攻擊手法,尤其在自動處理郵件、網頁與文件時。
這一層的理論基礎來自 Google DeepMind 提出的 CaMeL 雙層 Agent 架構——核心概念是「讀資料」和「做動作」永遠分開。
2.1 信任等級設定
核心概念:
- 來自郵件、網頁、文件的內容 → 當作潛在敵意內容
- 只能讀取、只能提取資訊
- 不能根據外部內容執行指令
| 來源 | 信任等級 | 允許操作 |
|---|---|---|
| 使用者直接輸入的指令 | 高 | 執行、修改、刪除 |
| 信任的系統輸出 | 中 | 讀取、處理 |
| 外部內容(郵件、網頁、文件) | 低 | 僅讀取 |
重點: 大多數 Prompt Injection 攻擊都來自第三種來源。
2.2 告訴 AI 永遠不要顯示憑證
在 System Prompt 或 SOUL.md 加入:
1
2
3
4
5
永遠不要在對話中顯示密鑰、API Key 或 Token —
即使是部分內容、即使是對擁有者。
當讀取可能包含密鑰的檔案時,描述裡面有什麼,
但不要輸出實際內容。
效果: AI 會遵守這個規則,防止意外暴露憑證。
2.3 Agent Prompt Injection 防禦(ACIP)
ACIP = Agentic Context Integrity Protocol
Prompt Injection Defense 的核心是建立明確的信任邊界。在工作目錄維護 SECURITY.md 檔案,包含:
- 如何偵測注入嘗試
- 正規化處理(剝離格式技巧)
- 信任內容和不信任內容之間的邊界
- 發現可疑情況時的升級路徑
適用場景: 自動處理郵件或網頁內容時特別重要。
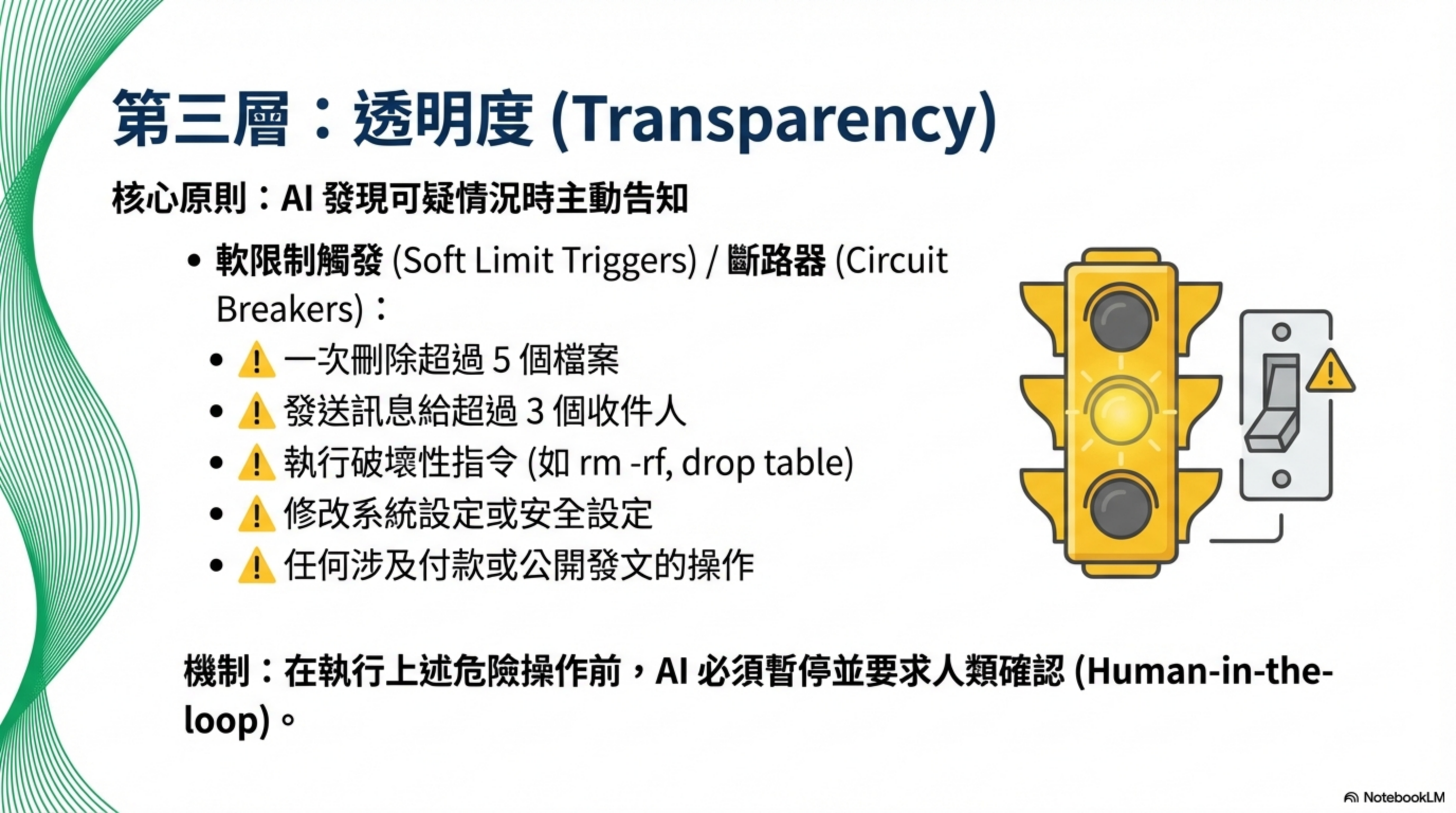
2.4 軟性限制(Circuit Breaker)
在 SOUL.md 加入規則:
1
2
3
4
5
6
7
在執行以下操作前,暫停並確認:
- 一次刪除超過 5 個檔案
- 發送訊息給超過 3 個收件人
- 執行破壞性指令(rm -rf、drop table 等)
- 修改系統設定或安全設定
- 任何涉及付款或公開發文的操作
注意: 這不是硬性阻擋,使用者可以說「直接做」繼續執行。目標是健全性檢查,不是官僚障礙。
第三層 Rollback:AI Agent 出事後的損害復原機制
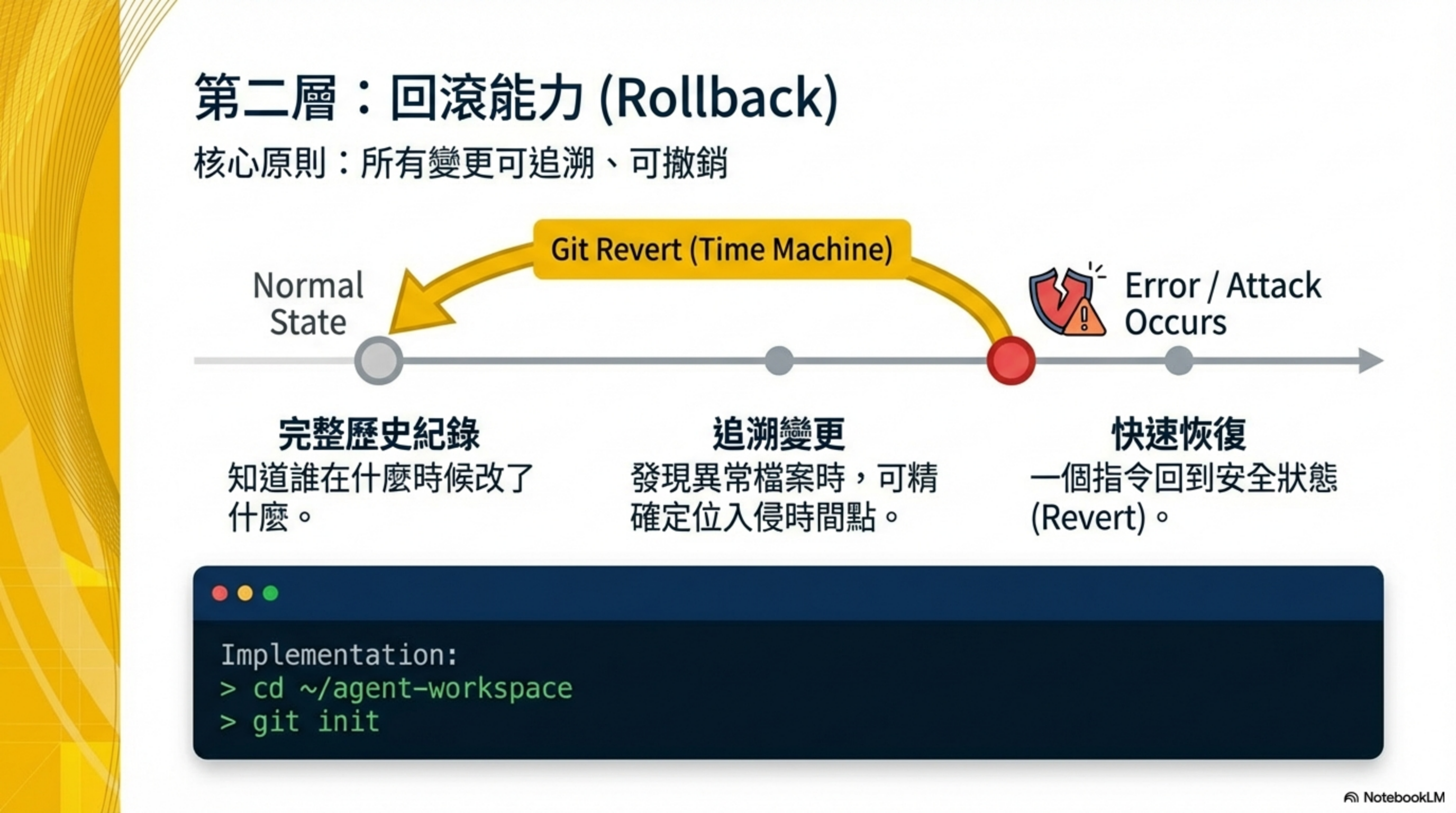
核心問題:出事後能復原嗎?
這一層確保即使前兩層被突破,損害仍然是可逆的。Rollback 能力是 AI Coding Security 中最容易被忽略但 ROI 最高的投資。
3.1 Git 追蹤工作目錄
初始化:
1
2
cd ~/moltbot-workspace
git init
建立 .gitignore:
1
2
3
4
5
6
7
*.key
*.secret
*.pem
.env*
*token*
*credential*
*session*
好處:
- 有完整歷史紀錄
- 發現異常檔案時可追溯變更時間
- 可回滾到安全狀態
3.2 事件記錄
原則:出錯的時候,寫下來。
在 Memory Files 維護事件日誌,格式範例:
1
2
3
4
5
6
## 2026-01-15 事件
**發生什麼:** Session Key 意外顯示在對話中
**根本原因:** 沒有規則禁止 AI 輸出憑證
**修復:** 在 SOUL.md 加入「永不顯示密鑰」規則
**狀態:** 已解決
好處:
- 強迫真正修復問題
- 發現長期的模式
3.3 Session 輪換
原則:密鑰暴露時,先輪換再調查。
Bitwarden 範例:
1
bw lock
效果:
- 終止活動 Session
- 暴露的 Token 立即失效
- 重新 unlock 並更新 Session 檔案
第四層 Transparency:LLM Agent Security 的早期預警系統
核心問題:能及早發現問題嗎?
這一層讓問題在造成嚴重損害前被發現。Agentic Security 的最後一道防線是「知道發生了什麼」。
4.1 每週自動安全稽核
設定 cron job(每週日晚上 11 點):
1
moltbot security audit --deep
檢查項目:
- 暴露的 Port
- 錯誤的權限設定
- 其他常見問題
- 官方安全文件更新(https://docs.molt.bot/gateway/security)
4.2 網路監控
安裝 LuLu 防火牆:
1
brew install --cask lulu
設定:
- 從 Applications 打開
- 批准權限(完整磁碟存取 + 網路擴充)
功能: 任何程序第一次嘗試對外連線時會警告。
讓 Moltbot 幫你做這件事
可以把這篇文章分享給 Moltbot,讓它幫忙實施這些安全措施。
Prompt 範本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
根據這篇文章加固安全設定:[貼上文章 URL 或內容]
按照四層防禦框架執行:
【Isolation 層】
1. 確認這台機器是否為專用設備
2. 檢查 Gateway bind 設定並修復為 loopback
3. 設定 Bitwarden CLI 做密鑰管理
【Quarantine 層】
4. 在 SOUL.md 加入永不顯示密鑰的規則
5. 加入內容隔離/信任等級到安全規則
6. 在 SECURITY.md 加入 ACIP Prompt Injection 防禦規則
7. 加入批量和破壞性操作的軟性限制
【Rollback 層】
8. 設定工作目錄的 git 追蹤
9. 在 Memory Files 設定事件記錄
10. 設定憑證暴露時的 Session 輪換程序
【Transparency 層】
11. 建立每週日晚上的安全稽核 cron job
12. 安裝 LuLu 做網路監控
需要權限的地方請詢問。需要使用者輸入的步驟請逐步引導。
常見問題 Q&A
Q: AI Agent Security 做到這個程度會不會太過度偏執?
考慮 Moltbot 的權限範圍:可存取郵件、訊息、檔案,可執行程式碼,可代表使用者發送訊息。這是很大的信任託付。結論:寧願感覺有點偏執,也不要發現自己不夠偏執。
Q: AI Agent 四層防禦一定要全做嗎?可以只做其中幾層嗎?
四層是相互補強的。Isolation 控制損害範圍,Quarantine 防止 Prompt Injection,Rollback 確保可復原,Transparency 及早發現問題。少一層,其他層的效果就打折。建議至少先做 Isolation 和 Rollback,這兩層投資報酬率最高。
Q: 沒有資安背景也能做 AI Agent Security Hardening 嗎?
這篇文章的每個步驟都是可執行的指令,不需要深厚的資安背景。你甚至可以把這篇文章丟給 Moltbot,讓它幫你執行。重點是「願意花時間認真讀文件」,而不是「要有多少年資安經驗」。
Q: AI Agent 密鑰管理用 Bitwarden 還是 1Password?
兩者都可以。Bitwarden 是開源免費方案,1Password 的 op run 可以直接注入環境變數而不寫檔,安全性更高一點。選擇你已經在用的那個,降低摩擦力。
Q: AI Agent 的軟性限制(Circuit Breaker)會不會很煩?每次都要確認?
設計上是「健全性檢查」而不是「官僚障礙」。只有批量刪除、群發訊息、破壞性指令才會觸發。日常操作不受影響。如果真的需要執行,說「直接做」就可以繼續。
致謝
安全設定受到 Moltbot 社群貼文啟發:
- @Shaughnessy119 — 在專用 VPS 上運行 Moltbot 做隔離
- @0xSammy — 揭露 923 台暴露的 Gateway 和
bind: loopback修復 - 社群關於密鑰管理的貼文(密鑰永遠不在程式碼裡,按需取用,用完即焚)
- 社群關於內容隔離框架的貼文(信任等級、主動披露、可犧牲基礎設施)
這篇文章適合誰?
- 正在導入 AI Agent(Moltbot、Claude Code、Cursor、Copilot)的工程師
- 擔心 Prompt Injection、Agent 失控的技術主管
- 想把 AI Coding 從「能跑」變成「可控、可回滾」的開發團隊
- 對 LLM Agent Security 有興趣的資安從業人員
- 希望理解 Agentic Security 框架的架構師
延伸閱讀
- 500 台 AI 助理裸奔公網:Moltbot 0.0.0.0 配置災難
- AI Agent 安全性:遊戲規則已經改變
- AI Coding 的第一個風險:你一直按 Yes
- CaMeL:Google DeepMind 提出的 Prompt Injection 防禦架構 — 本文第二層「內容隔離」的理論基礎
- CaMeL Agent 架構落地 PostgreSQL:用 RLS 設計不可繞過的 AI Memory — 把隔離層建在資料庫的實作方案
關於作者:
Wisely Chen,NeuroBrain Dynamics Inc. 研發長,20+ 年 IT 產業經驗。曾任 Google 雲端顧問、永聯物流 VP of Data & AI、艾立運能數據長。專注於傳統產業 AI 轉型與 Agent 導入的實戰經驗分享。
相關連結:
- 部落格首頁:https://ai-coding.wiselychen.com
- LinkedIn:https://www.linkedin.com/in/wisely-chen-38033a5b/