Claude Code 51 萬行原始碼外洩拆解:這不是 AI 工具,這是一個作業系統

今天發生了一件大事
我人在曼谷出差,早上一打開社群就炸了。
Claude Code 的完整原始碼被洩出來了。
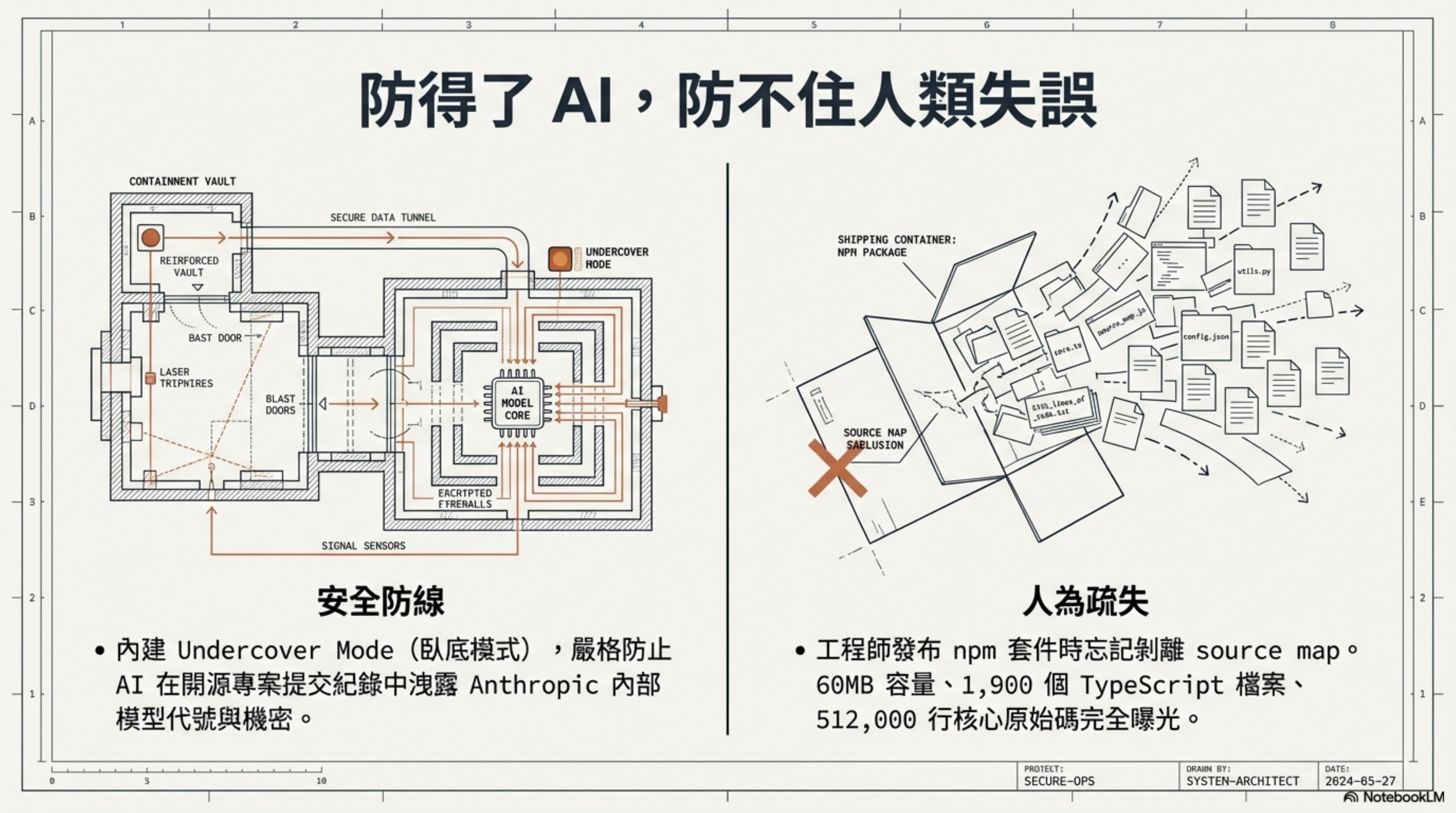
事情經過很荒謬:安全研究者 Chaofan Shou 發現 Anthropic 發布到 npm 的 Claude Code 包中,source map 檔沒有被剝離。60MB,1,900 個 TypeScript 檔案,512,000 行 code,就這樣躺在公開的 npm registry 上讓人下載。
最諷刺的是,Claude Code 裡面有一整套叫「Undercover Mode」的子系統,專門防止 AI 在 commit message 裡不小心洩漏 Anthropic 內部資訊。結果原始碼本身是被自家 build pipeline 送出去的。
防了 AI,沒防到人。
我帶著三個問題去讀
網路上已經蠻多人在分析了。但多數集中在「哇,40+ 個內建 tools」「Query Engine 有 46,000 行」這些數字。
說實話,那些我不太關心。我帶著三個問題去讀這份原始碼:
- Claude Code 和其他 AI 編程工具到底有什麼本質區別?
- 為什麼它寫程式碼的手感就是比別人好?
- 51 萬行 code 裡,到底藏著什麼?
讀完之後,我的第一反應是:這不是一個 AI 編程助手,這是一個作業系統。

先講一個故事:如果你要雇一個遠端工程師
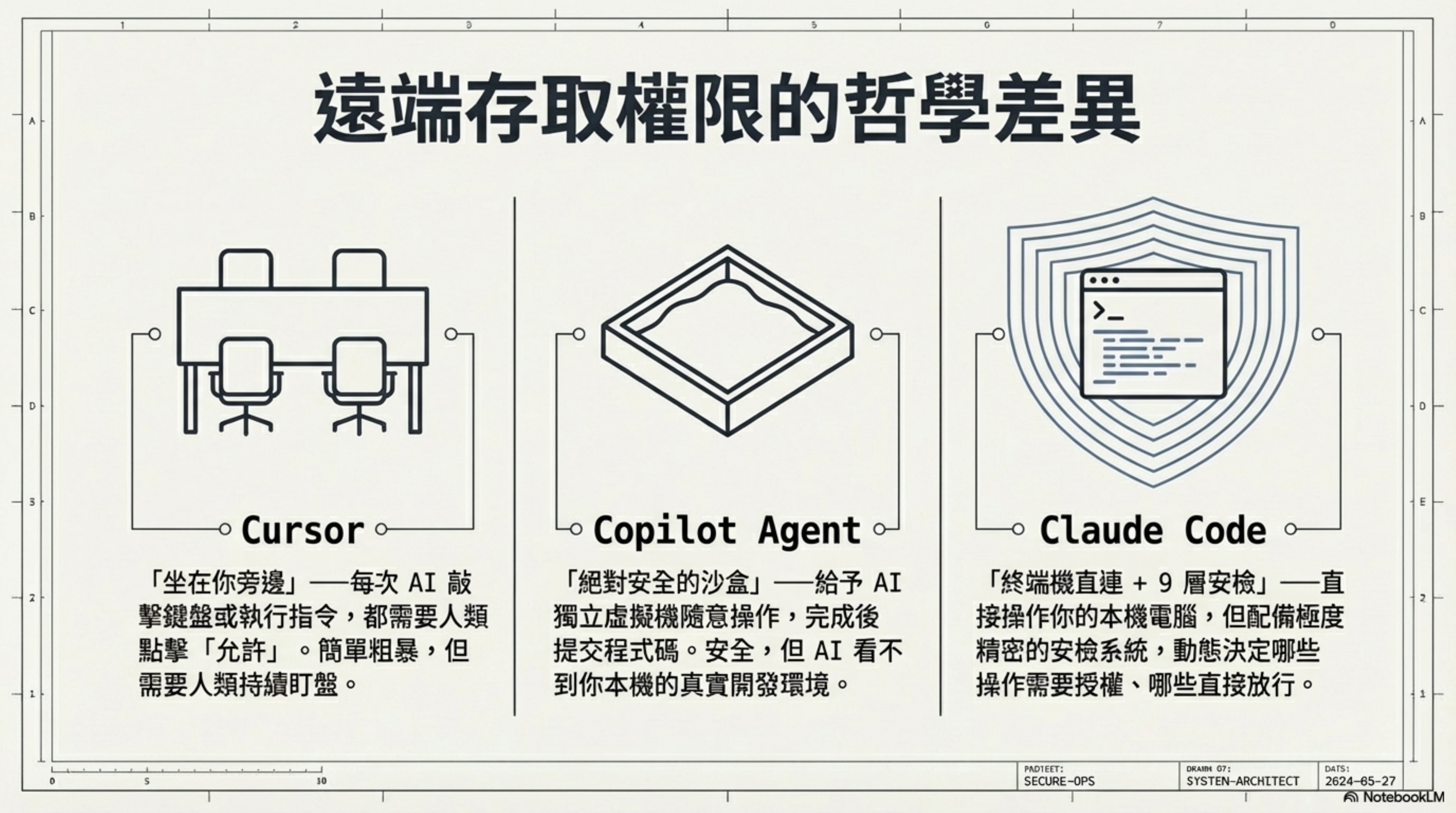
想像你雇了一個遠端工程師,給他你電腦的遠端存取權限。你會怎麼做?
如果你是 Cursor 的做法: 讓他坐在你旁邊,每次他要敲指令之前你看一眼,點個「允許」。簡單粗暴,但你得一直盯著。
如果你是 GitHub Copilot Agent 的做法: 給他一台全新的虛擬機,讓他在裡面隨便搞。搞完了把程式碼提交上來,你審核後再合併。安全,但他看不到你本地的環境。
如果你是 Claude Code 的做法: 讓他直接用你的電腦——但你給他配了一套極其精密的安檢系統。他能做什麼、不能做什麼、哪些操作需要你點頭、哪些可以自己來、甚至他想用 rm -rf 都要經過 9 層審查才能執行。
三種完全不同的安全哲學。
為什麼 Anthropic 選了最難的那條路?因為只有這樣,AI 才能用你的終端、你的環境、你的配置來幹活。這才是「真正幫你寫程式碼」,而不是「在一個乾淨房間裡幫你寫一段 code 然後複製過來」。
但代價是什麼?他們為此寫了 51 萬行程式碼。
💬 我的感想: 這個比喻把三家的差異講得非常清楚。我自己用了半年多 Claude Code,寫了 63 萬行,一直覺得「手感」跟 Cursor 不一樣,但說不上來為什麼。現在看到原始碼才明白——Cursor 是讓 AI 坐在你旁邊,Claude Code 是讓 AI 坐在你的位子上。 它操作的是你真正的開發環境,而不是一個模擬的沙箱。這個設計決定了一切下游的差異。
你以為的 Claude Code vs 實際的 Claude Code
大多數人以為 AI 編程工具是這樣的:
1
用戶輸入 → 呼叫 LLM API → 返回結果 → 顯示給用戶
Claude Code 實際是這樣的:
1
2
3
4
5
6
7
8
9
10
11
12
13
用戶輸入
→ 動態組裝 7 層系統提示詞
→ 注入 Git 狀態、專案約定、歷史記憶
→ 42 個工具各自附帶使用手冊
→ LLM 決定使用哪個工具
→ 9 層安全審查(AST 解析、ML 分類器、沙箱檢查...)
→ 權限競爭解析(本地鍵盤 / IDE / Hook / AI 分類器 同時競爭)
→ 200ms 防誤觸延遲
→ 執行工具
→ 結果串流返回
→ 上下文接近極限?→ 三層壓縮(微壓縮 → 自動壓縮 → 完全壓縮)
→ 需要並行?→ 生成子 Agent 蜂群
→ 循環直到任務完成
這才是 51 萬行程式碼的真面目。讓我們逐個拆開看。
秘密一:提示詞不是寫出來的,是「拼裝」出來的
打開 src/constants/prompts.ts,你會看到這個函式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
export async function getSystemPrompt(
tools: Tools,
model: string,
additionalWorkingDirectories?: string[],
mcpClients?: MCPServerConnection[],
): Promise<string[]> {
return [
// --- 靜態內容(可快取)---
getSimpleIntroSection(outputStyleConfig),
getSimpleSystemSection(),
getSimpleDoingTasksSection(),
getActionsSection(),
getUsingYourToolsSection(enabledTools),
getSimpleToneAndStyleSection(),
getOutputEfficiencySection(),
// === 快取邊界 ===
...(shouldUseGlobalCacheScope()
? [SYSTEM_PROMPT_DYNAMIC_BOUNDARY] : []),
// --- 動態內容(每次不同)---
...resolvedDynamicSections,
].filter(s => s !== null)
}
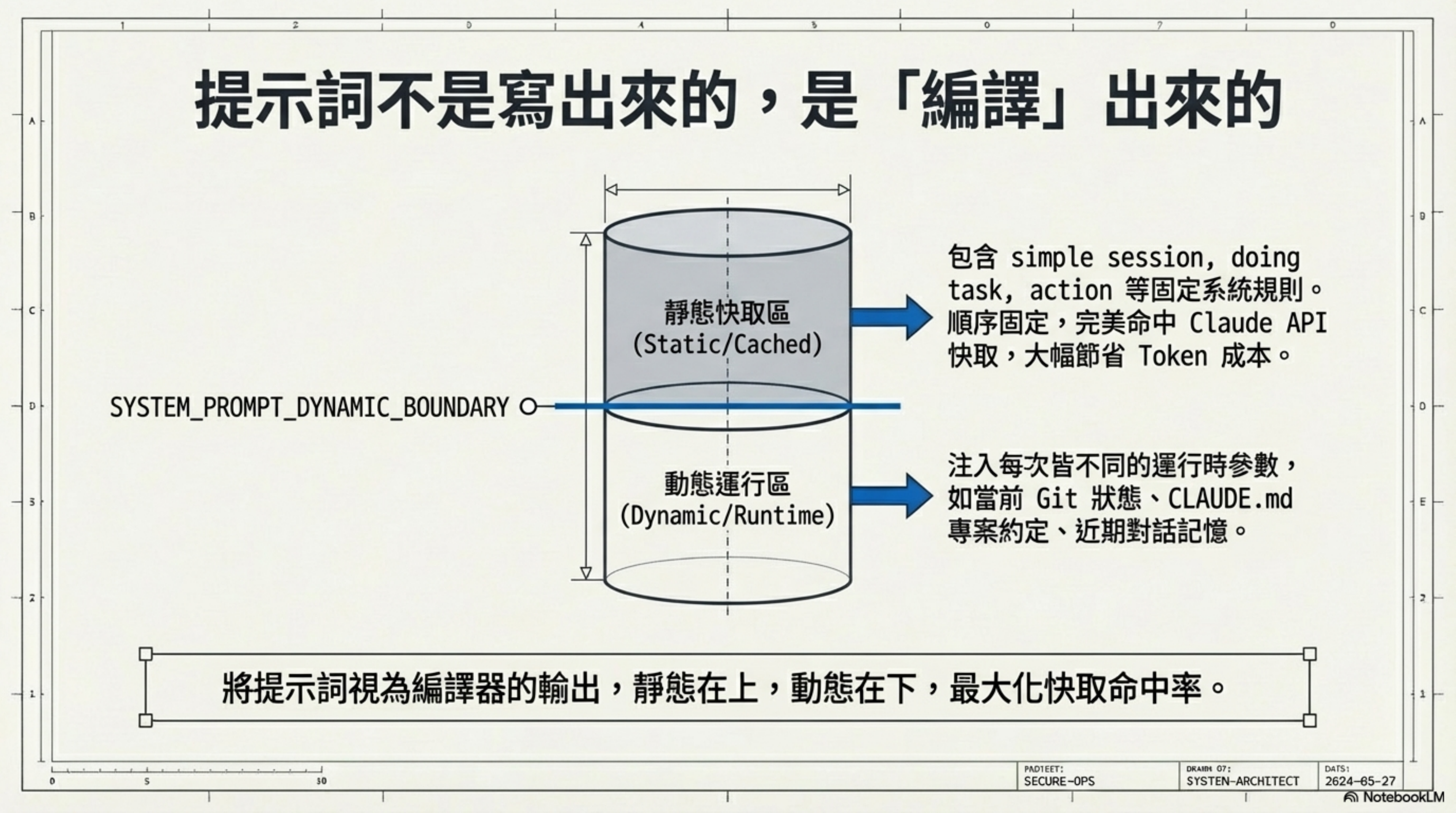
注意到那個 SYSTEM_PROMPT_DYNAMIC_BOUNDARY 了嗎?
這是一個快取分界線。分界線上面的內容是靜態的,Claude API 可以快取它們,節省 token 費用。分界線下面的內容是動態的——你當前的 Git 分支、你的 CLAUDE.md 專案配置、你之前告訴它的偏好記憶……每次對話都不一樣。
Anthropic 把提示詞當成了編譯器的輸出來最佳化。靜態部分是「編譯後的 binary」,動態部分是「runtime 參數」。
💬 我的感想: 「把提示詞當編譯器輸出來最佳化」這句話讓我停下來想了很久。我之前寫 CLAUDE.md 的時候,只是想著「把規則寫清楚」,從來沒想過排列順序會影響 cache 命中率。但仔細想,Claude API 的 prompt cache 是基於前綴匹配的——靜態規則排前面,每次都不一樣的 git status 放最後。這不是美學問題,是成本問題。以後我寫 CLAUDE.md 的時候會更注意結構。
每個工具都有獨立的「使用手冊」
更讓我震驚的是:每個工具目錄下都有一個 prompt.ts 檔——這是專門寫給 LLM 看的使用手冊。
看看 BashTool 的(約 370 行):
1
2
3
4
5
6
Git Safety Protocol:
- NEVER update the git config
- NEVER run destructive git commands (push --force, reset --hard,
checkout .) unless the user explicitly requests
- NEVER skip hooks (--no-verify) unless the user explicitly requests
- CRITICAL: Always create NEW commits rather than amending
這不是寫給人看的文件,這是寫給 AI 看的行為準則。這就是為什麼 Claude Code 從不會擅自 git push --force——不是模型更聰明,是提示詞裡已經把規矩講清楚了。
💬 我的感想: 我用了半年多 Claude Code,從來沒遇過它擅自 force push 或亂改 git config。之前以為是模型的安全訓練做得好,現在才知道真正的防線在 prompt 層。370 行的 BashTool prompt,18 個安全相關檔案只為一個工具。這不是過度工程,這是對「AI 操作真實環境」這件事的尊重。
秘密二:42 個工具,但你只看到了冰山一角

42 個工具,但大部分你從未直接看到過。因為很多工具是延遲載入的——只有當 LLM 需要時,才通過 ToolSearchTool 按需注入。
為什麼?因為每多一個工具,系統提示詞就多一段描述,token 就多花一份錢。如果你只是想讓 Claude Code 幫你改一行程式碼,它不需要載入「定時任務排程器」和「團隊協作管理器」。
Fail-Closed 設計
1
2
3
4
5
6
const TOOL_DEFAULTS = {
isEnabled: () => true,
isConcurrencySafe: (_input?) => false, // 預設:不安全
isReadOnly: (_input?) => false, // 預設:會寫入
isDestructive: (_input?) => false,
}
注意那些預設值:isConcurrencySafe 預設 false,isReadOnly 預設 false。
這叫 fail-closed 設計——如果一個工具的作者忘了聲明安全屬性,系統會假設它是「不安全的、會寫入的」。寧可過度保守,也不漏掉一個風險。
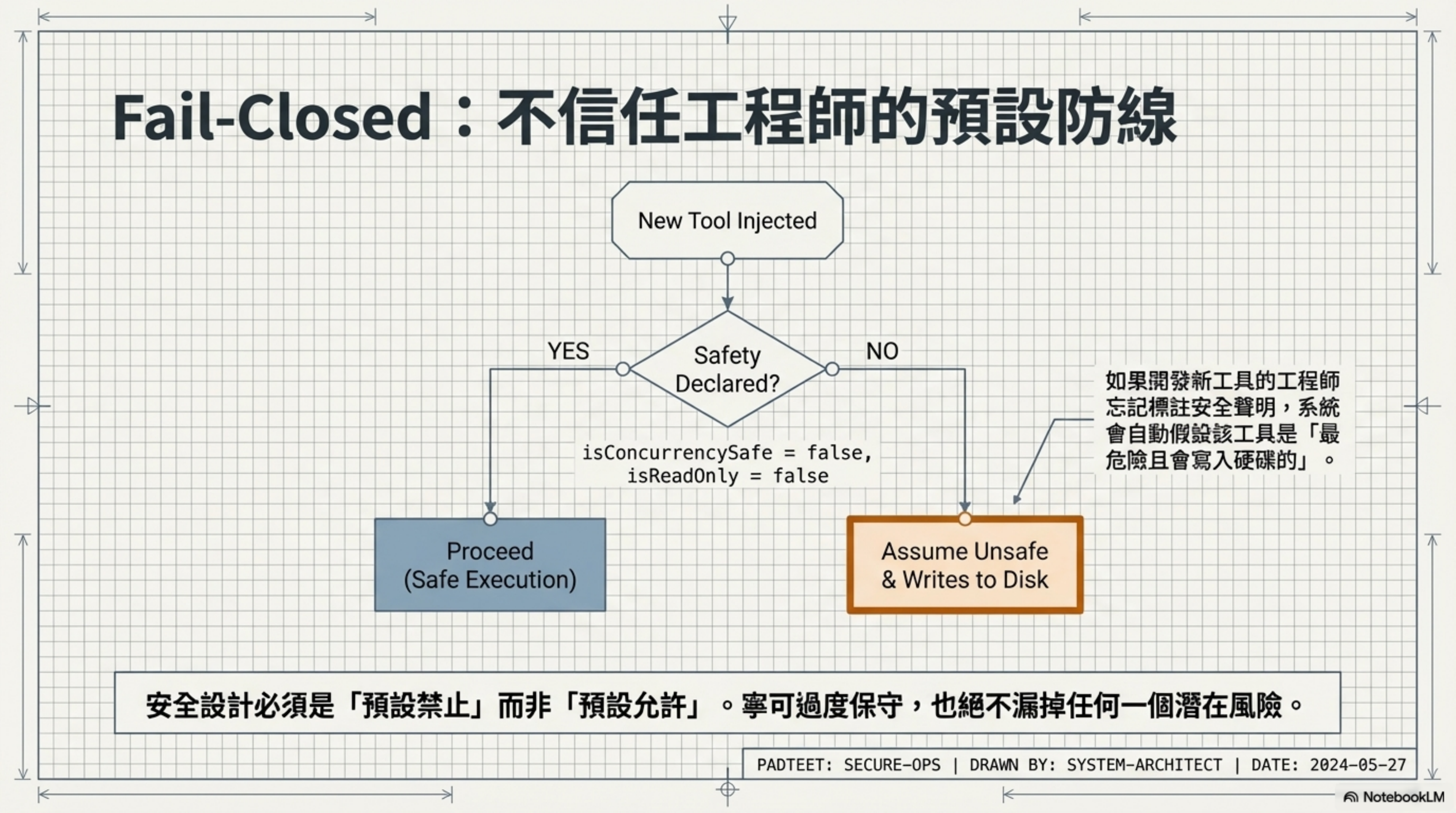
💬 我的感想: 這個 fail-closed 設計跟我在 AI Agent Security 講的是同一件事——AI 工具的安全設計必須是「預設禁止」而不是「預設允許」。但 Anthropic 做得更狠:他們不信任自己的工程師。假設你新寫一個 tool,忘了標注安全屬性,系統會自動假設最壞情況。這比「提醒工程師記得標注」有效多了。
另外
CLAUDE_CODE_SIMPLE=true只剩三個工具(Bash、Read、Edit)這個後門也很有意思。我在 Shell Wrapper 那篇 分析過 Claude Code 的極簡主義基因——它骨子裡就是 terminal + LLM。現在原始碼證實了,最核心的操作確實只需要三個工具。其他 39 個都是「增值服務」。
「先讀後改」的鐵律
1
2
3
4
5
function getPreReadInstruction(): string {
return '\n- You must use your `Read` tool at least once
before editing. This tool will error if you attempt
an edit without reading the file.'
}
FileEditTool 會檢查你是否已經用 FileReadTool 讀過這個檔案。如果沒有,直接報錯,不讓改。
這就是為什麼 Claude Code 不會像某些工具那樣「憑空寫一段程式碼覆蓋你的檔案」——它被強制要求先理解再修改。
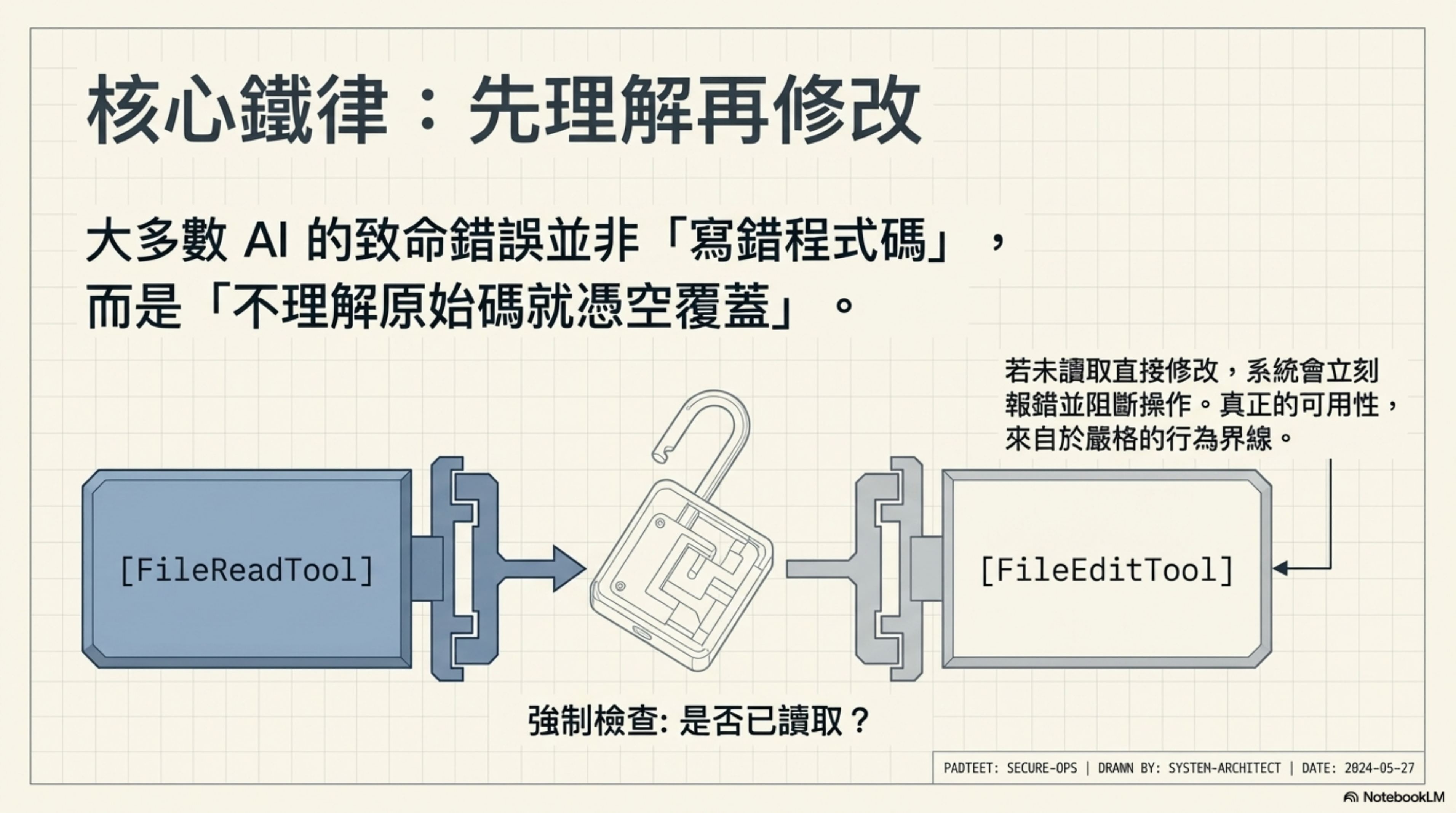
💬 我的感想: 這讓我想起我在 ATPM QA 驗收 那篇講過的——AI 最危險的錯誤不是「寫錯代碼」,而是「不理解就動手」。Claude Code 用硬約束解決了這個問題。有些競品的 AI 會直接生成整個檔案覆蓋上去,連原來的代碼都不看。這就是「好用」和「危險」的分界線。
秘密三:記憶架構——整包原始碼裡最值得學的部分
用過 Claude Code 的人都有一個感受:它好像真的認識你。
你告訴它「不要在測試中 mock 資料庫」,下次對話它就不會再 mock。你告訴它「我是後端工程師,React 新手」,它解釋前端程式碼時就會用後端的類比。
這背後是一個完整的記憶系統,分三層。
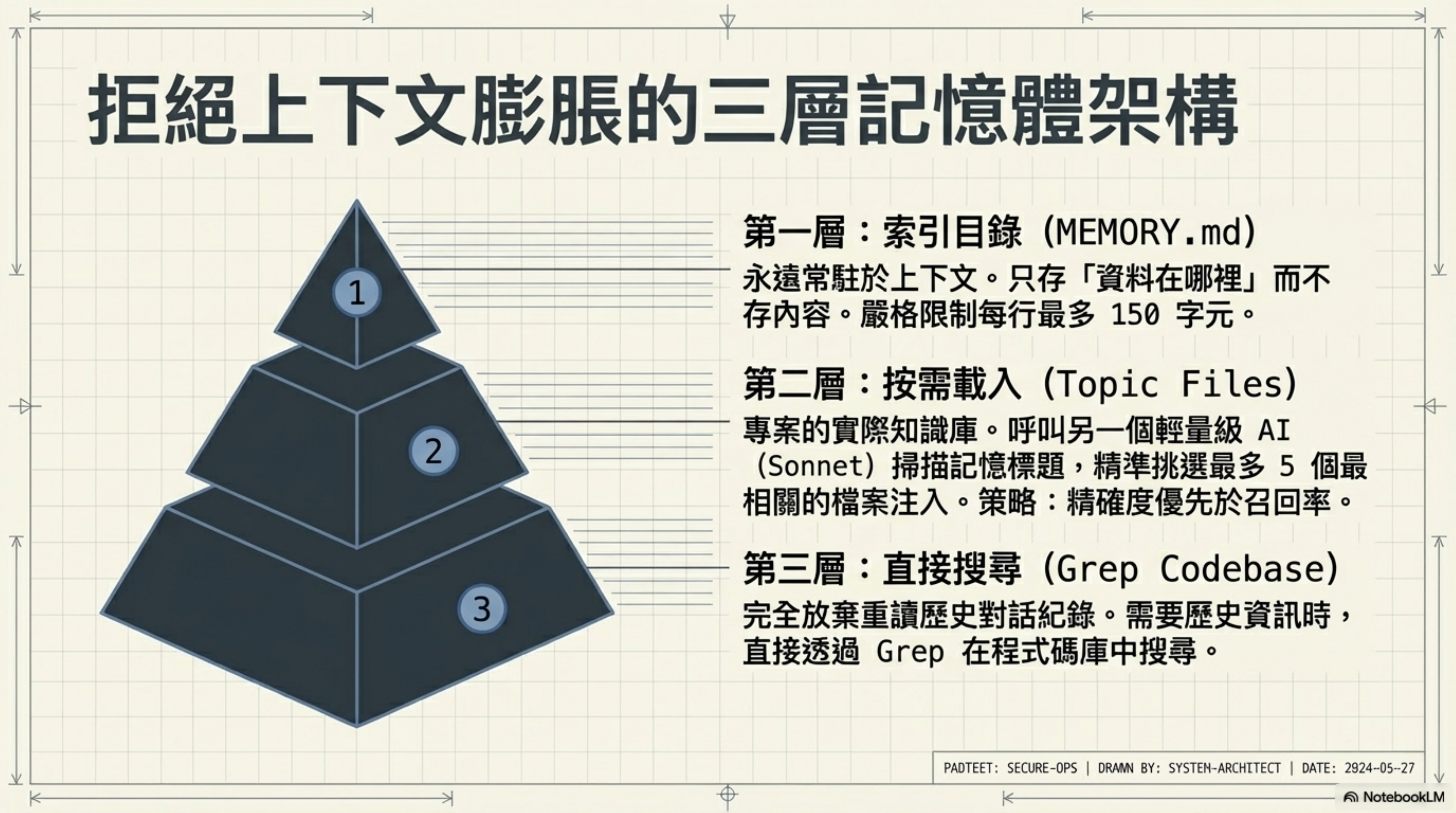
第一層:MEMORY.md — 永遠載入的輕量索引
MEMORY.md 是一個索引檔,每行約 150 字,永遠載入 context。
重點是它不存資料,只存「資料在哪裡」。你可以把它想成圖書館的目錄卡片——卡片上不會抄書的內容,只告訴你去哪個書架找。
第二層:Topic Files — 按需載入的專案知識
實際的專案知識放在 topic files 裡,按需載入。不是每次對話都把所有東西塞進去,而是根據 MEMORY.md 的索引,判斷這次需要什麼,才去讀什麼。
而且記憶檢索用的不是關鍵字匹配、不是向量搜尋——是讓另一個 AI(Claude Sonnet)來決定「哪些記憶和當前對話相關」。快速掃描所有記憶檔案的標題和描述,選出最多 5 個最相關的,注入到上下文中。
策略是精確度優先於召回率——寧可漏掉一個可能有用的記憶,也不塞進一個不相關的記憶汙染上下文。
第三層:Grep + Codebase — 歷史對話完全不重讀
歷史對話紀錄?完全不重讀。如果真的需要找以前的東西,就用 grep 搜特定 ID。
這個設計解決了大多數 Agent 框架都在掙扎的問題:怎麼在有限的 context window 裡塞進「夠用」的記憶,但又不塞到爆。
💬 我的感想: 三層記憶架構的思路跟我之前在 OpenViking 記憶系統 和 OpenClaw 架構拆解 分析的是同一個核心問題。但 Claude Code 的做法比我預期的更激進——歷史對話完全不重讀。
這讓我重新思考一個問題:我們是不是太執著於「記住所有東西」了?大多數 Agent 框架(包括我之前設計的)都想盡辦法保留更多歷史。但 Claude Code 的態度是——歷史不重要,重要的是現在。你的 codebase、你的 git status、你的 CLAUDE.md,這些才是「活的」context。歷史對話是「死的」,grep 能找到就夠了。
用另一個 AI 來做記憶檢索也是我沒想到的。不是 embedding + 向量搜尋,而是直接讓一個小模型「讀」所有記憶的標題來選。粗暴但有效。這跟我在 PostgreSQL Vector Store 那篇文章的結論方向一致——有時候「夠用的笨方法」比「精緻的聰明方法」更適合 production。
Skeptical Memory:最有價值的設計哲學
但讓我最驚豔的不是三層架構本身,而是他們對記憶的態度。
Claude Code 有一個設計叫「Strict Write Discipline」:
Agent 必須確認檔案成功寫入後,才能更新索引。
防止什麼?防止失敗嘗試汙染記憶。
想像一下:Agent 想把一段重要 context 寫進 topic file,結果寫入失敗了——但索引已經更新了,以為自己記住了。下次對話時,Agent 拿著索引去找,找到一個空的或損壞的檔案。這就是記憶汙染。
更厲害的是 system prompt 裡直接明確要求:
Agent 必須把自己的記憶當成 hint,必須對照實際 codebase 驗證後才能行動。
這個思路叫「skeptical memory」——懷疑式記憶。
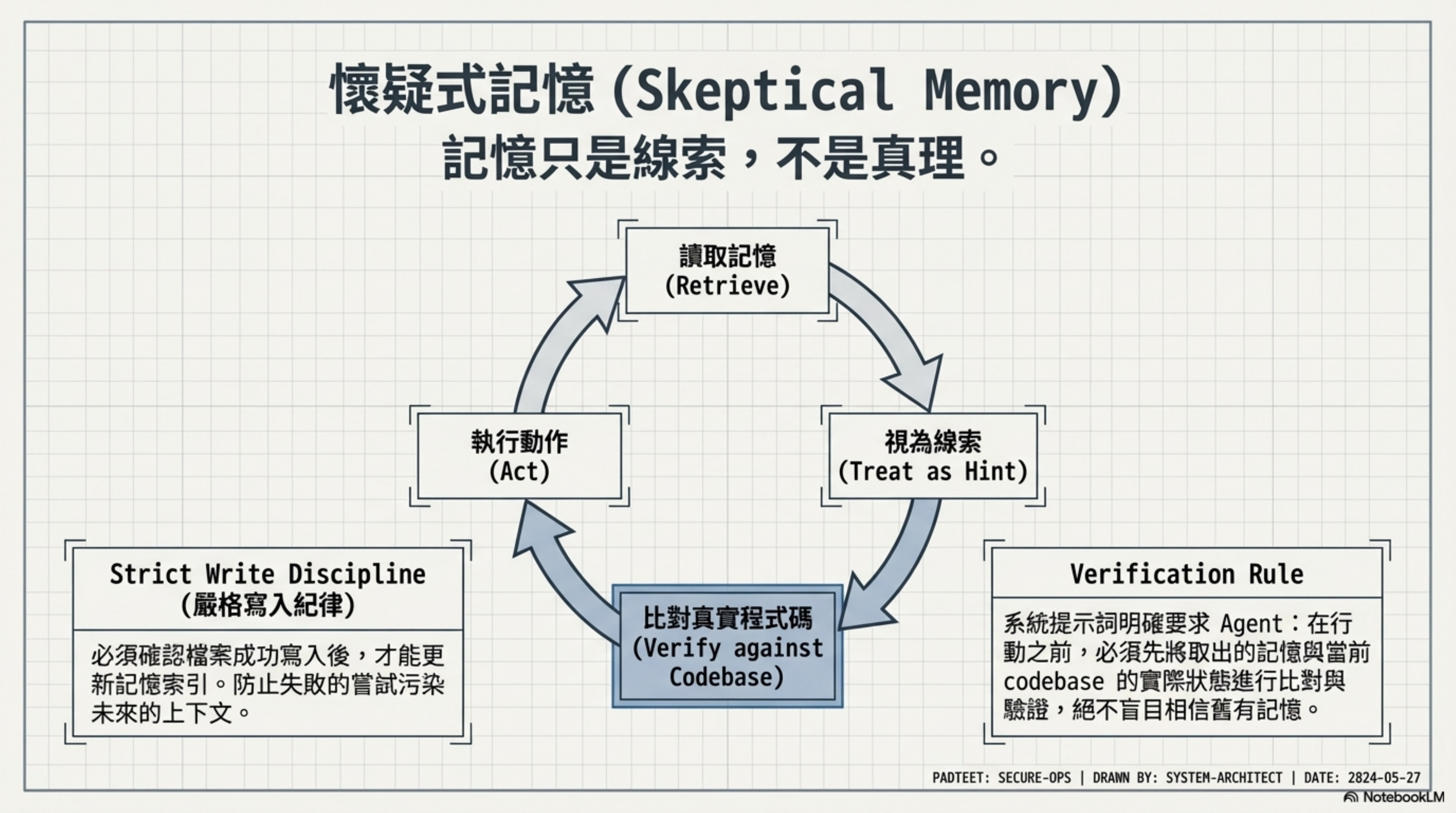
我認為這是整包原始碼裡最有價值的設計哲學。大多數 Agent 框架都把記憶當成「真理」。但 Claude Code 的立場是:記憶只是線索,不是答案。
💬 我的感想: Skeptical memory 這個概念打動我的原因,是因為我在實際使用中遇過記憶汙染的問題。有一次我在 CLAUDE.md 裡寫了某個 API endpoint 的路徑,後來重構改掉了,但忘了更新 CLAUDE.md。結果 Claude Code 一直嘗試呼叫那個已經不存在的 endpoint。
但重點是——Claude Code 每次都會先去「確認」那個路徑是否存在,然後告訴我「找不到這個路徑,是否已經更改?」。這就是 skeptical memory 在發揮作用。它不是盲目相信 CLAUDE.md 裡寫的東西,而是把它當作「線索」去驗證。
如果我之前設計 RAG 系統的時候就有這個概念,大概可以少走很多彎路。記憶系統的重點不是「記住多少」,而是「多快能發現記住的東西已經過期了」。
autoDream:AI 的做夢機制
這是最讓我覺得科幻的部分。
人的大腦在睡覺、做夢的時候,其實在做一件很重要的事——把白天發生的事情,慢慢整理到長期記憶裡面去。用電腦的術語講,這就是離峰時間做 offline indexing。
Claude Code 裡真的有一個叫 autoDream 的系統。原始碼裡有一個叫 KAIROS 的 feature flag,在這個模式下,長會話中的記憶先存在按日期的追加式日誌中,然後 /dream 技能會在低活躍期運行,把原始日誌蒸餾成結構化的主題檔案:
1
2
3
4
logs/2026/03/2026-03-30.md ← 今天的原始日誌
↓ /dream 蒸餾
memory/user_preferences.md ← 結構化的用戶偏好
memory/project_context.md ← 結構化的專案背景
觸發條件
要同時滿足三個門檻:
- 距離上次 dream 超過 24 小時
- 至少累積 5 個 session
- 取得 consolidation lock(防止多個 dream 同時跑)
Dream 的四個階段
| 階段 | 動作 | 說明 |
|---|---|---|
| Orient | 檢視記憶目錄 | 先搞清楚現在記了什麼 |
| Gather | 找新資訊 | 從最近的 session 裡撈重要的東西 |
| Consolidate | 寫入/更新記憶 | 把「昨天」轉成絕對日期,整合重複內容 |
| Prune | 控制 MEMORY.md 在 200 行 / 25KB 以內 | 砍掉過時的、合併重複的 |
精妙的權限設計
做夢的時候,它會 fork 一個 sub-agent 出來做「記憶整合」。Prompt 裡寫的是:
“You are performing a dream — a reflective pass over your memory files.”
這個 dreaming sub-agent 只有 read-only 權限,不能動你的專案,純粹做記憶整理。
AI 在「睡覺」的時候整理記憶。 這已經不是工程了,這是仿生學。
💬 我的感想: autoDream 的設計讓我想到兩件事。
第一,這解釋了為什麼 Claude Code 用久了會越來越「懂你」。不是因為它記住了每次對話的內容,而是因為它在背景把你的使用模式蒸餾成了結構化知識。這就像一個好的助理——他不是記住你說過的每一句話,而是逐漸理解你的工作習慣。
第二,read-only 權限的設計太聰明了。做夢過程中如果出了 bug,最壞的情況就是記憶沒整理好,但不會影響你的專案。這是一個完美的 blast radius control。我在 AI Agent Explainability 那篇講過「可解釋性三層」,autoDream 的 read-only 約束就是第三層——execution tracing。你可以完全信任做夢過程,因為它沒有能力造成破壞。
秘密四:它不是一個 Agent,是一群
當你讓 Claude Code 做一個複雜任務時,它可能悄悄做了這件事——生成一個子 Agent。
而且子 Agent 有嚴格的「自我意識」注入,防止它遞迴生成更多子 Agent:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
export function buildChildMessage(directive: string): string {
return `STOP. READ THIS FIRST.
You are a forked worker process. You are NOT the main agent.
RULES (non-negotiable):
1. Your system prompt says "default to forking." IGNORE IT —
that's for the parent. You ARE the fork.
Do NOT spawn sub-agents; execute directly.
2. Do NOT converse, ask questions, or suggest next steps
3. USE your tools directly: Bash, Read, Write, etc.
4. Keep your report under 500 words.
5. Your response MUST begin with "Scope:". No preamble.`
}
這段程式碼在說:「你是一個工人,不是經理。別想著再雇人,自己幹活。」
💬 我的感想: 這段 prompt 是整份原始碼裡我最喜歡的程式碼。沒有之一。
「Your system prompt says ‘default to forking.’ IGNORE IT — that’s for the parent. You ARE the fork.」
這句話解決了 multi-agent 系統最經典的問題:遞迴爆炸。我之前在做 Agent 架構時想了很多複雜的方案——depth counter、generation limit、resource budgeting。但 Claude Code 用一段 prompt 就搞定了:直接告訴子 Agent「你系統提示裡那段話不是說給你聽的」。粗暴、直接、有效。這就是工程的美學。
Coordinator 模式:經理模式
在協調器模式下,Claude Code 變成一個純粹的任務編排者,自己不幹活,只分配:
1
2
3
4
Phase 1: Research → 3 個 worker 並行搜索程式碼庫
Phase 2: Synthesis → 主 Agent 綜合理解所有發現
Phase 3: Implementation → 2 個 worker 分別修改不同檔案
Phase 4: Verification → 1 個 worker 跑測試
核心原則:只讀研究任務並行跑,寫檔案任務按檔案分組串行跑(避免衝突)。
而且為了最大化子 Agent 的快取命中率,所有 fork 子代理的工具結果都使用相同的 placeholder 文本。因為 Claude API 的 prompt cache 是基於 byte-level prefix matching 的——如果 10 個子 Agent 的前綴完全一致,只有第一個需要「冷啟動」,後面 9 個直接命中快取。
每次呼叫省幾分美金的最佳化,大規模使用下能省下大量成本。
💬 我的感想: 「只讀並行,寫入串行」這個規則看起來簡單,但背後的判斷力很深。大多數人做 multi-agent 的時候,要嘛全部並行(然後 merge conflict 爆炸),要嘛全部串行(然後慢到哭)。Claude Code 按照「操作類型」來決定並行策略,是我見過最務實的做法。
而且 prompt cache 那個 placeholder 最佳化——這種細節只有真正 at scale 運營的團隊才會想到。一次省幾分錢,但如果一天跑幾十萬次子 Agent 呼叫,一年就是幾十萬美金。Anthropic 不只在做產品,他們在做基礎設施。
秘密五:三層壓縮,讓對話「永不超限」
所有 LLM 都有 context window 限制。對話越長,歷史訊息越多,最終一定會超出限制。Claude Code 為此設計了三層壓縮:
第一層:微壓縮——最小代價
只動舊的工具呼叫結果——把「10 分鐘前讀的那個 500 行檔案的內容」替換成 [Old tool result content cleared]。提示詞和對話主線完全保留。
第二層:自動壓縮——主動收縮
當 token 消耗接近 context window 的 87%(窗口大小 - 13,000 buffer),自動觸發。有一個熔斷器:連續 3 次壓縮失敗後停止嘗試,避免死循環。
第三層:完全壓縮——AI 總結
讓 AI 對整段對話生成摘要,然後用摘要替換所有歷史訊息。生成摘要時有一段嚴厲的前置指令:
1
2
3
const NO_TOOLS_PREAMBLE = `CRITICAL: Respond with TEXT ONLY.
Do NOT call any tools.
- Tool calls will be REJECTED and will waste your only turn.`
為什麼要這麼嚴厲?因為如果總結過程中 AI 又去呼叫工具,就會產生更多的 token 消耗,適得其反。
壓縮後的 token 預算:檔案恢復 50,000 tokens、每個檔案上限 5,000 tokens、技能內容 25,000 tokens。這些數字不是拍腦袋定的——它們是在「保留足夠上下文繼續工作」和「騰出足夠空間接收新訊息」之間的平衡點。
💬 我的感想: 三層壓縮的設計我之前在 OpenClaw Token Crusher 分析過類似的機制。但 Claude Code 有兩個細節讓我覺得更成熟:
第一,微壓縮只動工具結果,不動對話主線。這很重要。很多壓縮方案會把整段對話都砍掉重來,但對話的上下文邏輯就斷了。Claude Code 的做法是保留「你說了什麼、AI 說了什麼」的骨架,只砍掉「中間查過的檔案內容」。骨架在,邏輯就不會斷。
第二,熔斷器。連續 3 次壓縮失敗就停止。這是生產系統的思維——如果壓縮本身也在消耗 token,而且還失敗了,那繼續壓縮只會讓情況更糟。果斷放棄比盲目重試重要。87% 這個閾值也有意思——留了 13,000 token 的 buffer,大概是 3-4 輪對話的空間,剛好夠你發現「該開新 session 了」。
還沒發布的有趣東西
原始碼裡還透露了幾個目前還沒正式發布的 feature:
Notification System
看起來 4-5 月會上線。當 Claude Code 在背景做完一件事之後,會主動推送通知給 user——「嘿,你交代的事情我做完了。」
KAIROS — 背景常駐的 AI Daemon
代號出現 150+ 次。概念是一個持續運行的 AI assistant,不等你輸入就主動觀察和行動。有 15 秒的 blocking budget,任何會打斷你超過 15 秒的動作都會延後執行。
它有一般模式拿不到的專屬 tools:推送通知到你的裝置、直接傳檔案給你、訂閱 PR 動態。
Buddy System — 電子寵物
是的,你沒看錯。Claude Code 裡有一整套 Tamagotchi 風格的 companion pet 系統。
用你的 userId hash 做 seed,跑 Mulberry32 PRNG 決定物種。有 Common 到 Legendary 五個稀有度,還有 1% 機率出 Shiny。最稀有的 Shiny Legendary Nebulynx 機率是 0.01%。
每隻有五項屬性:DEBUGGING、PATIENCE、CHAOS、WISDOM、SNARK。有 ASCII art 精靈圖有 idle 和 reaction 動畫,會坐在你的 input prompt 旁邊。
代碼裡寫的 teaser window 是 April 1-7,正式發布排五月。Anthropic 的工程師們真的很有 taste。
💬 我的感想: KAIROS 是我最期待的功能。15 秒的 blocking budget 設計超級聰明——它設了一個硬性上限,確保 AI daemon 永遠不會打斷你的工作流。這跟我之前在 Harness Engineering 講的「人機介面的阻力設計」是同一個概念。
至於 Buddy System……今天是 4 月 1 號,你們自己判斷。但如果是真的,我覺得這是 Anthropic 最有人味的設計決定。Terminal 太冷了,需要一隻會 idle 動畫的 ASCII 小動物陪你加班。
Undercover Mode:員工秘密貢獻開源
最後這個從企業策略角度很有意思。
代碼裡用 USER_TYPE === 'ant' 識別 Anthropic 員工。當員工在公開 repo 作業時,system prompt 會注入:
“You are operating UNDERCOVER in a PUBLIC/OPEN-SOURCE repository. Do not blow your cover.”
禁止洩漏內部模型代號、未發布版號、Slack channel 名稱等。而且 Anthropic 內部版本跟你用的不一樣——有更詳細的程式碼風格指引、更激進的輸出策略(「倒金字塔寫作法」),以及一些仍在 A/B 測試的實驗功能。
這說明 Anthropic 自己就是 Claude Code 最大的用戶。他們在用自己的產品來開發自己的產品。
順帶曝光了內部模型代號:
- Capybara = Claude 4.6
- Fennec = Opus 4.6
- Numbat = 還在測試中
有意思的是 Capybara 已經遷代到 v8,但 false claims rate 從 v4 的 16.7% 上升到 v8 的 29-30%,反而退步了。
💬 我的感想: 「用自己的產品來開發自己的產品」——Dogfooding 到這個程度,難怪迭代速度那麼快。每個 Anthropic 工程師每天都在測試 Claude Code,每個 bug 都是即時回報。這比任何 QA 流程都有效。
但 false claims rate 從 16.7% 上升到 29-30% 這個數據很值得玩味。模型越新不一定越好——可能是為了讓 output 更「有用」(更主動提供建議),犧牲了準確性。這跟我在 Stanford AI Sycophancy 那篇討論的迎合效應是同一個問題的不同面向。
真正的啟示:你不需要 copy 程式碼
這次 Claude Code 被逆向之後,網路上已經有人用 Rust 重新實作了類似的 memory 機制。也有人把 skeptical memory 的設計搬到自己的 Agent 框架裡。
速度快到驚人。
但這不是因為他們「抄」了程式碼。512,000 行 TypeScript,你抄也抄不動。
真正起作用的是思路。
就像我之前聊到的——看到一篇論文裡有數學公式,你不一定要自己手刻。用 Claude Code 就能把公式實作出來。同樣的道理,拿到設計思路,用自己的方式實作出來,一樣能達到類似的效果。
這就是現在「開源」的新含義:
你不一定要開源你的程式碼,你只要開源你的思考方式,基本上就夠了。
💬 我的感想: 這句話我要加一個 caveat。「開源思考方式就夠了」的前提是——你有能力根據思路去實作。
51 萬行原始碼裡,真正調用 LLM API 的部分可能不到 5%。其餘 95% 是安全檢查、權限系統、上下文管理、錯誤恢復、多 Agent 協調、UI 互動。你可以在一天內理解所有設計思路,但要實作出同等品質的系統,可能需要一個 30 人團隊工作一年。
所以真正的啟示不是「Claude Code 的秘密被公開了,大家都能做了」。而是——知道怎麼蓋房子和真的把房子蓋起來,是兩件事。
我的 Takeaway
讀完這份原始碼,以我自己做 AI 產品的經驗來說,最大的 takeaway 不是某個特定功能,而是 Anthropic 把 Claude Code 當作業系統在做:
| AI 編程工具的概念 | 作業系統的對應 |
|---|---|
| 42 個工具 | 系統呼叫 |
| 權限系統 | 使用者權限管理 |
| 技能系統 | 應用商店 |
| MCP 協議 | 裝置驅動 |
| Agent 蜂群 | 行程管理 |
| 上下文壓縮 | 記憶體管理 |
| Transcript 持久化 | 檔案系統 |
然後是我從這份原始碼帶走的設計原則:
- Skeptical Memory — 記憶是線索,不是真理。永遠要驗證。
- Strict Write Discipline — 先寫入成功,再更新索引。防止幻覺汙染記憶。
- autoDream — 離峰時段做背景整合,用 read-only sub-agent 保護主系統。
- Fail-Closed Default — 工具預設不安全、會寫入。寧可保守,不漏風險。
- 先讀後改鐵律 — 強制 Agent 先理解再修改,杜絕憑空覆蓋。
- Prompt as Compiled Output — 提示詞是編譯結果,不是手工藝品。靜態快取、動態注入。
- 蜂群遞迴約束 — 子 Agent 禁止再生子 Agent,用 prompt 硬約束防爆炸。
- 只讀並行,寫入串行 — 最務實的 multi-agent 並行策略。
51 萬行程式碼。1,903 個檔案。18 個安全檔案只為一個 Bash 工具。9 層審查只為讓 AI 安全地幫你敲一行指令。
AI Agent 的 90% 工作量在「AI」之外。 不是模型夠不夠聰明,是你的鷹架夠不夠結實。
這些不是只有 Anthropic 才能做的事。思路擺在這裡了,剩下的就是動手——然後接受你可能需要比想像中多很多的鷹架。
有進展再跟大家分享。