MIT 新論文 RLM:讓 AI 不再「忘記」,但真正的瓶頸依然不是 Coding

昨天我才寫了一篇「AI Coding 半年回顧」,核心觀點是:AI Model 進步對效率影響有限,真正的瓶頸是需求收集跟 QA 驗收。
結果前幾週(2025/12/31)MIT 就發了一篇論文,正好印證了這個觀點——但不是印證「AI 沒用」,而是印證「AI 真正該解的題,終於有人在解了」。
這篇論文在講什麼?
MIT CSAIL 團隊在 2025 年 12 月 31 日發布了 Recursive Language Models (RLMs)。
核心要解決的問題叫做 Context Rot(上下文腐爛)。
什麼是 Context Rot?
你有沒有發現,雖然現在的 LLM 號稱支援 100K 甚至 1M token 的 context window,但實際用起來:
- 中間資訊會被忘記:塞進去 50 頁文件,問中間第 23 頁的細節,AI 經常答不出來
- 成本貴到爆:把整本技術手冊塞進 prompt,一次 query 可能燒掉好幾美金
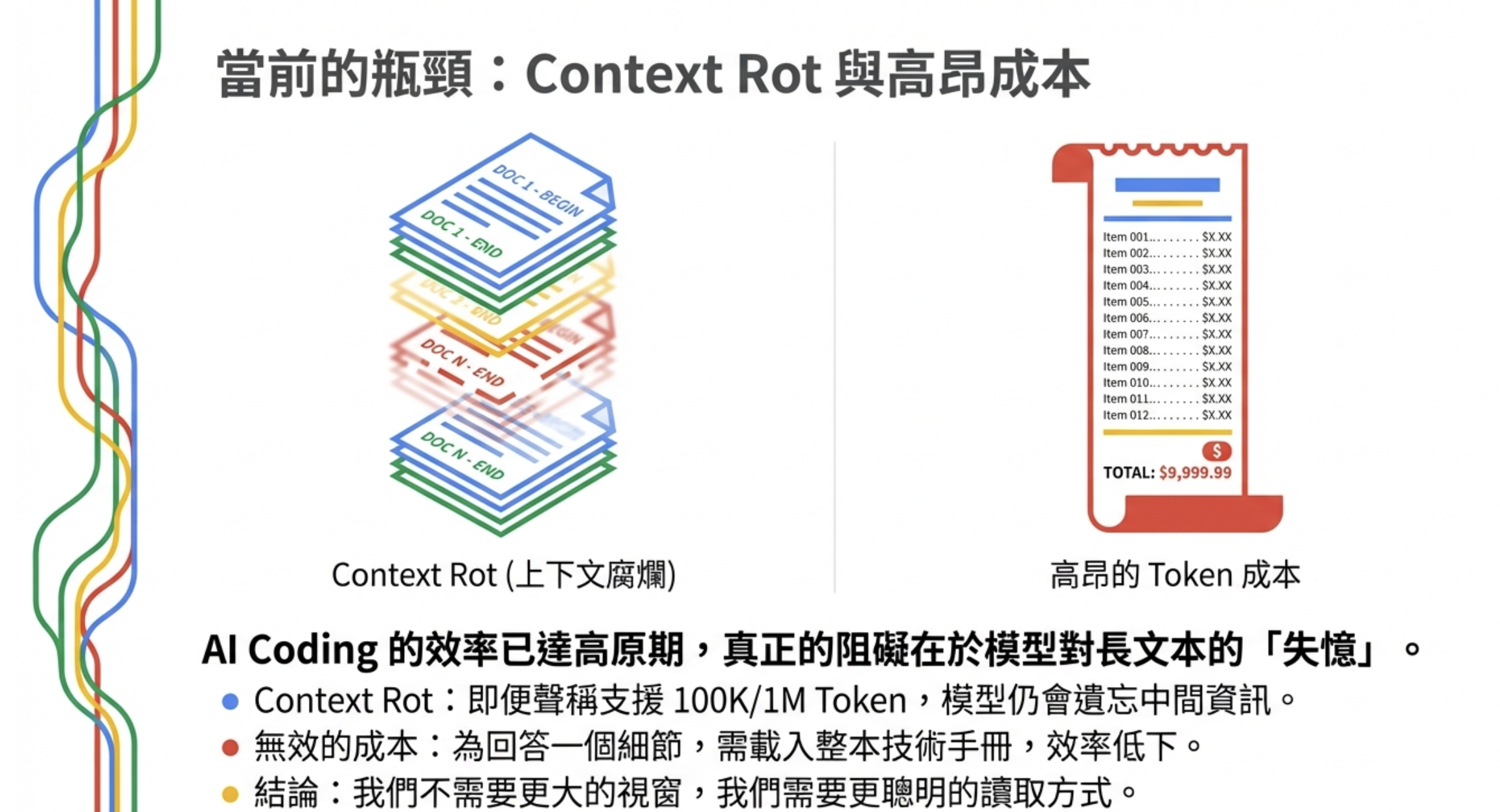
這就是 Context Rot——模型的「有效記憶」遠比「聲稱的 context window」短。
RLM 的解法:讓 AI 變成研究員
傳統做法是把所有資料一次塞進去,像在考驗背書能力。
RLM 的做法完全不同:
- 把長文本存在外部環境(像變數一樣)
- AI 可以寫 Python 程式來「切片」、「檢索」、「跳轉」
- 最關鍵的:AI 可以遞歸調用自己來處理子問題
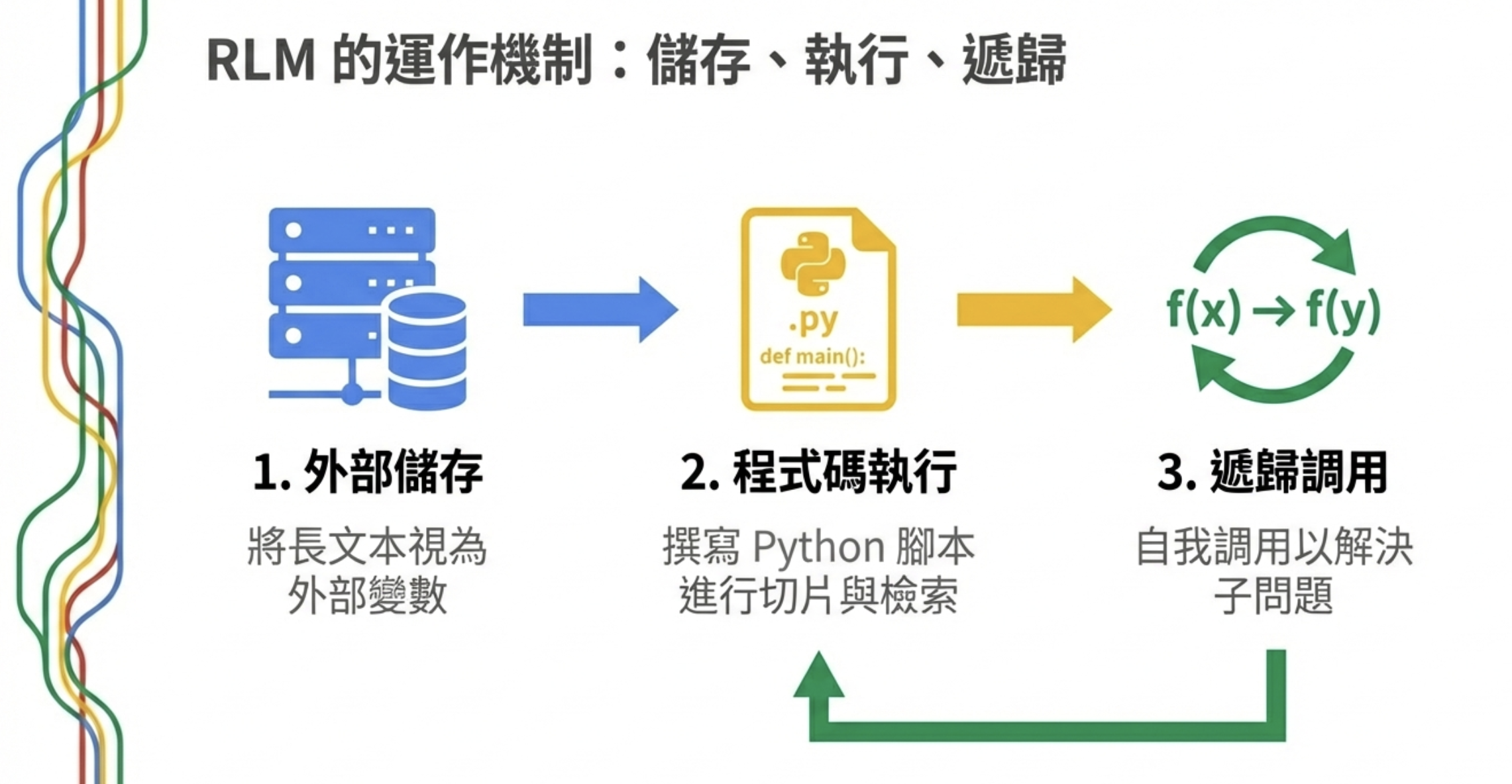
簡單講,傳統 LLM 是死背整本百科全書再回答問題;RLM 是一個會查目錄、翻到特定章節、把子問題分派給助手的研究員。
為什麼這讓我興奮?
根據我昨天說的,AI Coding 的真正瓶頸從來不是「AI 不夠聰明」或「AI 看不懂 code」,而是:
- 需求不清楚:AI 不知道你要幹嘛
- 驗收沒標準:做完不知道對不對
這兩個問題,傳統 LLM 根本解不了——因為這需要「理解全局 + 邏輯推理」,不是單純的「機率生成」。
RLM 這篇論文讓我興奮的點就在這:它終於有機會透過超長上下文的遞歸讀取機制,開始撬動這兩個天險。
RLM 對 Spec 理解的幫助:自動化「考古」
你接手一個 5 年的 Legacy 系統,文件有,但肯定沒 update,原作者早就離職了。
傳統 AI 的做法:你餵它舊文件,它根據舊文件一本正經地胡說八道。
RLM 不一樣——它靠對超長上下文的遞歸式理解,同時對程式碼和舊文件進行交叉比對,找出真正的 Spec。這剛好是人最難做到的事:
- 讀舊文件,得知「理論上」系統該做什麼
- 掃描實際 codebase(Ground Truth)
- 遞歸追蹤函數調用鏈,深入到 database schema、甚至 10 年前的 SQL migration
- 生成差異報告:「文件說 `calculate_tax` 用 5% 稅率,但 `patch_2023.py` 的裝飾器已經覆寫成動態稅率了。」
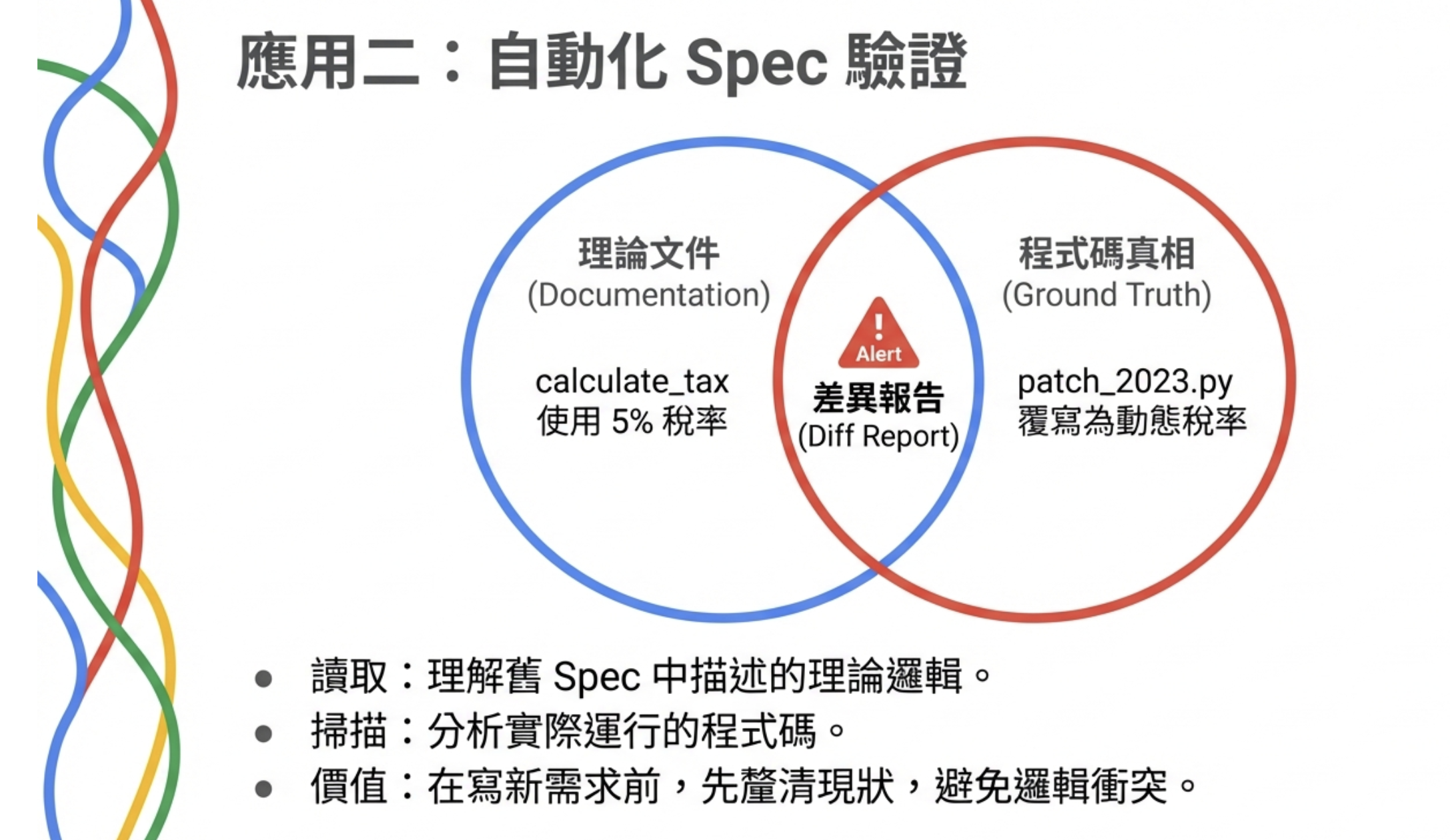
連 magic number 也能挖出來——`if (type == 7)` 是什麼意思?RLM 會去翻 commit log 告訴你:「7 代表『已凍結帳戶』,建議重構為常數。」人類工程師要做這件事,得花幾週翻遍整個 codebase;RLM 幾分鐘就能交出差異報告。
如果說理解 Spec 是「通靈」,那 RLM 做的就是幫你通靈前的準備工作,焚香沐浴、吃齋念佛——讓真正的通靈者(PM)可以直接起乩決策,而不是先花三週考古。人在Spec的取捨上,這方面的功用還是難以取代,但 RLM 已經讓整件事變得順暢太多了。
RLM 對 QA 的幫助
RLM 對 QA 的幫助很大——它可以靠超長上下文的遞歸讀取能力,快速翻遍 codebase、文件、甚至 git log,找出人類容易遺漏的測試盲區。
跨檔案依賴追蹤
當你要修改一個核心函數時,RLM 可以遞歸追蹤所有 Call Graph:
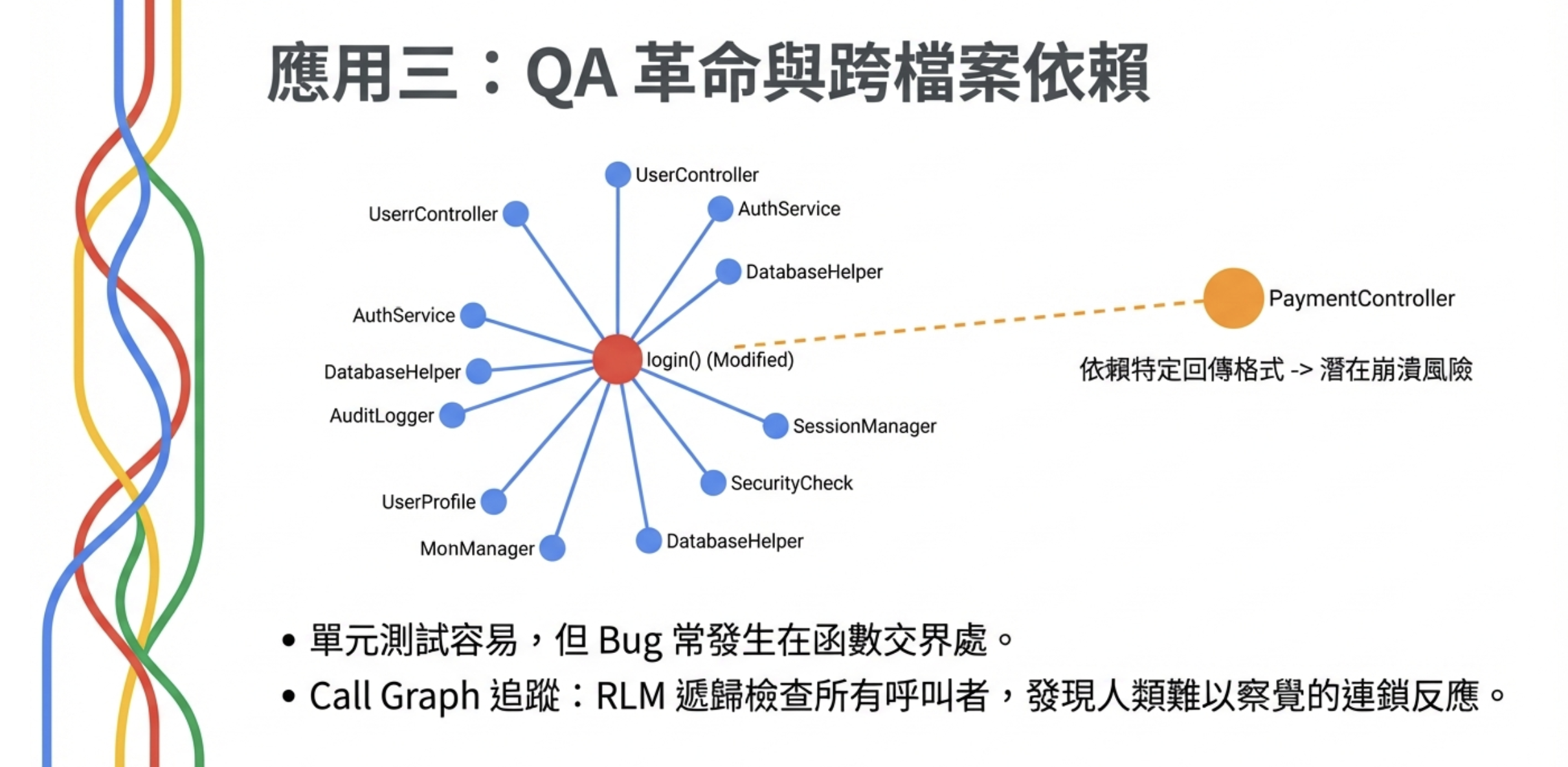
``` RLM: 我發現 login() 被 50 個檔案呼叫。 其中 49 個沒問題,但 PaymentController 依賴這個函數的特定回傳格式。 如果你改了回傳型別,計費系統會崩潰。 ```
Debug Stack Trace
遇到 Bug 時,RLM 可以從報錯點逆向追蹤,穿過幾十個檔案,找到邏輯斷裂的源頭。
生成「真正的」整合測試
這才是 RLM 在 QA 領域的真正價值。
單元測試只測一個函數,但 Bug 常發生在函數交界處。
情境:測一個「使用者下單」API。
RLM 的思考過程:
``` Root: 閱讀 API Controller ├─ Recursion 1: InventoryService(找出「庫存不足」邊界條件) ├─ Recursion 2: PaymentGateway(分析支付失敗回傳碼) └─ 生成 Test Case: 「當庫存剩 1 且支付網關回傳 Timeout 時, 系統應該回滾庫存並鎖定訂單。」 ```
這種跨模組的複雜測試案例,傳統 AI 寫不出來,因為它看不到全局。人可以做到,但需要非常資深的 QA 工程師,加上對 Spec 非常熟的 PM 一起配合才行——這組合在現實中可遇不可求。
邊界案例自動挖掘
人類 QA 測試時憑經驗(輸入 -1 或 null),但容易漏掉特定邏輯的邊界。
RLM 掃描程式碼中的 `if` 判斷式:
```python if (total_amount > 10000 && user.is_vip): ```
自動生成測試案例:「金額剛好 10000 且是 VIP」的情況。
Benchmark 結果:準確率完勝,但有代價
論文用 LOCOMO(LOng COntext MOdeling)測試集做了嚴謹的評估。
準確率
| 方法 | 短文本 (<10k) | 極長文本 (>100k) |
|---|---|---|
| Full-Context LLM | 高 | 急劇下降(Context Rot) |
| RAG | 中等 | 一直低(斷章取義) |
| RLM | 高 | 維持高檔 |
成本
情境:回答 500 頁技術手冊的問題
- Full Context:100k tokens(貴)
- RLM:可能只需 5k tokens(只讀相關章節)
節省 10-100 倍 Token 成本。
唯一缺點:延遲
因為 RLM 是「遞歸」執行(讀 → 思考 → 再讀),它是串行的。
相比 Full Context 一次性並行處理,RLM 比較慢。
Trade-off 很清楚:要快選 Full Context,要準又便宜選 RLM。
這跟昨天的文章有什麼關係?
回到我昨天寫的觀點:
AI Model 的進步,對 Coding 效率沒有太多影響。真正的瓶頸是需求收集跟 QA 驗收。
RLM 這篇論文正好印證這個方向:
- 對 Coding 本身:幫助有限,工程師本來就能做
- 對 Spec 理解:逆向工程老舊系統,這是人類做不到的速度
- 對 QA 測試:跨模組整合測試、邊界案例挖掘,這是人類容易遺漏的
AI 的進化方向,正在從「幫你寫 code」轉向「幫你理解系統、驗收品質」。
這才是對的方向。
我的觀點
這篇論文是 2026 年 AI 推理範式的重要轉折。
它證明了:不需要更大的 context window,而是讓模型具備「操作數據」和「遞歸思考」的能力,就能更有效解決超長文本理解問題。
但對於實戰中的 AI Coding,我依然認為:
技術突破很棒,但企業真正需要的是:怎麼把客戶需求變成清楚的 PRD,以及怎麼驗收 AI 產出的程式碼。
這兩個問題,目前還沒有 AI 能完全解決。
但 RLM 至少給了一個方向:讓 AI 變成那個「最懂系統的資深工程師」,幫你檢查盲點、挖掘邊界案例、追蹤依賴鏈。
剩下的「通靈」工作——理解客戶真正想要什麼——還是得靠人。
常見問題 Q&A
Q: RLM 跟 RAG 有什麼不同?不都是「不把全部資料塞進去」嗎?
表面上很像,但核心差異在於「誰在控制檢索」。RAG 是先用 embedding 找到「可能相關」的片段,再餵給 LLM;問題是 embedding 不懂邏輯,常常撈到表面相似但語意不對的內容。RLM 是讓 LLM 自己決定要讀什麼、怎麼讀,而且可以遞歸深入——讀完 A 發現需要 B,再去讀 B。這就像 RAG 是讓圖書館員幫你找書,RLM 是讓研究員自己翻。
Q: RLM 現在能用了嗎?有現成的工具嗎?
論文剛發布(2025/12/31),目前還沒有成熟的商用工具。但這個概念已經在一些 Agent 框架中看到雛形,像是 Claude 的 Computer Use 讓 AI 可以操作外部環境,其實就是類似的思路。我預期 2026 年會有更多基於 RLM 架構的工具出現,到時候再來更新實測心得。
Q: 延遲是串行的,那 RLM 適合什麼場景?
不適合即時對話(chatbot),但非常適合「批次分析」任務:Legacy 系統考古、Spec 逆向工程、大規模 Code Review、整合測試生成。這些任務本來就不是秒級回應,跑個幾分鐘換來準確率跟成本優勢,完全划算。
Q: 你說 RLM 對 Coding 本身幫助有限,那它到底解決什麼問題?
解決的是「理解」問題,不是「生成」問題。現在 AI 寫 code 已經夠快了,瓶頸在於它不知道該寫什麼、寫完對不對。RLM 讓 AI 可以真正「讀懂」一個複雜系統的全貌,這對 Spec 理解跟 QA 驗收是降維打擊。打個比方:傳統 LLM 是會打字的秘書,RLM 是會做研究的分析師。
Q: 成本省 10-100 倍是真的嗎?
論文的測試場景是「500 頁技術手冊」,從 100k tokens 降到 5k tokens。但這是理想情況——如果問題需要掃描整份文件才能回答,省不了多少。實際省多少取決於問題的「局部性」:問題越聚焦,省越多;問題越發散,優勢越小。
延伸閱讀:
論文資訊:
- 標題:Recursive Language Models
- 作者:Alex L. Zhang, Tim Kraska, Omar Khattab 等(MIT CSAIL)
- 發布日期:2025-12-31
- arXiv:2512.24601