回單 OCR 落地實戰:會踩的坑,與踩完坑沉澱的架構心法

前一篇〈地端 OCR API〉講的是「流程怎麼串、基礎建設怎麼蓋」。這一篇講的是另一半——辨識真正落地時會遇到的問題,以及踩完坑之後沉澱出來的架構心法。 一句話總結這篇:辨識最小化、系統最大化、不確定就交人。
大家現在講 OCR,很習慣性地丟一句「現在有 Vision LLM 了,這問題早就解決了」。
我自己這幾年做回單(物流簽收單、出貨單、各種現場回傳的紙本)辨識,踩過三代做法,老實說:Vision LLM 不是萬靈丹,它是演進的最新一棒,但它有它的 cons。 後面那些坑,有一半就是它的 cons。
所以這篇我想先把「三代演進史」講清楚,你才會知道為什麼今天還是有人在用看起來比較舊的做法——不是他們落伍,是場景不一樣。
開場:回單辨識的三代演進
每一代都解掉上一代的痛,但也帶來新問題。這不是「誰取代誰」,是「每一代各自還活著,看你的場景跟資安要求選哪一代」。
第一代:OCR + 正則(Regex)
最初的做法,DocAI 路線。
傳統 OCR(Tesseract、Google Document AI…)把圖片轉成文字,再用 Python 正則表達式逐欄抓:單號在哪、日期長怎樣、地址符合哪個規則。
好處是:成本低、可離線、速度快,格式固定時非常穩、可預測、好除錯,完全不需要 LLM、沒有 token 成本。
壞處是:格式一變就崩。換一種單就要重寫一套 regex;OCR 認錯一個字、缺漏一個字,整條 regex 就對不上;客戶越多、格式越雜,regex 越長越脆,最後變成維護地獄。而且它完全不懂語意,只會硬比對字串。
「格式固定時很香,格式一雜就變成 regex 地獄。」
第二代:OCR + 文字 LLM
這是我 2024 年的主力做法,老實說超好用。
一樣先用 OCR 把圖轉成文字,但不再寫死 regex,而是把 OCR 出來的文字丟給文字型 LLM,讓它理解、抽欄位、補全。
一上手正確率就大幅提升。為什麼?
- 格式不一樣不用重寫 regex:LLM 自己理解語意,換種單也能抽。
- 能補全缺漏字:OCR 漏一兩個字,LLM 靠上下文補回來。
- 能處理同義/別名欄位(「單號」「託運號」它都認得)。
- 開發快、維護成本大降。
- 還有一個很關鍵的優勢——可以做到全地端。OCR 跟文字 LLM 都有成熟的地端方案,資料不出公司,對個資、機敏單據這是決定性的優勢。
但它的天花板,被前面那層 OCR 鎖死了:
- 卡在 OCR 那一關:OCR 先讀錯,LLM 拿到的就是錯的文字,垃圾進垃圾出。
- OCR 丟掉版面與顏色資訊:紅藍筆、表格結構、手畫線全沒了,LLM 根本看不到。
- 手寫、簽名、塗改這種「圖像才看得懂的東西」,轉成文字就失真了。
「LLM 把 regex 的痛解掉了,還能全地端跑;但天花板被前面那層 OCR 鎖死。」
第三代:Vision LLM 直接判斷
最新做法,圖直接進、跳過 OCR。
不再先做 OCR,直接把回單圖片餵給多模態模型(GPT-4o、Claude),讓它同時看圖 + 理解語意,一步輸出結構化欄位。
它的價值在於——後面那六個坑,它能直接解掉一大半:
- 看得懂版面、表格、顏色、手畫線,不再被 OCR 那層過濾掉。
- 手寫、塗改、勾選、簽名、紅藍筆都能直接判讀(前兩代做不到的)。
- 用邏輯與上下文判斷形近字(1/l、O/0)、補語意。
- 免模板、免 regex、換格式也能吃。
但它的代價在別的地方:
- 🐢 速度慢:圖片進、推理重,比純文字流程慢不少。
- 💰 價格貴:vision token 成本高,量大時很有感。
- 🏠 地端模型還不成熟:強的 vision 模型多在雲端,想全地端、資料不出公司目前很難——這正是第二代(OCR + Text LLM)到今天還有價值的原因。
- ⚠️ 它仍做不到 100%:爛照片(受潮、手機亂拍)資訊根本沒拍進去,它也救不了;格式太雜,準確率還是會晃(這要靠分流,後面 Lesson 1 會講)。
「Vision LLM 把那些坑解掉一大半,代價是慢、貴、還難全地端——選哪代,看你的場景與資安要求。」
三代怎麼選?一張表
| 維度 | OCR+Regex | OCR+Text LLM | Vision LLM |
|---|---|---|---|
| 格式變化適應 | ❌ 重寫 regex | ✅ 好 | ✅ 最好 |
| 手寫/塗改/顏色/連線 | ❌ | ❌(OCR 已丟失) | ✅ |
| 形近字判斷 | ❌ | 🔶 部分 | ✅ |
| 全地端/資料不出公司 | ✅ | ✅ 成熟 | ❌ 目前不成熟 |
| 速度 | ✅ 快 | ✅ 快 | 🐢 慢 |
| 成本 | ✅ 低 | 🔶 中 | 💰 高 |
| 適合場景 | 格式固定、量大、要便宜 | 機敏資料要地端、格式多變 | 手寫/塗改重、格式雜、可上雲 |
務實結論:機敏單據或要地端 → 走 OCR + Text LLM;手寫/塗改/連線多、又能上雲 → 走 Vision LLM;而且這兩者常常混用——清晰的單走便宜的地端流程,難的才丟給 Vision LLM。
「Vision LLM 是最強的一棒,但它的 cons(慢/貴/難地端),就是 OCR + Text LLM 至今還站得住的理由。」
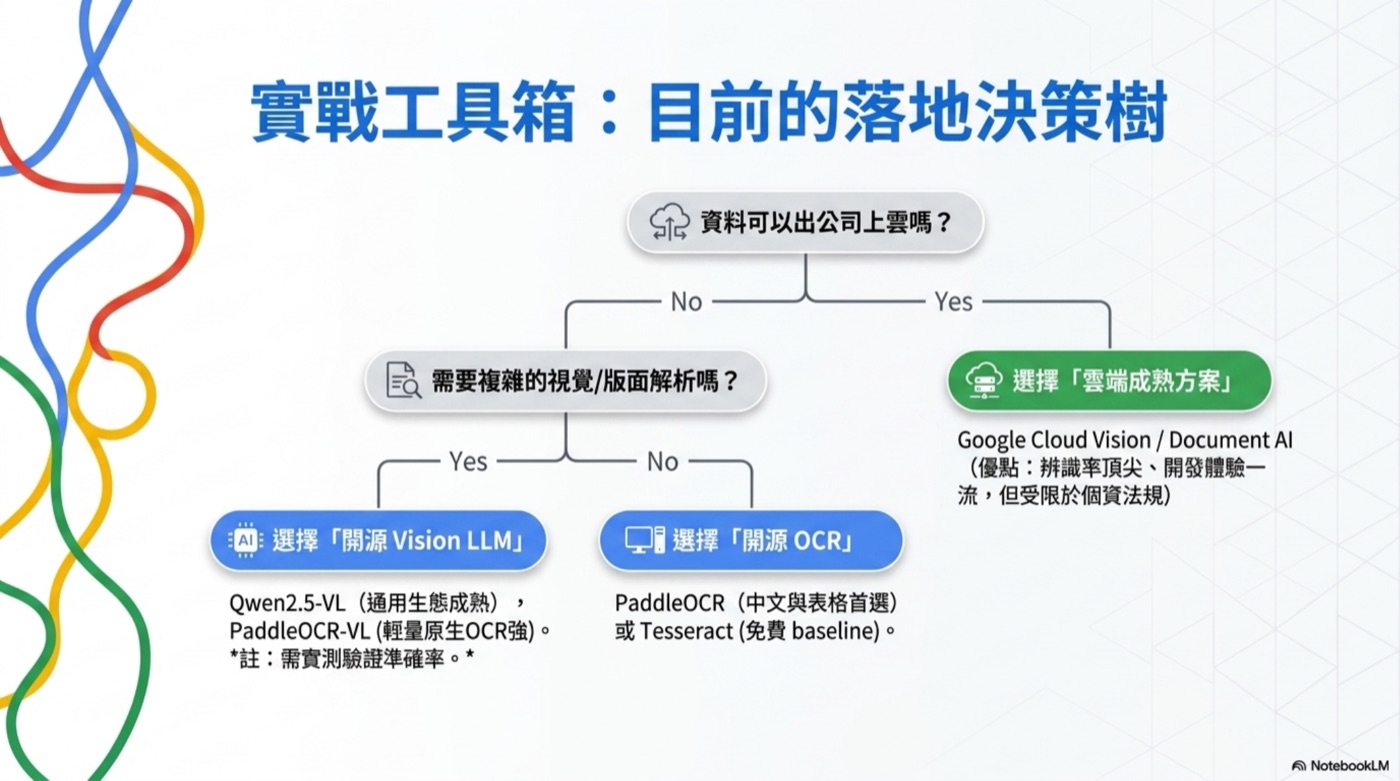
那實際上用哪些工具?三代的工具箱
三代講完,最常被問的就是:「那你實際上用什麼?」這段把抽象的三代落到具體工具,順便講一下各自的地端能不能做。
傳統 OCR 引擎(第一、二代的前段)
這層負責「把圖變成字」,第一代直接接 regex、第二代接文字 LLM,都需要它。三個我實際碰過的:
-
Tesseract:最老牌的開源 OCR 引擎(Google 維護),純地端、免費、語言包多。優點是穩、可離線、社群大;缺點是對中文、手寫、複雜版面比較吃力,現場拍的歪斜爛圖辨識率會掉很多。它適合「格式乾淨、印刷為主」的場景,當 baseline 很好用。
-
PaddleOCR(PaddlePaddle/PaddleOCR):百度 PaddlePaddle 出的開源文檔 AI 工具包,可以部署到地端(支援 NVIDIA GPU、Intel CPU 等多種硬體後端),支援 100+ 語言。對我來說它最大的價值是中文跟表格特別強——回單這種繁體中文 + 表格混雜的場景,它比 Tesseract 高一截。而且它現在把整條線拉到「PDF/圖片 → 結構化 JSON / Markdown」,已經不只是純 OCR,連版面分析都包進去了。如果你要走全地端、又是中文單據,PaddleOCR 幾乎是首選 baseline。
-
Google Cloud Vision / Document AI:老實說,這是我的最愛。辨識率高、版面分析成熟、API 好接、手寫跟複雜單也撐得住,開發體驗一流。但要誠實講它的硬傷——它是雲端服務,資料要出公司。 所以它跟「機敏單據要地端」這個需求天生衝突:能上雲的場景它超香,碰到個資、不能出公司的單據就直接出局。這也正是為什麼地端那條線,我還是得另外養一套。
一句話:Tesseract 當免費 baseline,PaddleOCR 走地端中文首選,Google OCR 能上雲時最好用——但機敏資料就只能放生它。
可以跑地端的 Vision LLM(第三代)
第三代的重點是「免 OCR、圖直接進」,而且現在開源社群已經追上來,好幾個能跑地端了。我整理幾個 2025–2026 比較值得看的:
| 模型 | 大小 | 特點 | 適合 |
|---|---|---|---|
| Qwen2.5-VL(阿里) | 7B–72B | DocVQA 95.7,手寫/表格/多語言文檔解析強,生態最成熟 | 通用文檔、回單主力候選 |
| PaddleOCR-VL(百度) | 0.9B(最新 1.6) | 小而專精,OmniDocBench v1.6 拿到 96%+,原生 OCR benchmark 打贏不少前沿大模型,支援 109 語言 | 純地端、追求 OCR 準度、輕量部署 |
| dots.ocr(rednote) | 1.7B | 版面偵測 + 內容辨識合一,100+ 語言,vLLM 已官方整合,小模型 SOTA | 地端、多語版面解析 |
| MiniCPM-V 2.6 | 8B(約 5.5GB) | 體積小、好塞單卡甚至邊緣裝置,OCR 表現頂段 | 資源有限、要塞地端小機器 |
| olmOCR 2(AllenAI) | 7B | 用 RLVR 訓練、完全開源(含資料與 code),文檔 OCR 專精 | 要可複現、license 乾淨的場景 |
| DeepSeek-OCR | — | 主打「光學壓縮」,用更少 vision token 達到相近效果,省成本 | 量大、想壓 vision token 成本 |
這裡要講一個我自己的觀察:Vision LLM 這塊發展真的很快,而且雲端跟地端是兩種速度。
雲端大模型(GPT-4o、Claude 這種)其實已經把大量問題解掉了——前面那六個坑裡,手寫、形近字、紅藍筆、塗改,雲端模型現在的成熟度都相當高,這是過去兩年最大的進展。所以如果你的場景能上雲,老實說現在是史上最好做的時候。
地端這邊也冒出好幾個 candidate——上面那張表就是。這些發展很快的小模型(0.9B、1.7B、7B)在 benchmark 上的數字一個比一個漂亮,方向非常令人興奮。但我必須誠實講:benchmark 漂亮 ≠ 你的單據上準。 這些小模型還很新,需要時間驗證它在真實、雜亂、爛照片的回單上到底穩不穩——benchmark 跑的是乾淨資料集,你現場那些受潮、歪拍、紅藍筆混寫的單,是另一回事。
所以我的態度是:地端小模型我看好、會持續追,但上線前一定要拿自己的真實單據做一輪實測,別只看 benchmark 數字就梭哈。 這也是為什麼我前面說「不是每個都跑過完整 production」——不是不信任,是還在驗證的路上。
坦白說,目前 Qwen2.5-VL 跟 PaddleOCR-VL 是我最看好的兩個地端方向——一個生態成熟通用,一個小而準、原生 OCR 強。其他的可以當候選池,依你的硬體(單卡能塞多大)跟語言需求去挑。
重點不是「哪個最強」,而是回到三代那張表的邏輯:能上雲、要最省事 → Google OCR / 雲端 Vision LLM(已經很成熟);要地端、資料不出公司 → PaddleOCR(-VL) / Qwen2.5-VL 這條開源線(發展快、但要自己驗證準確率)。 工具一直在變、而且變很快,但「看資安跟場景選代、上線前用真實資料驗證」這個判斷不會變。
💡 務實提醒:地端 Vision LLM 雖然追上來了,但它一樣慢、一樣吃 GPU。前面三代表裡 Vision LLM 那欄「地端不成熟」正在改善,但「慢、要 GPU」這兩個 cons 還在——所以清晰的單還是先走便宜的 OCR + Text LLM,難的才丟 Vision LLM,這個混用策略不變。
問題篇:Vision LLM 落地會踩的六個坑
接下來這六個坑,是我用 Vision LLM 之後,實際在客戶現場的單據上撞到的。先講清楚一件事:這六個坑裡,Vision LLM 能解掉前五個的一大半,但第六個它解不了——因為那不是模型問題,是輸入問題。
坑 1:手寫辨識率,是 OCR 的天敵
印刷體 95 分,手寫只剩 60 分。
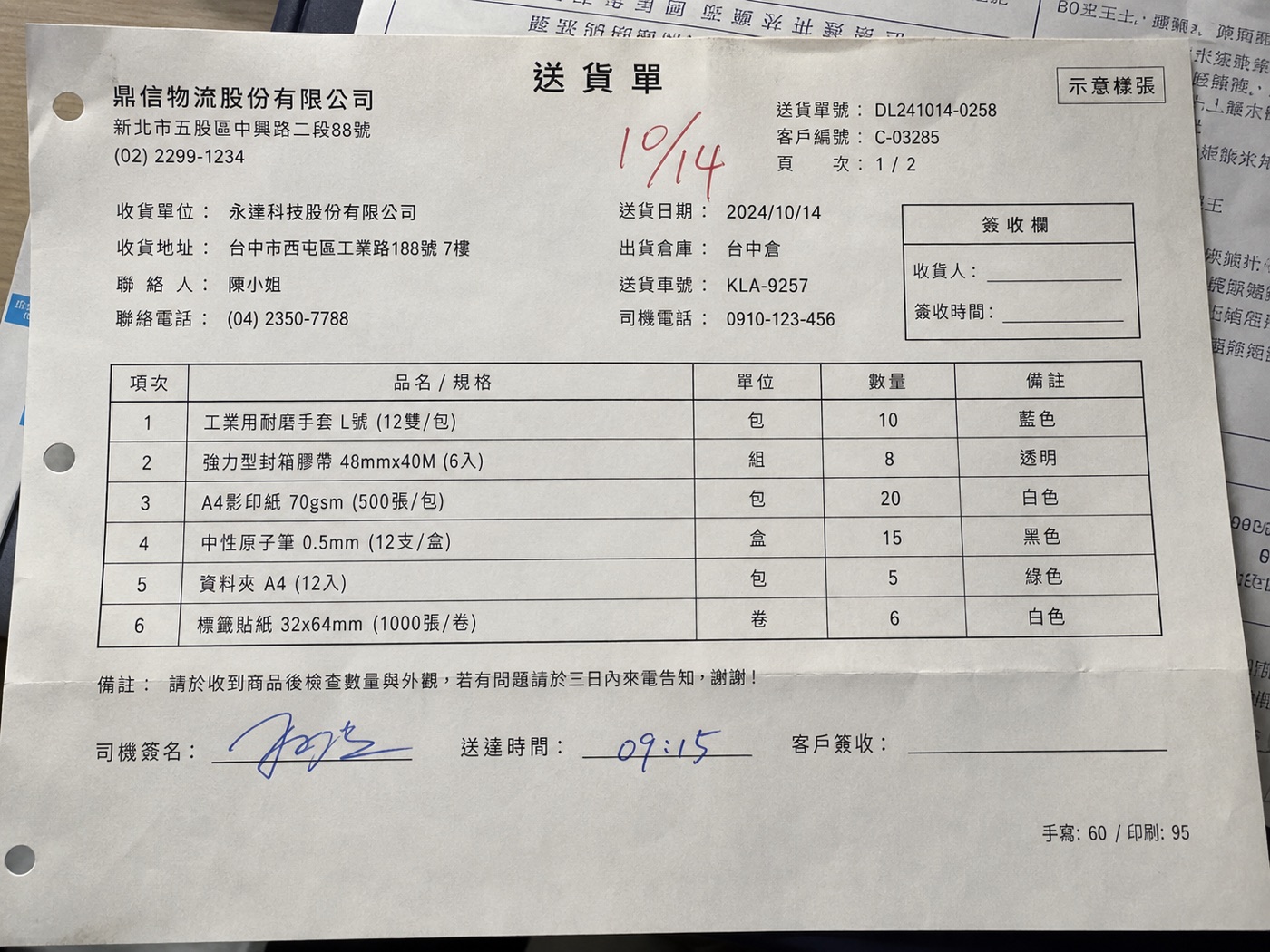
司機簽名、收貨人親簽、潦草的送達時間「09:15」、紅筆寫的「10/14」——同一張單,印刷欄位(單號、地址)AI 抓得準,一到手寫就掉分。
為什麼難?每個人字跡不同,沒有固定字型可比對;草寫、連筆、花押式簽名,連人都不一定認得;再加上拍照角度、光線、墨水深淺,誤差放大。
務實做法:
- 多模態 LLM 比傳統 OCR 強很多,但不要追求 100%。
- 關鍵是要 AI 標 confidence,看不清就填
null、別亂猜。 - 收貨人簽名一律進人工複核——它是法律憑證,認錯比認不出更糟。
「不是要 AI 全自動,是把人從 90% 的重複工解放,只複核那 10%。」
坑 2:印刷體也有坑——1 跟 l、O 跟 0 分不清
連印刷體都不能 100% 相信。
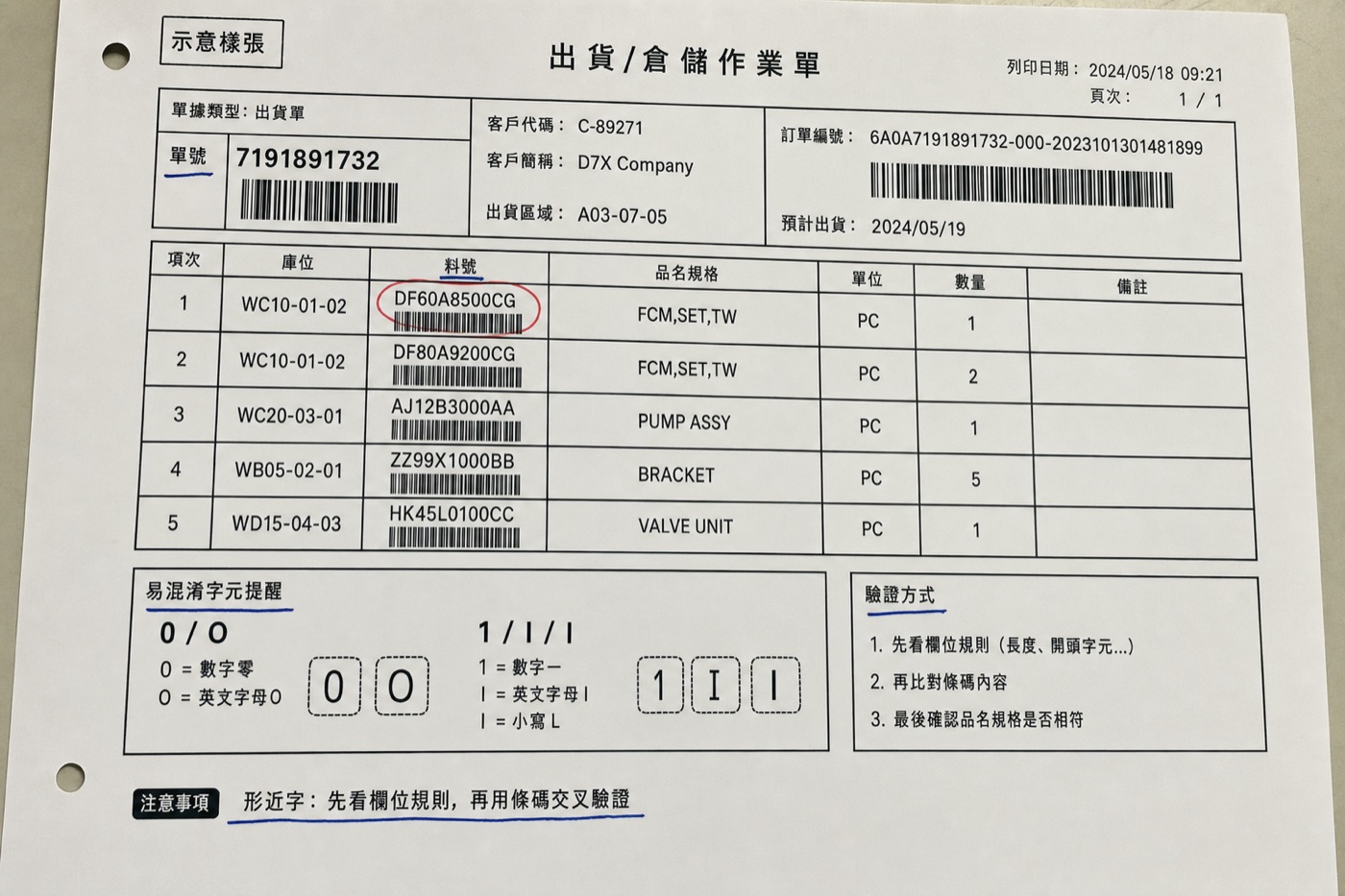
出貨單號 7191891732、料號 DF60A8500CG——裡面到底是數字 0 還是字母 O?是 1 還是小寫 l、大寫 I?字型一換、列印一糊、傳真一壓,O0、1lI、5S、2Z、8B 全都長得像。
傳統 OCR 是逐字比對字型,形近字本來就是它的死穴——它只看「這個字長怎樣」,不看上下文。單號、料號一個字錯,整筆對不上訂單,帳就爛了。
這裡 LLM 能贏一截,因為它會用邏輯跟上下文判斷:
- 「這欄是純數字單號,所以這個應該是
0不是O」。 - 知道料號格式規則(哪幾碼是英文、哪幾碼是數字),反推正確字元。
- 能比對校驗碼/條碼數字交叉驗證。
- 看得懂「這是台灣物流單號」的慣例,提高判斷準確度。
怎麼解:Prompt 明確告知欄位型態(這欄全數字/這欄是料號 A-Z+0-9);有條碼就請 AI 用條碼數字交叉比對手填/印刷的單號;單號、料號這種對帳關鍵欄位,有疑慮就標複核。
「OCR 看『長得像什麼』,LLM 想『在這個位置,它應該是什麼』。」
坑 3:紅筆藍筆混寫,AI 看成一團
人眼分得開,OCR 揉成一坨。
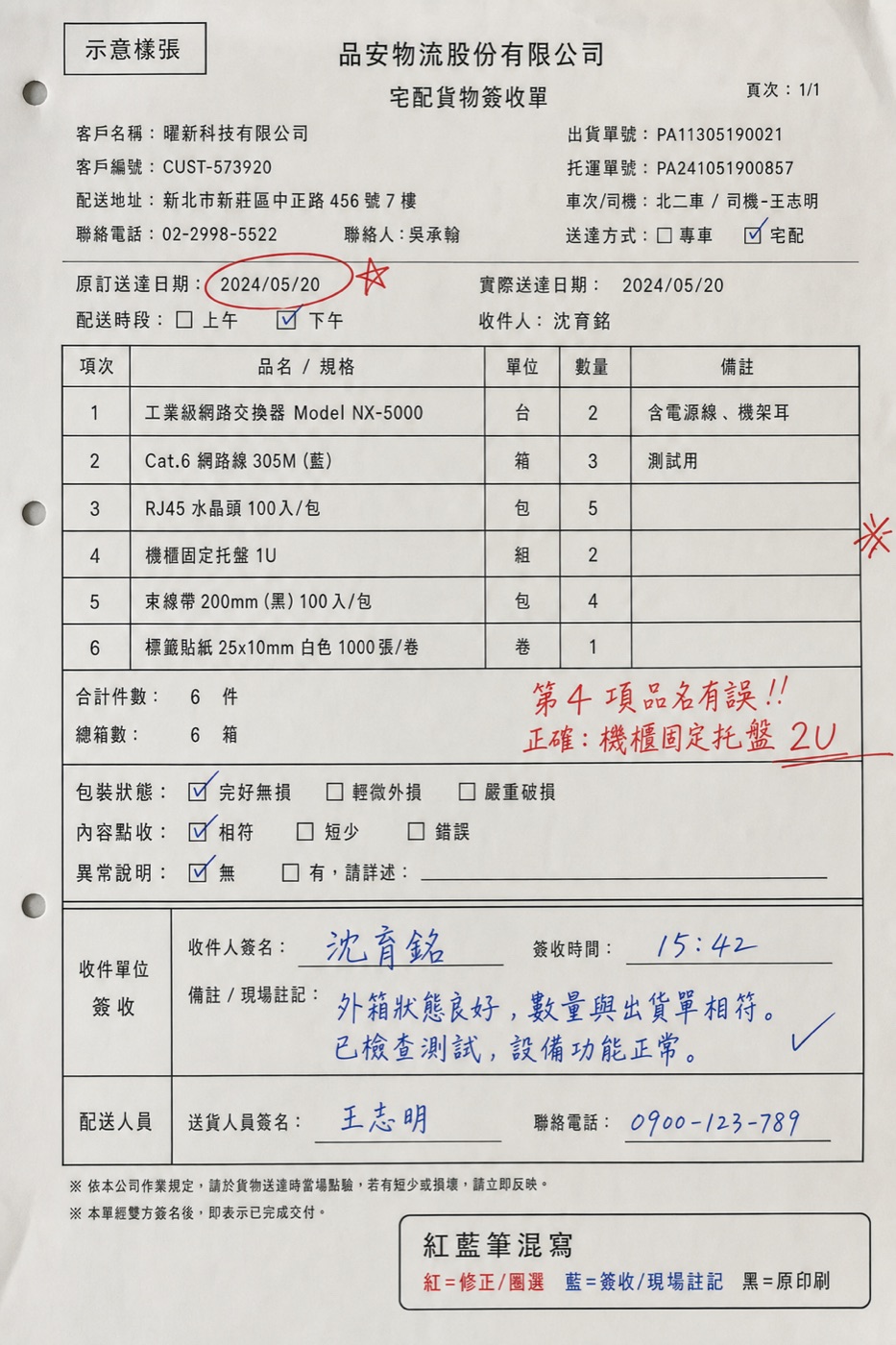
客戶/倉管用紅筆圈日期、藍筆寫時間、黑筆是原本印刷——紙面上這些字空間上交疊,但人一看就知道「紅的是註記、藍的是簽收」。
純文字 OCR 只會把所有字照位置串成一行,語意全黏在一起。「10/14」(紅筆改期)和「09:15」(藍筆時間)會被讀成同一段。顏色 = 語意,但傳統 OCR 丟掉了顏色資訊。
怎麼解:用視覺 LLM,它能理解「不同顏色/筆跡 = 不同來源的資訊」;Prompt 明確要求依筆色與位置分類(印刷 vs 紅筆註記 vs 藍筆簽收);輸出結構化欄位而非一整段文字,強迫資訊各歸各位。
「OCR 認的是字,視覺模型讀的是『這張單想表達什麼』。」
坑 4:手畫線跨欄位連結,是一種「視覺語言」
一條手繪線,藏著一條規則。
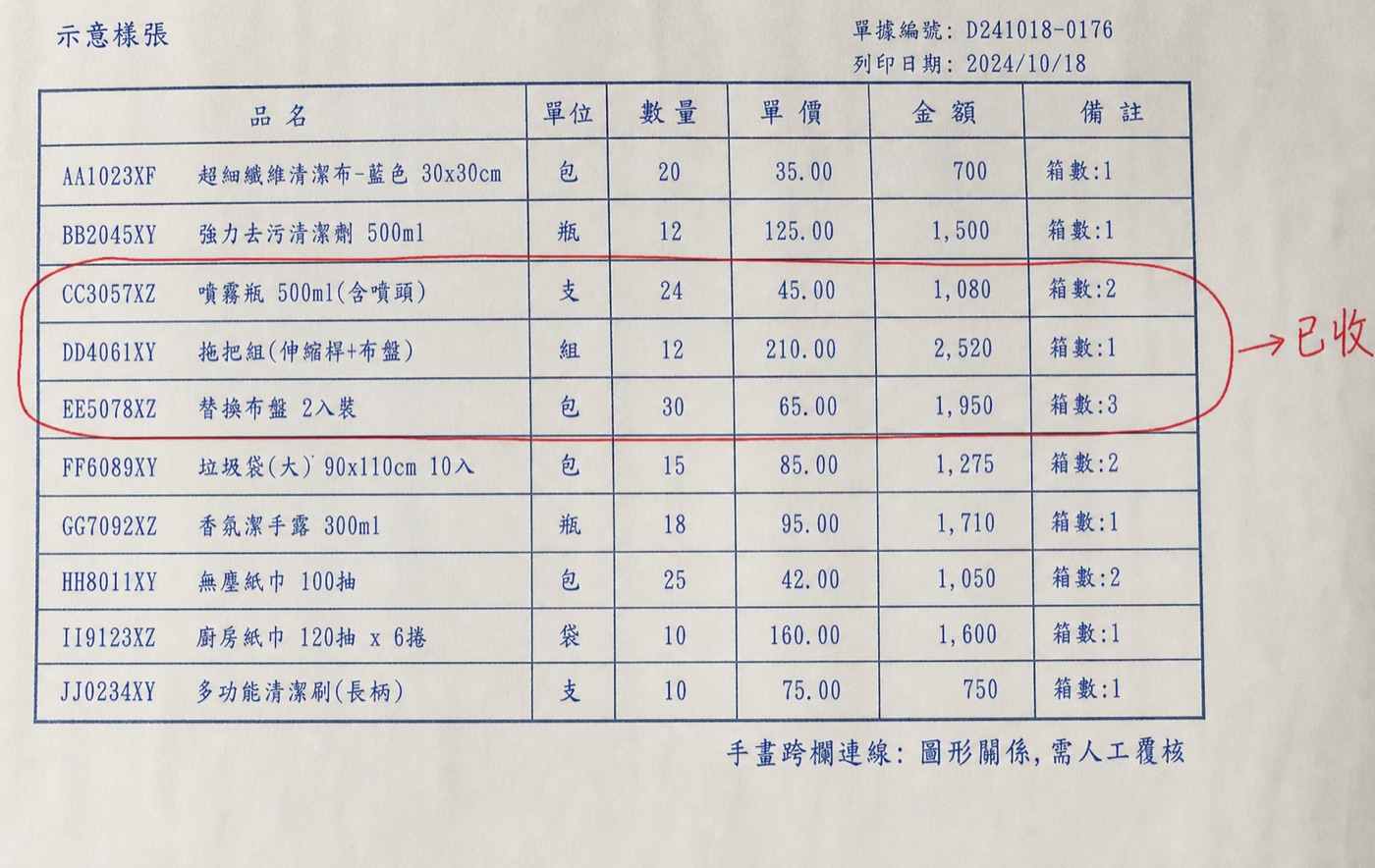
表格裡客戶用一條手寫線把 row 2、3、4 框/連在一起,再從這群拉一條線到旁邊註記「已收貨」。意思是:這三項一起、且都已簽收——但表格本身根本沒有這一欄。本文開頭那張單就是真實案例:一條紅線把幾個 row 圈起來、旁邊寫「已收」,這資訊系統裡完全沒有。
這是圖形關係,不是文字:OCR 根本不會「讀線」。線的起點、終點、框住哪幾列,全靠空間視覺判斷;而且同樣一條線在不同位置意思不同(框選 vs 箭頭 vs 刪除)。
怎麼解:必須靠多模態視覺模型理解版面與圖形關係;Prompt 要它描述線連結了哪些列、表達什麼狀態(例:rows 2-4 → 已收貨)。但這類信心通常偏低,直接標複核,別讓 AI 自由心證。
坦白說,這是目前最難的一類,現階段就是 AI 輔助、人最終判讀。
「客戶手畫的線是一種沒寫進系統的規則,AI 幫你看見它,但別讓它替你拍板。」
坑 5:劃掉改數字,哪個才算數?
「應到 8 個」劃掉改「7 個」。
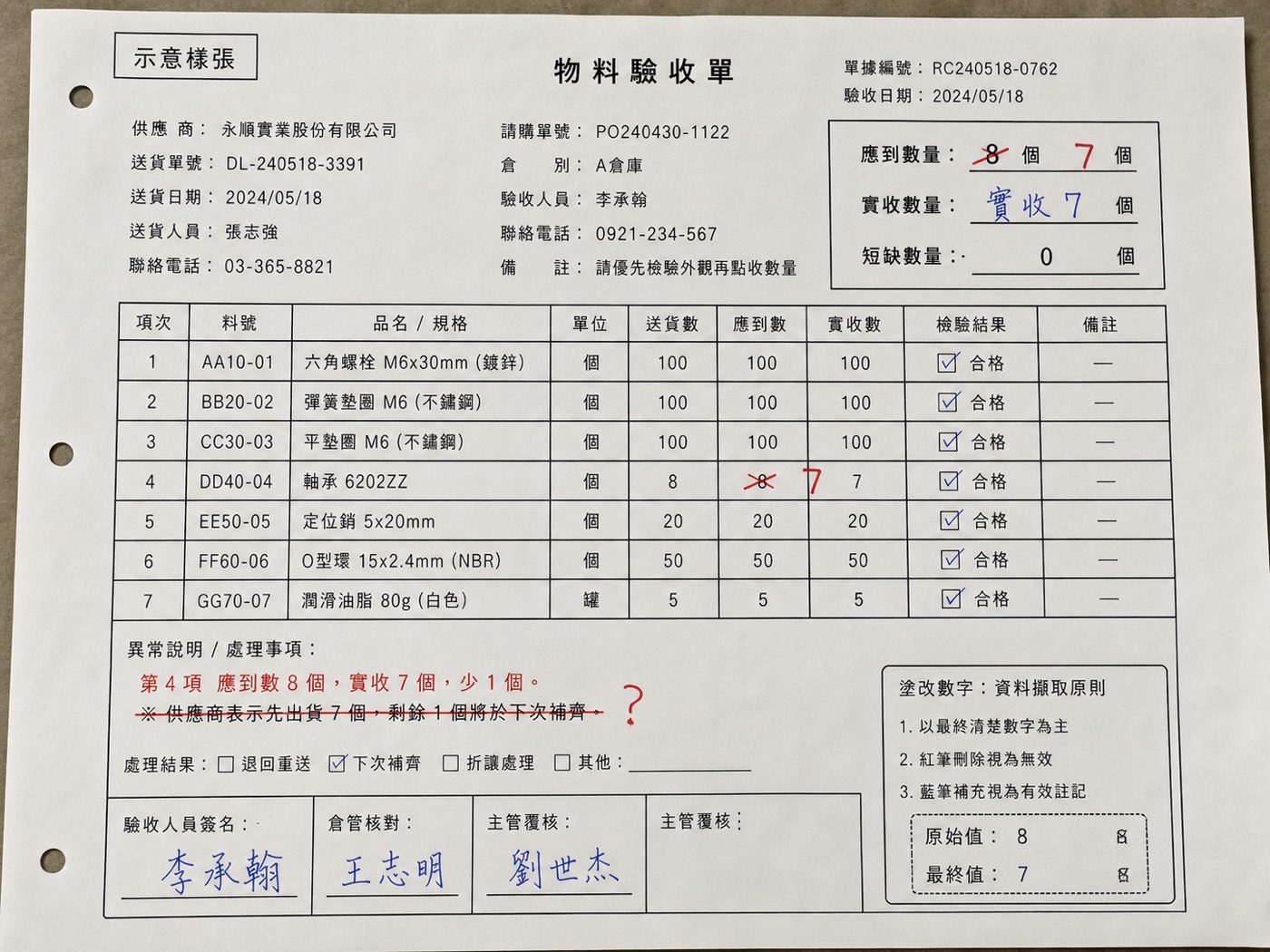
印刷數量是 8,現場短少,倉管把 8 劃掉、手寫改成 7。系統該記的是 7(實際),不是 8(原印刷)。
難在哪?畫面上 8 跟 7 同時存在,OCR 可能讀到 8、讀到 7、或讀成「87」。要判斷哪個被劃掉(作廢)、哪個是最終值——這是語意 + 視覺。還要分辨:劃掉是「修正」還是「整筆取消」。
怎麼解:視覺 LLM 能理解「刪除線 = 作廢、手寫 = 最終值」;Prompt 明確要求輸出「最終有效值」+「原始值」兩欄並註記有修改;數量、金額這種會出帳的欄位,有修改一律標複核,並保留原圖佐證,爭議時可回查。
「印刷是『原本要出的』,手寫塗改是『實際發生的』——AI 要會分得出。」
坑 6:紙爛了,再強的模型也讀不出來
垃圾進、垃圾出,AI 也救不了。
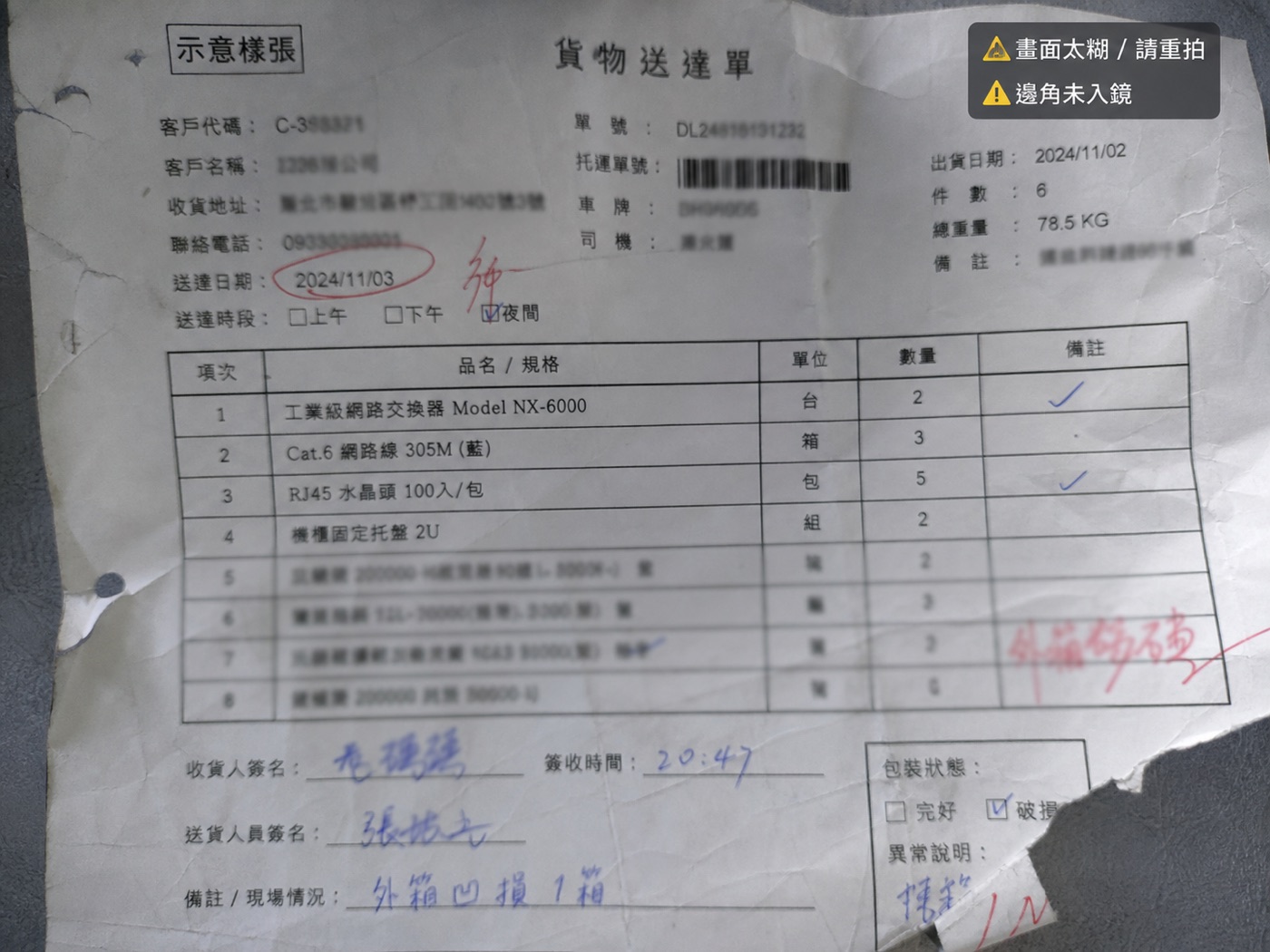
回單在貨車上摺到、受潮、沾到油污,字糊成一片;現場手機隨手拍,歪斜、反光、陰影、手震、解析度不足;傳真/影印到第 N 手,墨色淡到剩殘影;蓋章蓋歪糊住單號、簽收欄被水暈開。
這個坑跟前面五個本質不一樣,要講清楚:
- 前面五個坑是「資訊在、但難判讀」→ 視覺模型能補。
- 這個坑是「資訊根本沒被拍進去」→ 像素裡沒有的東西,再強的模型也變不出來。
所以這不是模型問題,是輸入問題(Garbage In, Garbage Out)。重點在源頭,不在模型:
- 拍攝端把關最有效:拍照 SOP(對齊、補光、不反光、填滿畫面、拍完當場檢查)。
- App/表單端做即時品質檢測:太模糊/太暗/太歪,當場跳「請重拍」,不讓爛圖進系統。
- AI 端可做基礎前處理(去歪斜、增強對比、去背),但別期待它無中生有。
- 影像品質低於門檻,直接標複核,不硬辨識。
「AI 落地 80% 是流程與源頭,不是模型——先讓人把單拍清楚,再談辨識。」
問題篇小結:六個坑,一個共同真相
| # | 坑 | 本質 |
|---|---|---|
| 1 | 手寫辨識率差 | 資訊在、但難判讀 |
| 2 | 形近字 1/l、O/0 | 印刷也不能盡信,要靠上下文 |
| 3 | 紅藍筆混寫 | 顏色 = 語意,會被揉成一團 |
| 4 | 跨欄位手畫線 | 圖形關係,非文字 |
| 5 | 塗改數字 | 要分辨作廢 vs 最終值 |
| 6 | 影像品質爛 | 資訊根本沒被拍進去 |
共同真相:OCR/AI 永遠做不到 100%。 重點不是追求滿分,而是怎麼設計系統,讓它在會出錯的地方依然可靠。
這就是下面三個 Lesson Learned。
Lesson Learned:踩完坑,我們學到的三件事
Lesson 1:不要一個 Prompt 打天下
踩到的坑:我一開始以為,有 LLM 就能通吃所有格式——三星出貨單、黑貓宅配、自家簽收單、各客戶客製單…結果一個萬用 Prompt 改 A 壞 B,永遠在拆東牆補西牆。欄位位置、命名、語意每種單都不同(A 單「單號」在左上,B 單叫「託運號」在右下)。
學到的方法:兩段式——先分類,再路由。
1
2
3
4
5
6
7
8
9
10
回單圖片
│
▼
① LLM 格式分類器 ←「這是哪一種單?」(三星出貨單/黑貓/自家簽收單…)
│
▼
② Prompt 資料庫 ← 依格式取對應的專屬 Prompt(各自最佳化、互不干擾)
│
▼
③ LLM 抽取欄位 ← 用「對的 Prompt」辨識 → 準確率大幅提升
為什麼這樣設計:
- 每種格式專屬 Prompt、各自調到最準、互不干擾。
- 改 A 不會壞 B:每份 Prompt 獨立,動它只影響自己。
- 好擴充:新客戶格式 → 加一個分類標籤 + 一份新 Prompt,舊的全不動。
- 可維護、可版本控管:每份 Prompt 像程式模組,能單獨測試、單獨優化。
「不要一個 Prompt 打天下。準度靠分流,穩定靠隔離。」
Lesson 2:不要讓 OCR 當全部
踩到的坑:我連單號、品名、應出數量全靠辨識——又慢、又不準、又難對帳。後來才想通:這些欄位系統裡本來就有正確答案,我幹嘛賭辨識準不準?
學到的方法:辨識最小化、系統最大化。
| 資料類型 | 誰負責 | 為什麼 |
|---|---|---|
| 單號、料號、客戶、地址、應出數量 | 回系統撈(OMS/WMS) | 系統有正解,辨識只會出錯 |
| 出車、司機、路線、預計到貨 | 回系統撈(TMS) | 結構化資料,比讀紙準 |
| ⭐ 現場手寫修改的數字(8→7) | OCR + LLM | 紙上才有,系統不知道現場短少 |
| ⭐ 簽收狀態/親簽/收貨時間 | OCR + LLM | 紙本是唯一憑證 |
| ⭐ 現場手寫異常註記(破損、退回) | OCR + LLM | 只存在紙面 |
設計原則:
- 用單號當鑰匙:OCR 讀出單號 → 回 OMS/WMS/TMS 把其餘欄位補齊、交叉驗證。
- OCR 讀到的單號還能跟系統比對,連單號辨識錯都能被抓出來。
- 不要讓辨識去「重建」系統本來就有的資料。
「OCR 不是用來重抄一張單,是補上系統不知道、只發生在現場的那幾格。」
Lesson 3:AI 做不到 100%,就要會舉手
踩到的坑:手寫、形近字、塗改、連線、爛照片——錯得很有自信比讀不出來更可怕。靜默放行一筆錯的簽收/數量,後面對帳爆掉、責任難追。
學到的方法:系統要具備三件事。
- 自動偵測風險狀況:偵測到手寫簽名、多色筆註記、跨欄連線、數字塗改 → 系統自己標記。
- 誠實回報信心:每欄給 confidence,看不清填
null,絕不亂猜硬填。 - 主動轉人工複核:低信心/關鍵欄位(簽名、數量、金額)有疑慮 → 自動進「待人工審核」佇列。
落地原則:
- 能自動的自動:印刷欄位、清晰手寫 → 直接入庫。
- 沒把握的舉手:簽名、連線、塗改、爛圖 → AI 標記、人最終判讀。
- 最危險的是「錯得很有自信」:寧可 AI 說「我不確定」,也不要它默默填錯。
「AI 的成熟,不是它什麼都會,而是它知道什麼時候該說『這張我不確定,請人看一下』。」
總結:回單自動化的實戰心法
辨識最小化、系統最大化、不確定就交人。
把三個 Lesson 串起來,就是一條完整的落地路徑:
先認出是哪種單,用對的 Prompt 讀準(Lesson 1); 只讀現場才有的關鍵狀態,其餘回 WMS/TMS/OMS 撈(Lesson 2); 這些關鍵狀態裡,AI 沒把握的就舉手交人工(Lesson 3)。
三句話心法:
- 🎯 辨識最小化:OCR 只做「紙上才有、系統沒有」的事。
- 🏛️ 系統最大化:能回 WMS/TMS/OMS 撈的,絕不靠辨識。
- 🙋 不確定就交人:AI 處理 90%,人專心看關鍵 10%。
最後一句:
不是「AI 取代人」,是「AI 處理 90%,人專心看那關鍵 10%」。 這才是能真正上線、可追溯、出事查得到的回單自動化。
後記:寫這篇的時候,又一個開源 OCR 登頂了
就在我整理這篇的時候,阿里又開源了 Logics-Parsing-v2——OmniDocBench 公開榜 93.23 分、自家 LogicsDocBench 82.16 分,兩個榜都第一,而且是開源模型打贏所有閉源大模型(Mathpix、doc2x 這些過去 OCR 的天花板)。它還多了一個叫「Parsing 2.0」的維度:看得懂流程圖直接輸出 Mermaid、識別樂譜轉 ABC 記譜法,連化學分子式跟程式碼塊都能處理。
我講這個不是幫它打廣告,是想說一件事:新的開源 OCR model 幾乎每隔幾週就冒一個出來,而且一個比一個猛。 前面那六個坑,有些今天還很難,但以這個速度,我會賭——很多 OCR 難題,可能今年內就被解掉一大半。
但就算如此,前面那三個 Lesson 還是不會過時。模型再強,「辨識最小化、系統最大化、不確定就交人」這套架構心法依然成立——因為那從來不是模型問題,是「怎麼設計一個可追溯、出事查得到的系統」的問題。模型負責把天花板一直往上推,架構負責讓你在天花板還沒到的時候,依然能安全上線。
常見問題 Q&A
Q:那我到底該選 OCR+Text LLM 還是 Vision LLM?
看兩件事:資安跟單據難度。機敏單據、必須資料不出公司,現階段就走 OCR + Text LLM(地端方案成熟);手寫、塗改、紅藍筆、手畫線多,而且資料可以上雲,就走 Vision LLM。實務上常常混用——清晰的單走便宜地端流程,難的才丟 Vision LLM。
Q:Vision LLM 真的能做到不用人工嗎?
不能,而且追求「全自動」這個目標本身就是錯的。它能把 90% 的重複工自動化,但簽名(法律憑證)、會出帳的數量金額、手畫線這種「沒寫進系統的規則」,一定要留人工複核。重點是讓 AI 學會舉手,而不是讓它什麼都自己拍板。
Q:影像品質爛,模型前處理救得回來嗎?
救得回「資訊還在、只是模糊」的;救不回「資訊根本沒拍進去」的。所以重點要往源頭移——拍攝 SOP + App 端即時品質檢測(太糊太暗太歪當場跳重拍),別讓爛圖進系統。AI 落地 80% 是流程與源頭,不是模型。
Q:有沒有能跑地端的 Vision LLM?還是地端就只能用 OCR+Text LLM?
有,而且 2025–2026 開源社群追得很快。地端 Vision LLM 我最看好兩個方向:Qwen2.5-VL(7B–72B,生態成熟、通用文檔強)跟 PaddleOCR-VL(0.9B,小而準、原生 OCR benchmark 打贏不少大模型、支援 109 語言)。其他像 dots.ocr、MiniCPM-V、olmOCR、DeepSeek-OCR 都可以放進候選池。但注意:地端「不成熟」這個 con 正在改善,「慢、吃 GPU」這兩個 con 還在,所以清晰的單還是建議走便宜的 OCR+Text LLM,難的才丟 Vision LLM。
Q:Tesseract、PaddleOCR、Google OCR 我該用哪個?
Tesseract 當免費 baseline(純地端、印刷為主很穩,中文跟手寫弱);PaddleOCR 是地端中文單據的首選(可部署地端、中文跟表格強);Google Cloud Vision / Document AI 辨識體驗最好、是我的最愛——但它是雲端、資料要出公司,機敏單據就不能用。簡單講:能上雲選 Google,要地端選 PaddleOCR(-VL)。
Q:為什麼不要一個 Prompt 打天下?
因為一個萬用 Prompt 會「改 A 壞 B」,每種單的欄位位置、命名、語意都不同,你永遠在拆東牆補西牆。先做格式分類、再路由到專屬 Prompt,每份 Prompt 獨立、互不干擾,新客戶只要加一個分類 + 一份 Prompt,舊的全不動。